大家好!今天为各位关注大模型开发与应用的朋友带来一款革命性的微调工具 - Unsloth。作为一名深耕大模型应用的技术博主,之前我介绍了RAG和Agent设计,今天要分享这款极具潜力的微调工具,它支持最新的开源模型,并且效率惊人。
之所以推荐这个工具,是因为它支持最新的大部分大模型,而且给出了很多代码案例以及教程。可以一键在Colab和Kaggle中直接运行案例代码并查看结果。
网上很多的模型微调用的就是这个工具,却不给源代码,让进qun。我的建议:去官网!啥都有。
Unsloth:微调的游戏规则改变者
Unsloth让微调大型语言模型的速度提高2倍,内存使用量减少70%,而且不会降低模型精度!这对于希望定制大模型但受硬件限制的开发者来说,是一个重大突破。
核心优势:
2倍速度提升:训练时间减半,迭代更快
减少70%内存占用:让普通GPU也能驾驭大模型微调
精度零损失:优化性能的同时保持结果质量
支持最新模型:覆盖几乎所有主流开源模型
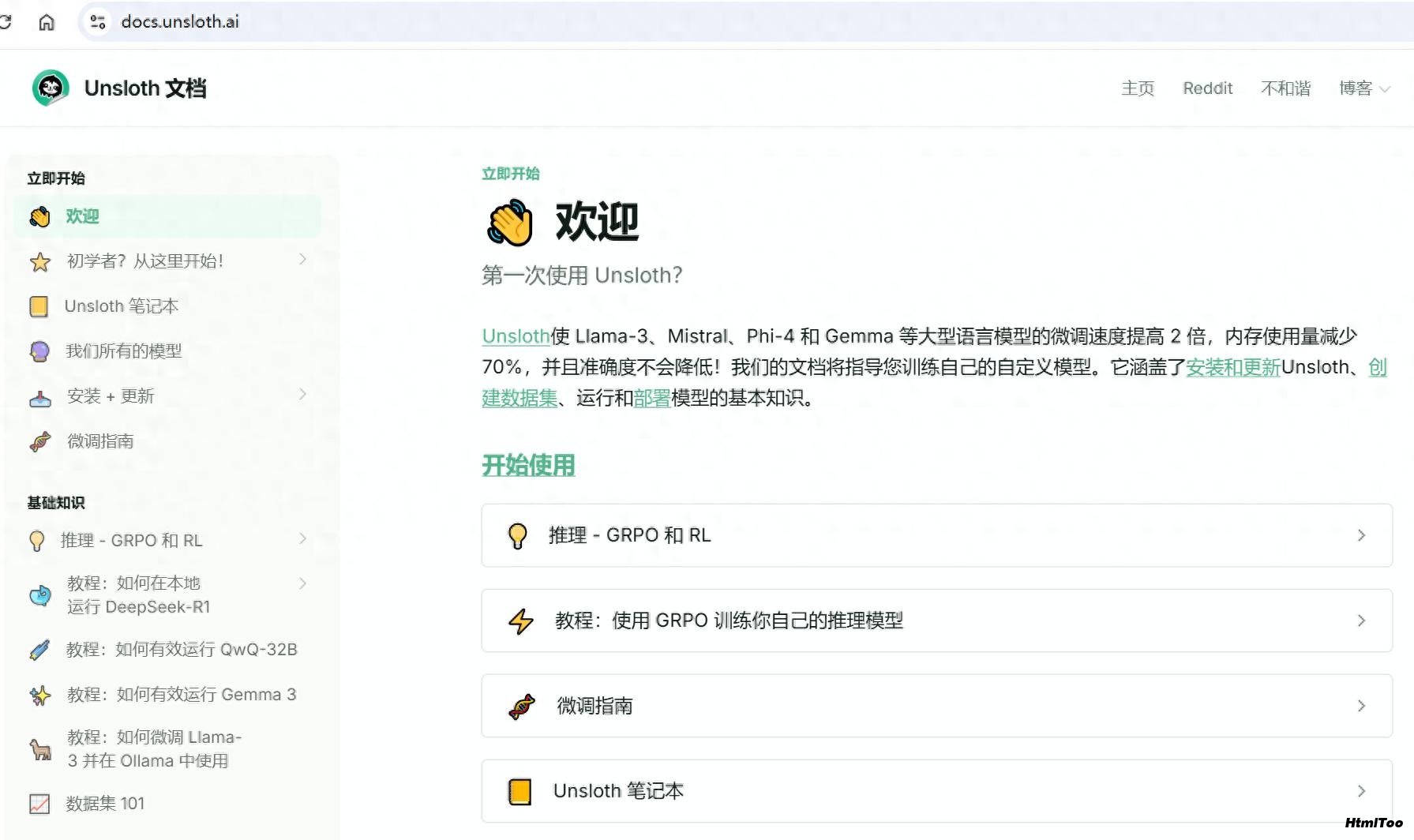
支持的模型全景图
Unsloth支持的模型范围极其广泛,几乎囊括了当前所有主流开源大模型。以下是部分亮点:
最新支持模型
Gemma 3系列:完整支持1B、4B、12B和27B等全系列参数规模
DeepSeek-R1:支持R1和R1 Zero等推理增强模型
Phi-4:支持Phi-4和Phi-4-mini版本
QwQ-32B:支持新发布的32B参数模型
大型模型支持
Llama 3.1/3.2/3.3:支持从8B到惊人的405B全系列
Mistral系列:包括最新的Small 2501 (24B)和各种Mixtral变体
Qwen 2.5系列:从0.5B到72B的全系列模型,包括特殊版本如Qwen2.5-VL和Qwen 2.5 Coder
专业模型支持
多模态模型:Llava、Qwen2.5-VL等视觉语言模型
代码模型:CodeLlama、Qwen 2.5 Coder等专业编程模型
轻量级模型:SmolLM2、TinyLlama等适合边缘设备的模型
微调vs.RAG:不是二选一,而是互补
很多朋友之前看过我写的RAG技术介绍,可能会问:"我已经用RAG实现了知识库查询,还需要微调吗?"
答案是:二者各有优势,最佳实践是结合使用。微调可以将知识直接注入模型参数,而RAG则提供最新外部信息。结合使用能实现:
领域专业性:微调让模型成为特定领域专家
更好的适应性:即使检索失败,微调模型也能给出有用回答
更高效率:微调提供基础知识,RAG处理动态变化的细节
GRPO:推理能力的飞跃
Unsloth最令人兴奋的特性之一是支持GRPO(Group Relative Policy Optimization)技术,这是DeepSeek开发用于训练R1推理模型的强化学习技术。
什么是GRPO?
GRPO是一种不需要价值函数模型的强化学习技术,相比PPO(Proximal Policy Optimization)能够大幅降低内存和计算成本。
Unsloth的GRPO优势
低资源要求:只需5GB显存就能训练推理模型(1.5B参数以下的模型)
大模型支持:用15GB显存就能将17B参数以下的模型转换为推理模型
VRAM优化:在处理20K上下文长度时,Unsloth使用的VRAM比标准实现少90%
官方提供的GRPO笔记本
Unsloth官方提供了三个现成的GRPO训练笔记本,而且详细介绍了如何使用:
Llama 3.1 (8B)
Phi-4 (14B)
Qwen2.5 (3B)
https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-GRPO.ipynb https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Phi_4_(14B)-GRPO.ipynb https://colab.research.google.com/drive/1SwLYJbi7UqSc1o8lkZ262vfJlaT7w1Ih
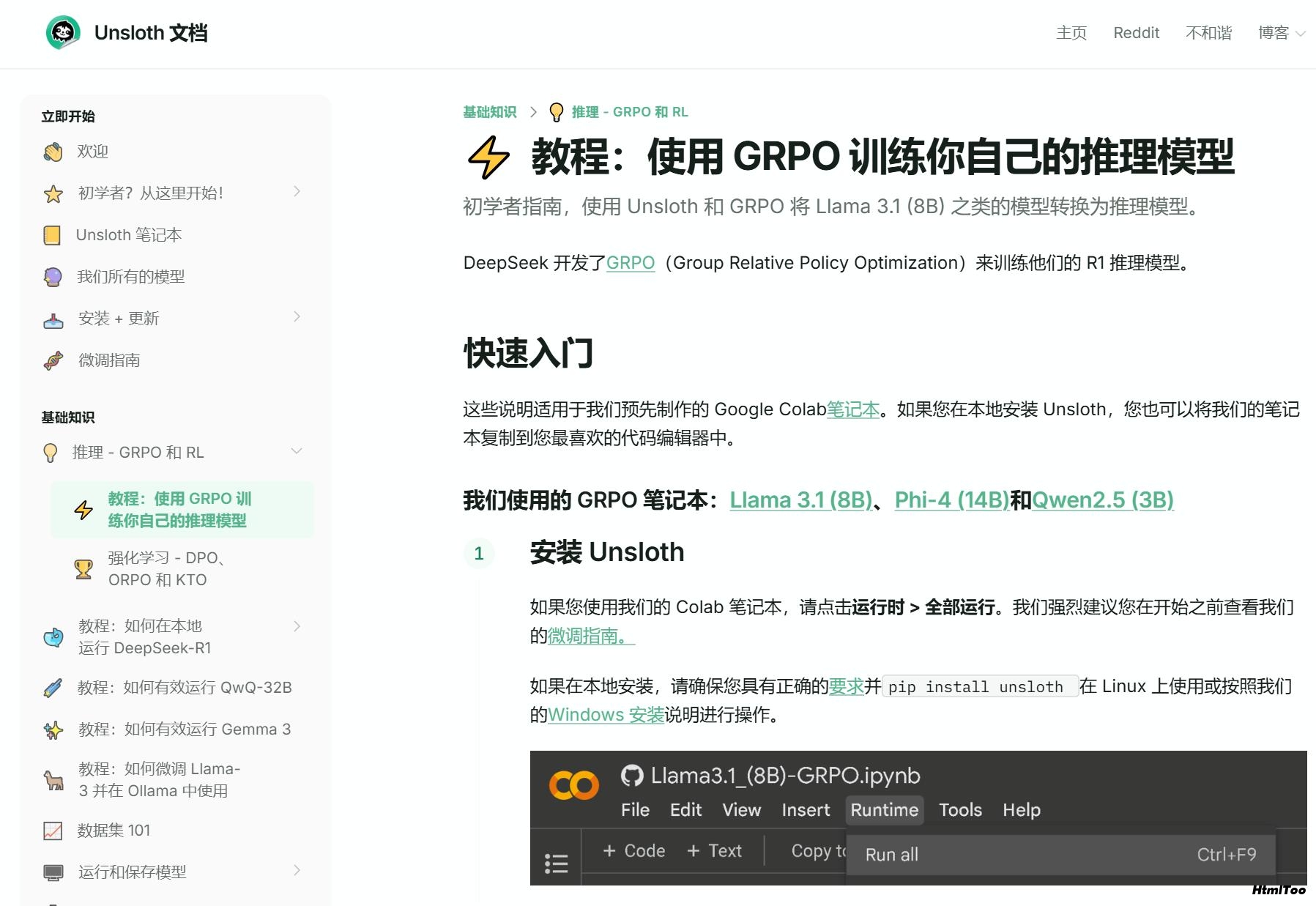
这些笔记本让你可以轻松将普通模型转变为具有强大推理能力的版本,类似于DeepSeek-R1的能力。
快速上手指南
安装Unsloth非常简单:
pip install unsloth
微调过程主要包括几个关键步骤:
选择合适的基础模型:建议初学者从Llama 3.1 (8B)开始
案例代码在这
https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-GRPO.ipynb
准备数据集:问答对是最佳格式,确保高质量的训练数据
设置训练参数:学习率、训练轮次等(Unsloth已预设合理参数)
开始训练:使用QLoRA技术,即使普通GPU也能完成
评估与调整:根据实际效果微调参数
避坑指南
在微调过程中,有几个常见的误区需要避免:
过拟合问题
如果模型只是记住了训练数据,无法应对新问题,可以:
降低学习率
减少训练轮次(通常1-3轮足够)
与通用数据集结合
欠拟合问题
如果模型未能有效学习,可以:
增加学习率
延长训练时间
使用更相关的领域数据集
结语
Unsloth提供了一个极其强大且易用的微调框架,支持几乎所有主流开源大模型,并将微调所需的硬件要求降到了前所未有的低水平。无论你是对哪种模型感兴趣,Unsloth都能提供支持。
强烈建议直接访问官方文档学习,文档详细且配有完整源代码,用浏览器翻译即可轻松理解。


上篇:
ImagePrompt:一款 AI 图片提示词工具,使用图片
下篇:
7大热门Agent框架盘点:助你轻松构建多智能体AI应用
1 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 2 2026年人工智能领域,这些岗位急需大量人才 3 2026 年 AI 创业全景指南:给渴望借 AI 逐梦的人! 4 人工智能 AI 在电商全链条的12个主要应用场景 5 信息差搬砖:用AI把小红书火帖变“付费文档”,日入500+ 6 地理空间AI应用:YOLO vs. SAM 7 AI应用快速原型开发:FastAPI + htmx ——无需React,为了快 8 剖析Mini-SGLang,打开LLM推理引擎的黑盒世界 9 快到2026啦 必须掌握的AI智能体全栈技术! 10 2025年AI大模型六大行业风口 11 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 12 谁敢信!用豆包生成8篇小说全部过签了