快速开始
准备代码,创建环境
# 下载代码 git clone git@github.com:pengxiao-song/LaWGPT.git cd LaWGPT # 创建环境 conda create -n lawgpt python=3.10 -y conda activate lawgpt pip install -r requirements.txt
启动 web ui(可选,易于调节参数)
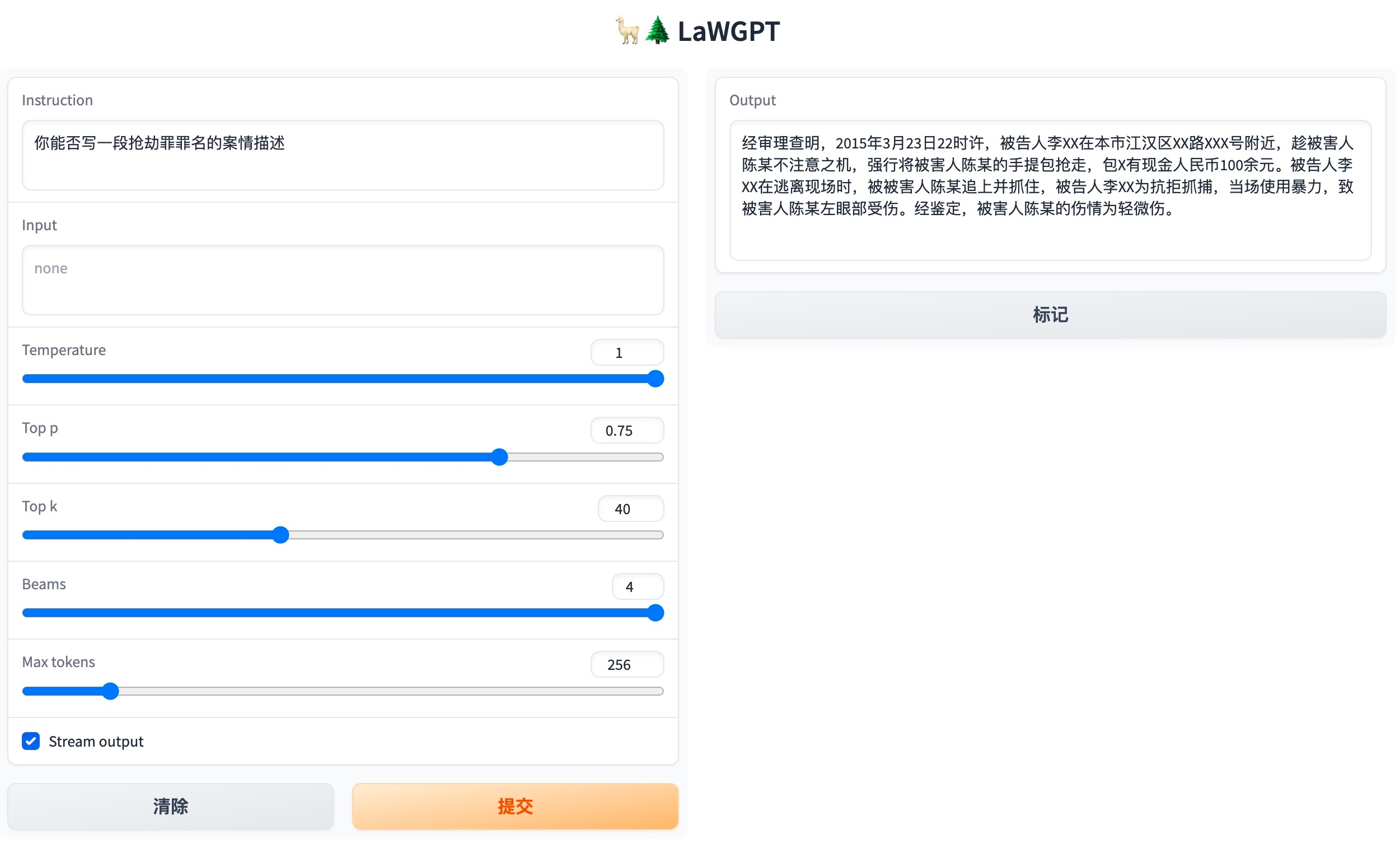
首先,执行服务启动脚本:
bash scripts/webui.sh其次,访问 http://127.0.0.1:7860 :
命令行推理(可选,支持批量测试)
首先,参考
resources/example_infer_data.json文件内容构造测试样本集;其次,执行推理脚本:
bash scripts/infer.sh。其中--infer_data_path参数为测试样本集路径,如果为空或者路径出错,则以交互模式运行。
注意,以上步骤的默认模型为 LaWGPT-7B-alpha ,如果您想使用 LaWGPT-7B-beta1.0 模型:
由于 LLaMA 和 Chinese-LLaMA 均未开源模型权重。根据相应开源许可,本项目只能发布 LoRA 权重,无法发布完整的模型权重,请各位谅解。
本项目给出合并方式,请各位获取原版权重后自行重构模型。
项目结构
LaWGPT ├── assets # 静态资源 ├── resources # 项目资源 ├── models # 基座模型及 lora 权重 │ ├── base_models │ └── lora_weights ├── outputs # 指令微调的输出权重 ├── data # 实验数据 ├── scripts # 脚本目录 │ ├── finetune.sh # 指令微调脚本 │ └── webui.sh # 启动服务脚本 ├── templates # prompt 模板 ├── tools # 工具包 ├── utils ├── train_clm.py # 二次训练 ├── finetune.py # 指令微调 ├── webui.py # 启动服务 ├── README.md └── requirements.txt
数据构建
本项目基于中文裁判文书网公开法律文书数据、司法考试数据等数据集展开,详情参考中文法律数据源汇总(Awesome Chinese Legal Resources)。
初级数据生成:根据 Stanford_alpaca和 self-instruct方式生成对话问答数据
知识引导的数据生成:通过 Knowledge-based Self-Instruct 方式基于中文法律结构化知识生成数据。
引入 ChatGPT 清洗数据,辅助构造高质量数据集。
模型训练
LawGPT 系列模型的训练过程分为两个阶段:
第一阶段:扩充法律领域词表,在大规模法律文书及法典数据上预训练 Chinese-LLaMA
第二阶段:构造法律领域对话问答数据集,在预训练模型基础上指令精调
二次训练流程
参考
resources/example_instruction_train.json构造二次训练数据集运行
scripts/train_clm.sh
指令精调步骤
参考
resources/example_instruction_tune.json构造指令微调数据集运行
scripts/finetune.sh
计算资源
8 张 Tesla V100-SXM2-32GB :二次训练阶段耗时约 24h / epoch,微调阶段耗时约 12h / epoch


上篇:
零一万物Yi-34B-Chat 微调模型及量化版开源
下篇:
中学教师用KIMI制作PPT:让你工作效率大提升,不再加班熬夜
1 开源版"AI制片厂"来了:12条流水线、一个人也能做专业视频... 2 搞定女生的终极秘籍:不是讨好,是敢于“冒犯” 3 财务知识——用AI赚钱的方法 4 十大互联网赚钱项目 5 信息差搬砖:用AI把小红书火帖变“付费文档”,日入500+ 6 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 7 2025年AI大模型六大行业风口 8 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 9 大模型无非就这点东西 10 不想上班,居家可以做的10份工作(附上方法) 11 controlnet-canny, controlnet-depth 场景介... 12 AI推理: 引导尺度, 采样步数, 采样偏移