公司简介
钱大妈是在社区生鲜连锁中,以"不卖隔夜肉"作为品牌理念的的行业开拓者。在成立之初即从新鲜角度重新梳理传统生鲜行业的标准,对肉菜市场进行新的定义。通过尝试和验证"日清"模式,以及"定时打折"清货机制,坚定落实不隔夜销售。
截至2021年5月,钱大妈已全国布局近30座城市,门店总数突破3000家+,服务家庭超1000万+,经营蔬菜、水产、水果、猪肉类、肉类(非猪肉)、蛋奶、加工食品、综合标品八大生鲜品类,逾500种优质产品。 而"不卖隔夜肉"的理念,回归最朴素的目的:让消费者能买到新鲜的食物。践行这一理念,除了依赖强大的供应链系统,更离不开科学技术和数字化建设的支持。
项目背景
钱大妈全渠道数据中台主要承载交易侧数据,贴近业务一线为业务赋能。现数据中台已为3000家+门店提供在线数据服务,支撑各部门运营、业务人员在智慧中台进行数据分析、挖掘数据背后的业务价值,并作为钱大妈首个支持实时计算、首个完成数据埋点的团队,从数据驱动业务理念为出发点,为钱大妈业务发展保驾护航。
而项目初期,在极端情况下只有一个产品、一个技术的人员配置情况下,一个月内背靠背完成项目初期的基础建设,包括但不限于:数仓规划、技术架构、维度建模、数据指标、数据开发等一系列工作,那么我们团队是如何在有限的人力资源下进行破局的呢?下面请听我娓娓道来。
数据中台建设
架构和中间件的选型,影响数据中台建设过程中后续的开发流程和运维复杂度,而目前开源的大数据组件可谓是遍地开花,每个组件都各有特色,但是它们在大数据的体系化方面又各有各的玩法。
琳琅满目的大数据组件组合方案:
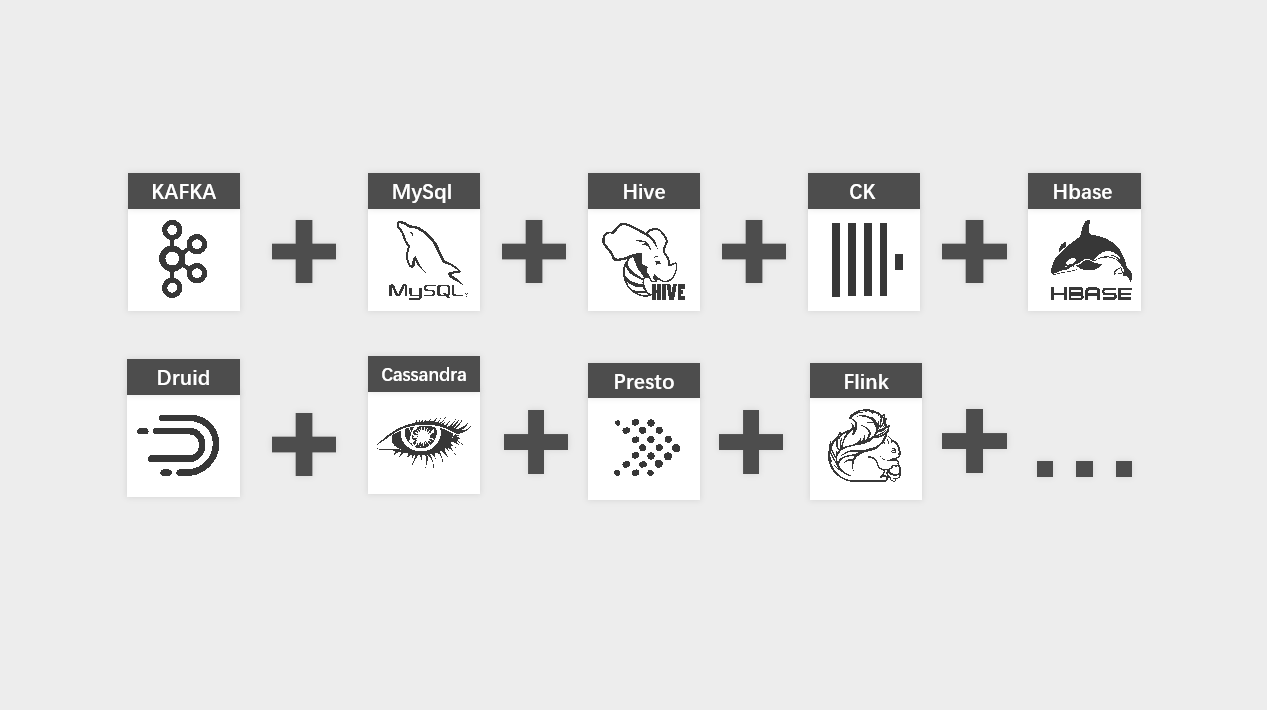
本着以业务为导向的原则,我们希望整个架构易于运维管理,功能性尽可能统一,以便将更多的精力和时间用在业务思考和数据赋能的应用上。
我们的硬需求:离线计算引擎,实时计算引擎,OLAP数据库,KV数据库,数据集成组件,分布式存储系统
我们的软需求:计算资源可弹性调整、易于运维且组件链路尽可能短、批流统一
在项目前期投入人力有限,业务急需在短期内上线的背景下,综合考虑成本和系统架构的兼容性和扩展性,我们团队认为基于云原生的全托管大数据解决方案:DataWorks+Maxcompute+Hologres+Flink比较适合我们。
以下是各个组件的定位:
DataWorks:数据的集成、开发、运维、服务等的一站式管理平台
Maxcompute:离线分布式计算引擎
Hologres:查询性能快、支持在线OLAP、KV点查、实时读写
Flink:高性能实时计算系统
钱大妈数据中台架构 V1.0
产品选型确定好之后,开始建设数据中台V1.0,主要应用在业务接口加速查询场景。以下为数据中台V1.0架构图:
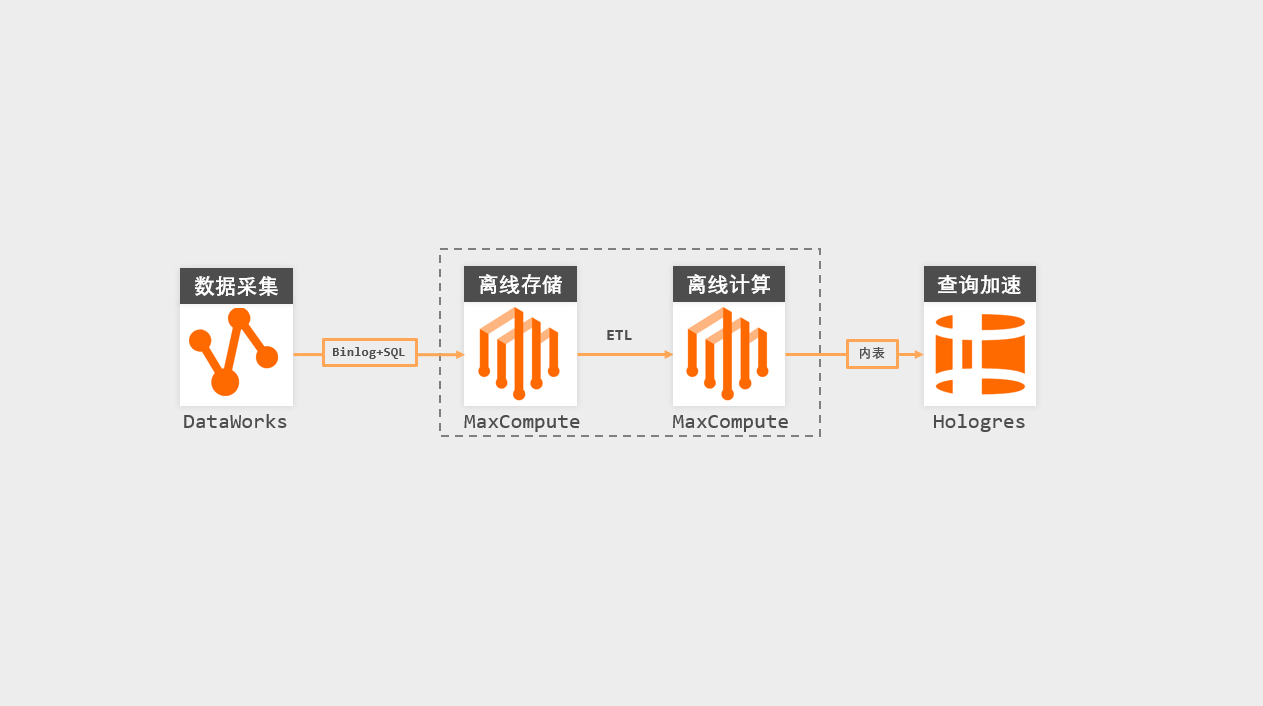
当确定了架构和中间件后,从云组件开通到VPC网连通一天内就可以完成,让项目组可以快速地投入项目初期的业务数据集成接入和数据分域建模工作。这两项大工程,我们都可以在Dataworks的对应模块上完成。
在数据接入过程中,我们不需要部署诸如Kafka+Canal组件来完成业务数据库的Binlog订阅和部署AirFlow等组件来负责任务调度管理,通过DataWorks的数据集成模块,即可将业务数据"一键"实时和离线同步到Maxcompute和Hologres。
在DataWorks的数据建模功能上,我们通过建模语言:基于Kimball维度建模范式下梳理业务板块、业务过程,并进行数据分域、维表事实表定义等数据建模操作,并用FML(Fast Modeling Language)建模语言将逻辑模型落实到物理模型。
在业务接口查询加速场景上,我们通过将MaxCompute的数据离线调度至Hologres内表以获得更快的查询体验,由于两者底层数据无缝连接,所以同步速度也是比较快的,10万级别的数据只需1秒即可完成(100,000/s)。
选择Hologres作为在线业务支持的重要一环,是因为:
安全:接入RAM鉴权,权限管理方便和安全。
索引丰富:根据不同的查询场景,选择不同的存储模式(行存或列存),提供专属的索引支持。
少数据冗余:在一个系统内满足 KV 和 OLAP 两个场景,减少跨系统带来的数据冗余。
钱大妈数据中台架构 V2.0
在数据中台V2.0建设上,我们的架构分阶段先后实现了纯离线、离线-实时的Lambda架构迭代。如下图所示:
同步:利用DataWorks的数据集成功能,实时订阅同一份Binlog日志,双写到Hologres和MaxCompute两个系统。
离线链路:对于时效性不敏感且计算复杂的场景:如用户画像、人货场标签体系、促销效果复盘等,依然通过MaxCompute进行离线ETL计算生成,最后汇集到Hologres做查询加速。
实时链路:对于实时性要求高的场景:如实时看板、风控感知、规则报警等场景,通过Hologres+Flink组合实现。
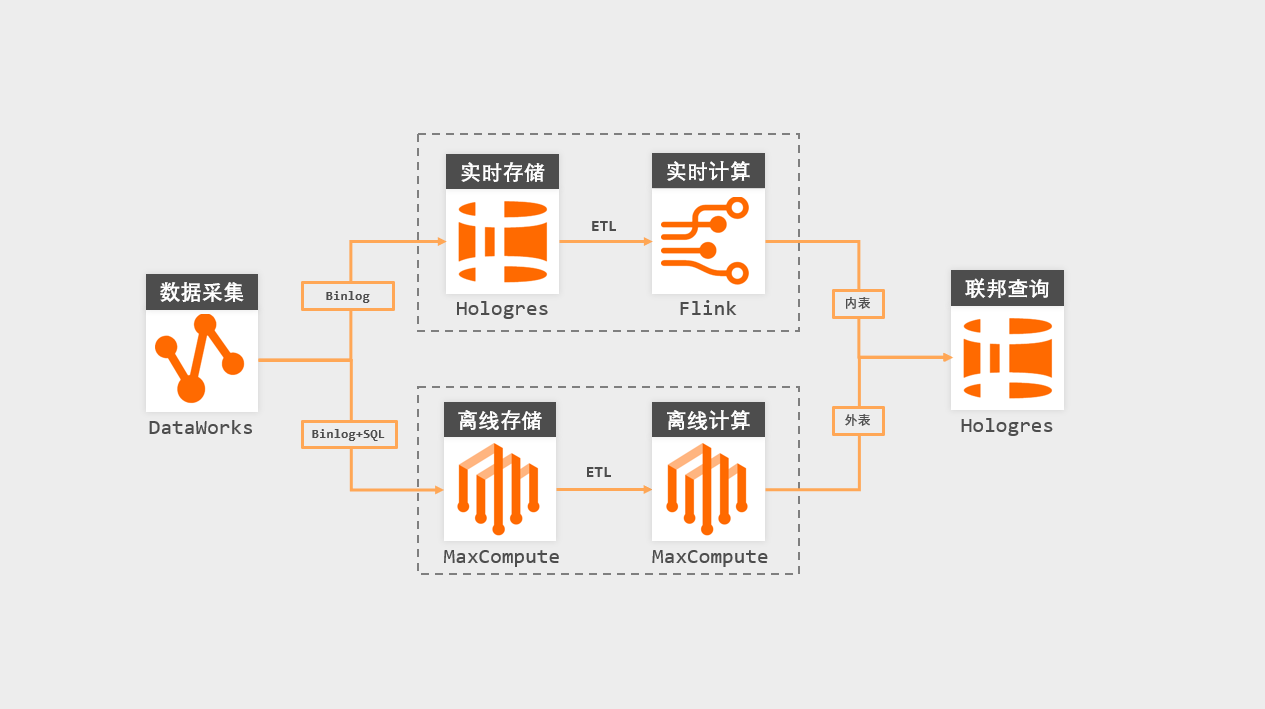
值得留意的是,在数据中台V2.0版本,我们只是新增了一个实时计算引擎(Flink),就扩展出了一条新的实时链路:Hologres(source)-> Flink -> Hologres(Sink)。这得益于这两个组件的原生适配:
Flink实时计算引擎原生支持Hologres的Connector,兼容性好,读写方便
Hologres支持主键(Primary Key,PK),能保证Flink端对端场景中的精确一致性(Exactly Once)
Hologres采用LSM架构,支持实时更新 ,细粒度更新
Lambda架构下经常面临的一个问题点就是实时和离线的计算结果如何联邦计算,Hologres的内表和外表结合的特性从设计层面就为我们解决了这个问题:实时计算的结果存储在内表,离线计算的结果存储在MaxCompute上,通过外表进行访问,由于Hologres在底层和MaxCompute数据无逢连接,方便联通离线和实时数据。
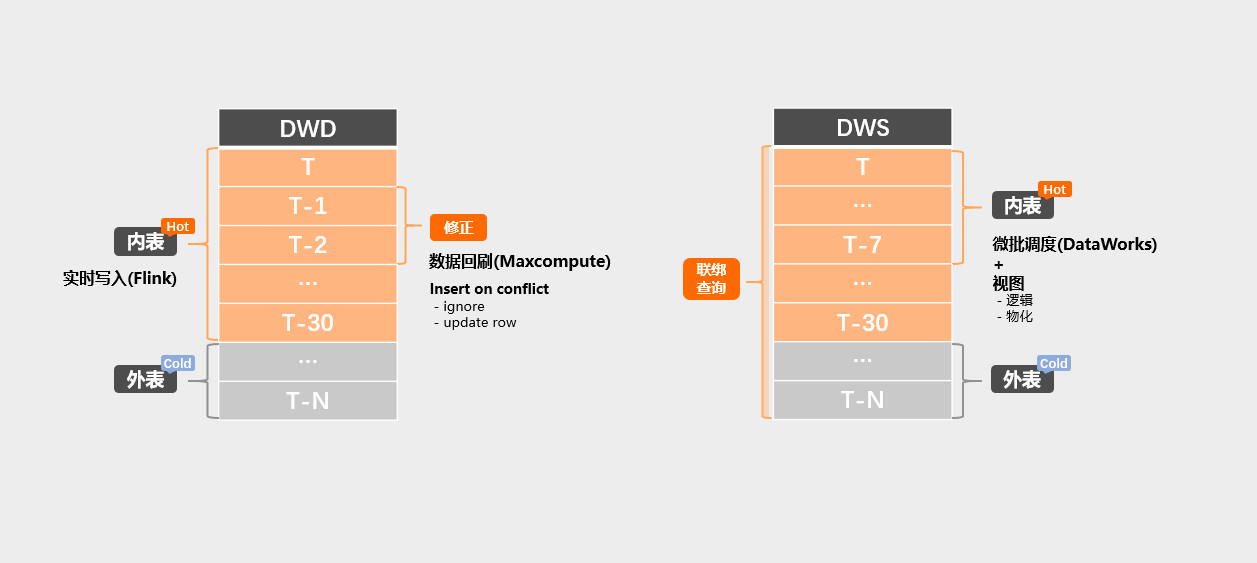
在数据中台V1.0纯离线的架构版本,我们更多的是通过离线ETL加工,将ADS层的结果集推到Hologres作为查询的加速。但随着业务的发展,更要求我们具备实时性的DWD宽表层和准实时、甚至是实时的、主题性DWS层的数据。因此在技术上,我们基于Hologres内外表特性实现的实时打宽、冷热链路和数据回刷机制:
DWD层,实时打宽+冷热链路
如订单业务场景,业务端需要要实时获取近30天的订单变更情况,因此近30天的热数据我们用Flink实时写入Hologres内表,因为内表的优势是查询快,缺点是存储成本略高(内表存储在SSD,硬件成本高)。对于超30天的数据,通过归档或直接访问的形式访问存储在MaxCompute上的数据,做到冷热数据的分层,降低低频访问数据的存储成本。另外,利用Hologres支持PK的特性,通过"Insert on Conflict"的语义定期对实时写入的数据进行滚动补漏、数据回刷等数据兜底机制,确保数据层具备"自修复"能力,防止某些故障情况下实时写入带来的数据不一致情况。
DWS层,微批调度/逻辑视图+联绑查询
如BI场景,业务可以接受5-10分钟左右的延迟,我们通过结合微批调度和逻辑视图计算DWS层,用于支持BI数据接口和业务的即席查询。 依然是通过内外表的形式,实现数据的冷热分层。冷数据则视业务和数据量情况,决定是存储于MaxCompute通过外表访问,还是同步进Hologres内表加速查询速度。最后通过在Hologres进行查询时的合并,达到联绑查询的效果。
风控场景应用
数据中台架构V2.0目前已在钱大妈多个业务场景落地,如数据服务、数据报表、实时风控系统等,下面将如何具体应用到风控场景。
实时风控系统需要结合业务记录和埋点日志在线甄别异地支付、大笔异常订单、消费终端变更等风险事件,实时触发风险应对动作,为风控专员提供及时的数据支撑和更快速的反应能力。
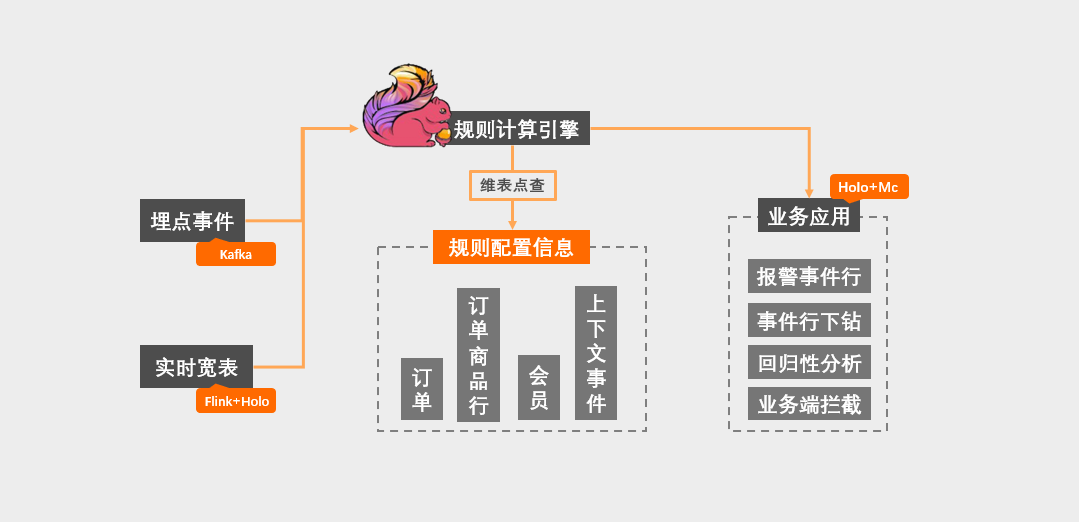
从上图可以看到,实时风控数据流的整过生命周期都会经过Hologres:数据源Binlog、实时维表点查、OLAP分析:风控全链路都由Binlog进行事件式驱动,且Hologres在开启Binlog模式下,底层提供Binlog信息查询,方便定位消费位点和复盘消费情况。在维表点查场景则可以使LRU,微批写入等优化手段进行Lookup Join性能优化。最终将结果信息实时写回Hologres提供在线分析和即席查询应用,也可以实时推到其它业务关联触达系统,进行业务端拦截、系统报警等一系列风险应对动作,以此完成整个风控场景的闭环。
业务价值
钱大妈全渠道数据中台基于阿里云大数据方案进行敏捷式的业务落地,支撑内外部多个应用场景,给业务带来的价值主要如下:
资源成本降低:零硬件资源成本,各环节支持资源弹性升缩,灵活应对各种数据高峰场景
运维成本降低:全托管式运维,减轻运维成本,让更多精力集中在业务逻辑开发
架构简单:将OLTP、OLAP 和KV三个场景集成于一个系统(Hologres),缩短中间件链路
架构生态兼容度高:Hologres与离线计算引擎(MaxCompute)、实时计算引擎(Flink)、DataWorks兼容程度高,融于云原生生态,易开发适配
期望
Hologres作为云原生体系下的一款HSAP(分析服务一体化)产品,从定位和理念上都与钱大妈全渠道数据中台的架构理念一致,希望在不久的将来能在产品侧能够支持如下特性:
资源隔离。Hologres现在资源隔离是通过不同的实例进行隔离的,希望通过例如租户的形式实现自定义的资源隔离。
分时弹性。根据业务的不同峰值时段弹性调整资源,以节省用户成本。
物化视图。截至Hologres 0.10版本,尚未支持物化视图。有了物化视图,可以一定程度上减少微批调度的场景。
内表冷热分层。现在Hologres是将冷数据存储于MaxCompute上,但是查询速度还是和内表相比存在一定的差距,希望在内表上能就实现冷热数据的分层。


上篇:
DevOps平台架构图实例
下篇:
Tensorflow学习笔记-房价预测
1 电商必懂的数据公式 2 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 3 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 4 用AI自动生成爆款文案的完整流程 5 地理空间AI应用:YOLO vs. SAM 6 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 7 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 8 5分钟一键生成软著申请材料,coze工作流全教程,含提示词 9 Vaex :十亿行每秒的 Python 大数据神器,探索与可视化的新标杆 10 大数据安全架构设计方案 11 一天做出短剧App:我的MCP极速流 12 Deepsek和AI组合打法让你的养生视频条条爆款