携程PB级数据基础平台2.0建设,多机房架构下的演进
一、背景
携程数据基础平台主要组件包括:HDFS 分布式存储集群,YARN 计算集群,Spark、Hive 计算引擎。数据基础平台 1.0 版本的架构从 2017 年开始逐步成型,2018 年至 2021 年数据基础团队基于 1.0 的架构做了性能优化和各类 Bug 修复,支撑集群数据和计算任务高速增长。
进入 2023 年以来,随着业务恢复,数据平台存量数据也不断增长,单日数据量净增长超过数 PB,增速前所未见,2 个 IDC 的数据机房物理机架位告急。
在 OPS 团队的大力支持下,启动了第三个 IDC 数据机房建设项目,2 个月内交付了新 IDC。
二、面临的问题
随着集群规模不断增长,2022-2023 年亟待解决的基础平台几大痛点:
多机房架构支持三数据中心架构,数据存储和计算调度
数据迅速增长、机房需要建设周期,冷数据搬迁上云上对象存储可以有效缓解整体存储容量压力,降低综合成本
数据量增长导致算力资源缺乏,需扩大离线在线混部资源规模且能实时互相借调
计算引擎 Spark2 需要平滑升级 Spark3
三、整体架构
在 2022-2023 年持续演进过程中,数据平台 2.0 整体架构如下图所示。存储层支持多机房架构, 热/温/冷三分层数据,透明迁移,并且具备读取缓存,透明加速的能力。调度层支持灵活的优先级调度,NodeManager 节点混部,离线和在线节点混部,还引入了 Celeborn 作为新的 Shuffle service。引擎层从 Spark2 升级到 Spark3,使用 Kyuubi 作为 Spark 的查询入口。
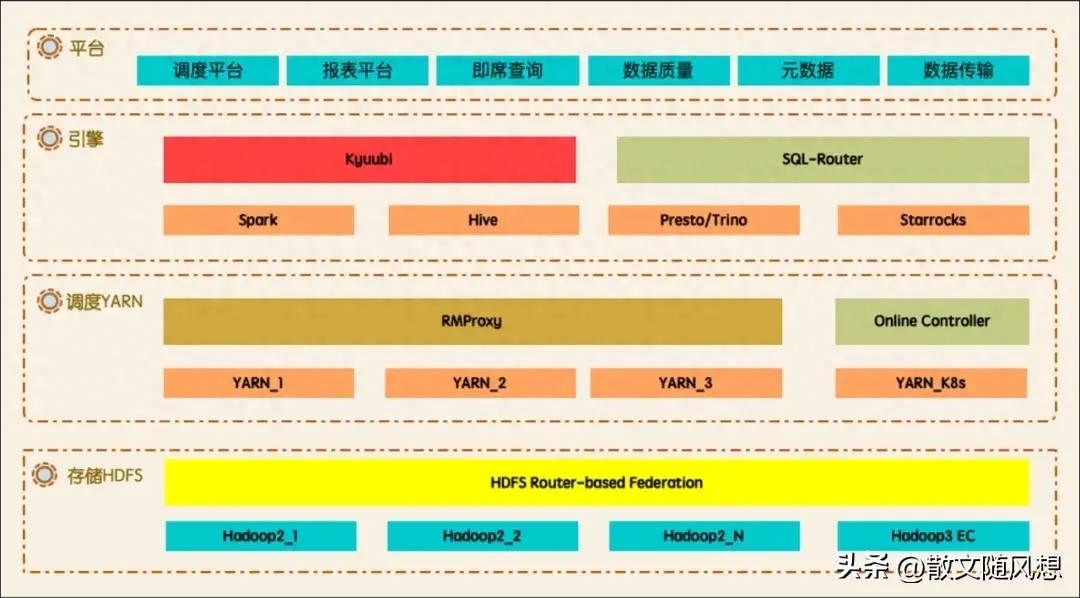
四、存储
1、多机房架构升级:支撑三个以上数据中心架构
Hadoop 多机房架构升级,数据支持按 IDC 或者跨多个 IDC 共享,Client 支持就近读写,避免产生跨机房流量,新增数据中心对使用数据平台的用户无感知。
2、分层存储:热/温/冷三分层数据存储架构落地,对接云上对象冷归档存储,降低存储成本
存储和计算引擎多方联动升级改造:支持热/温/冷分层,热数据放私有云热节点,温数据放私有云 Erasure Coding (EC) 冷节点,冷数据周期性搬迁至云上对象存储的超冷归档存储。
3、透明迁移
HDFS 原生支持的多个迁移工具,在迁移过程对用户来说完全透明。
Balancer - 平衡不同的 DataNode 数据分布
Mover - 迁移数据到期望的存储类型的 DataNode,比如迁移在 DISK 类型的数据到 ARCHIVE 类型的 DataNode
Disk Balancer - 平衡同一个 DataNode 不同磁盘的数据分布
但是在 HDFS Router-based Federation (RBF) 的架构下,因为单组 NameNode 存储的文件数有上限,又或者因为 RPC 导致 NameNode 响应慢,通常的做法是增加一组或者多组 NameNode,并把不同的部门的数据拆分到不同的 Namespace,所以经常会有跨 HDFS 集群 Namespace 迁移。
或者是因为新增 IDC,需要将某个部门的数据和计算任务都迁移到新的 IDC,以缓解数据和计算能力的不足。
又或者存储的数据转换成 Erasure Coding 编码的数据,以节约数据存储成本。
这里涉及到多种数据迁移,是原生的 HDFS 迁移工具不支持的,怎么做成对用户较为透明的迁移?
对于新增数据,可以利用 RBF 的 Mount Table 特性,让新增的数据指向新的 Namespace,旧的数据可以逐步迁移,或者随着 Time to live (TTL) 旧的数据自动删除,不需要迁移。但是如果存在跨目录的 rename 操作,可能不太适用。
对于全量数据,基于 FaceBook 开源版本的单机版 FastCopy,在 DistCp 的基础上扩展了分布式的 FastCopy 的方案,并修复和支持多个开源版的问题,比如不支持非 DISK 类型的 DataNode 的 FastCopy,addBlock RPC 的重试导致 missing block。FastCopy 的原理是选择对源文件的 Block 对应的多个 DataNode 执行 Hard link,并汇报到新的集群,以达到快速迁移 HDFS 集群元数据,但是不需要复制 Block 数据的目的。
跨机房的数据迁移,实现跨机房副本分布配置,支持路径的数据可以按单机房或者多机房策略放置,实现 Client 可以就近读和写,对用户无感。
转 EC 编码,实现数据迁移工具,通过配置近多少天读取次数小于 X 次的规则,实现自动化的迁移。迁移完成后切换 RBF 的 Mount Table,Client 就可以直接读取 EC 编码的数据,并且支持静态分区,动态分区的历史分区数据回刷。
4、读取透明加速
存储在 HDFS 集群的数据大多数是一次写入多次读取,由于 HDFS 本身提供的 HDFS 集中式缓存管理 (Centralized Cache Management) 功能较有限,所以引入了 Alluxio 组件,基于社区版实现了透明 URI 访问,多 IDC 自动选 master,单集群多租户等功能,无需更改 Location,与计算引擎集成打通,用户可以直接透明使用缓存读取功能。
五、调度
1、优先级调度
与 ETL 作业调度,元数据管理平台打通,基于表的重要等级自动提升任务链路的优先级,对 P0,P1,PX 任务分类,在 YARN 调度器实现优先级调度,保证任务 SLA。
2、NodeManager 节点混部
在白天业务低峰的时候,集群会临时下线部分 NodeManager 节点,切换成 Presto,Trino,StarRocks 的计算节点,以应对白天较多的 Ad-Hoc 查询及报表查询。
这带来几个问题,下线 NodeManager 需要快速清理已调度的 Container,但是 Spark 或者 MapReduce 依赖的 Shuffle service 可能会因为 NodeManager 停止服务而无法拉取 Shuffle data,导致计算任务的 Task 局部失败并重试,拉长任务整体完成时间。
对此,实现了临时下线 NodeManager 时,仍然保留了 Shuffle service 的服务线程和端口,这样保证了 Shuffle 过程不失败。并且对 P0,P1 重要的任务则实现了 NodeManager 混部节点黑名单机制,保证重要作业申请的 Container 资源不会调度到这些混部的计算节点,防止 Task 在下线的过程中运行失败。
3、离线和在线节点混部
在线服务应用的资源使用情况随着终端用户的访问数量而变化,不少应用存在夜间 CPU 利用率较低,具备潮汐特性,而数据计算任务通常都在凌晨有较高的资源需求,YARN 集群经常出现 App 或者 Container pending 等资源不足的问题。
通过对离线作业 Spark、MapReduce 和 Kyuubi Spark Engine 的画像分析,收集读取,Shuffle,写入等作业指标,区分任务优先级,与 ETL 作业调度平台联动,提交到在线集群基于 K8s 部署的的 YARN 集群,并通过 YARN Node Label 特性实现灵活 Container 调度。
4、Remote shuffle service Celeborn
在 Spark on YARN 的方案,开启 Spark 动态资源分配时,往往需要在 NodeManager 部署 Spark External Shuffle Service (ESS),在 Executor 闲置回收之后提供 Shuffle 数据的读取服务。
ESS 虽然经过一系列优化,比如 Shuffle write 结束合并成一个大文件,以避免在 NM 创建大量的小文件,但是仍然无法避免几个问题。Shuffle read 存在大量的随机读,NM 有大量的磁盘 IOWait,导致 FetchFailed,进而 Stage 需要重新计算。并且一次 Shuffle read 会创建 M*N 次的连接数,当 MapTask 和 Shuffle partition 较大规模时,作业经常因为 Connection Timeout 或者 Reset 而触发 FetchFailed。
在 Spark on K8s 的方案,目前还不支持 External Shuffle Service,所以目前要想在K8s 开启 Spark 动态资源分配,只能开启
spark.dynamicAllocation.shuffleTracking.enabled=true,这样 Executor 当没有 active 的 shuffle 数据,就可以被释放回收,整体资源释放时间被拉长。
基于上述多个问题,引入了 Remote shuffle service(RSS) Celeborn 组件,在多个 IDC 的 NodeManager 节点,混部了 Celeborn,与 Spark 引擎集成,并在 Ad-Hoc 查询平台,ETL 调度平台灰度开启。
Celeborn 服务可以解决和优化目前 ESS 存在的问题。Celeborn 优势如下:
使用 Push-Style Shuffle 代替 Pull-Style,减少 Mapper 的内存压力
支持 IO 聚合,Shuffle Read 的连接数从 M*N 降到 N,同时更改随机读为顺序读
支持两副本机制,降低 Fetch Fail 概率
支持计算与存储分离架构,与计算集群分离
解决 Spark on Kubernetes 时对本地磁盘的依赖
六、计算引擎
1、Spark3
2017 年引入 Apache Spark 2.2,基于此版本做了不少定制化的开发,实现多租户的 Thrift Server,基本替代了 Hive CLI/HiveServer2 SQL,成为携程主流的 SQL 引擎,服务于 ETL 计算,Ad-Hoc 查询和报表。
在 2020 年 6 月,Spark3.0 正式发布,有强大的自适应查询执行 (Adaptive Query Execution) 功能,通过在运行时对查询执行计划进行优化,允许 Spark Planner 在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化,比如动态合并 Shuffle Partitions,动态调整 Join 策略 ,动态优化倾斜的 Join,从而提升性能。
2021 年 10 月随着 Spark 3.2 发布,开始着手调研升级的可行性,最终经过一系列的探索,移植多个 Spark2 定制需求,完成了 Spark2 到 Spark3 的平滑升级。
1)Spark3平滑升级
①使用 Kyuubi plan only mode 重放线上 SQL,分类语法不兼容的类型
Kyuubi Spark Engine 设置
kyuubi.operation.plan.only.mode=OPTIMIZE,结合元数据,获取提交的 SQL 的优化之后的执行计划,可以按 SQL 错误类型归类。
②与 Hive SQL 、Hive meta store、Spark2 SQL 兼容
扩展 BasicWriteTaskStats,收集和记录非分区表、分区表(静态分区,动态分区) 多种写入类型写入的行数,文件数,数据大小 (numRows,numFiles,totalSize)。
Spark 建的视图与 Hive 兼容
在 Spark 在 USE DB 之后建的视图,会导致 Hive 读 View 失败,因为 viewExpandedText 没有完全重写,当前 DB 的信息存储在 Hive meta store 的 View 的 table properties,Hive 读取 View 对应的 Table 因为没有 USE DB 而找不到对应的表。
在 Hive 执行 DDL 修改 Spark 视图的类型定义,会导致 Spark 读取 View 失败,因为 Spark 建 View 的时候会把当前 schema 存储在 View 的 table properties 的 spark.sql.sources.schema,Spark 读取 View 时 schema 再从此属性恢复,由于 Hive 修改 View 不会同步修改这个属性,这导致 Spark 读取 Hive 修改后的 View 失败。
这里采用 Hive 的做法,重写 viewExpandedText,补全当前的 DB 信息,同时去掉存储在 table properties 的 schema,保证多个引擎可以修改,可以读取。
避免全量永久 UDF 加载
Spark 在某些模式下启动可能会从 Hive meta store 拉取所有 DB 的永久 UDF 定义,这导致 Spark 启动较慢,对 Hive meta store 负载有一定影响。需要避免直接初始化 Hive Client,这样能避免全量永久 UDF 加载。
[SPARK-37561][SQL] Avoid loading all functions when obtaining hive's DelegationToken
避免创建 0 Size 的 ORC 文件
Hive 的实现 OrcOutputFormat 在 close 方法,如果该 Task 无数据可以写,在 close 的时候会创建一个 0 size 的 ORC 文件,较低的 Hive 版本或者 Spark2 依赖的 ORC 较低版本不支持读。
虽然 ORC-162 (Handle 0 byte files as empty ORC files) 补丁可以修复此问题,但是对多个组件的低版本进行升级是一件较为困难的事,所以采取了对 Spark3 依赖的 Hive 版本进行修复,创建一个无数据空 schema 的 ORC 文件,保证灰度升级的时候,Spark3 产出的数据文件,下游 Spark,Hive 都可以正常读取该表的数据。
③移植 Spark2 自定义特性,部分 Rule 通过 SparkSessionExtensions 注入
在早期二次定制开发 Spark2 的时候,Spark2 还没有丰富的 API 接口供开发者注入自定义的实现,这导致了一些个性化的特性直接耦合在 Spark2 的源码中,这给升级 Spark3 移植特性带来诸多不便,代码散落在各个代码文件,移植的时候可能会遗漏,缺少一些端到端的测试。
在 Spark3 升级的过程中,重新梳理定制化需求,尽可能剥离出来新的代码文件,并抽离出一些 SQL Rule,包装成 Spark plugin,注入到 SparkSessionExtensions,方便后续的升级及维护。
④基于 SBT 在 GitLab 构建 CI/CD,快速集成
在二次开发 Spark 或者 backport 社区 Patch,Spark 需要一个完整的测试工作流,社区版的 CI 是基于 GitHub action 构建的,在内部的 GitLab 参考了类似的 workflow,因为 SBT 构建和测试速度比 Maven 快很多,所以基于 SBT,拆出 10+个 Module,可以并行测试,并且一旦编译通过,自动化部署对应的分支的 jar 到验证环境,供开发者进一步调试。极大提高了 Spark Merge request 合并代码的稳定性和 Code review 的效率,也使得生产环境的 Spark 更为健壮。
⑤灰度升级策略,任务粒度切换
与 ETL 调度平台联动,支持任务级别或者按任务优先级的百分比,从 Spark2 灰度切换 Spark3,失败可自动 fallback,并且有数据质量平台,每个任务完成之后,都有相应的数据校验保证,另外还有一些运行时间对比,错误监控。
2)分区过滤函数优化
查询一张数万个分区表,在 Hive 查询引擎使用函数 substr 对分区字段 d 进行过滤,它使用 Hive meta store 提供的 get_partitions_by_expr RPC 进行分区裁剪,最终 Client 只需要获取少量的符合条件的几个分区。
但是在 Spark 实现的分区裁剪,不支持函数,所以如果有 where substr(d,1,10) = '2023-01-01' 函数过滤分区的 SQL,会造成 Hive meta store 因为需要获取大量分区而导致 CPU 被打爆到 100%,并且 Client 会因为获取太多分区详情会导致 OOM 而失败。
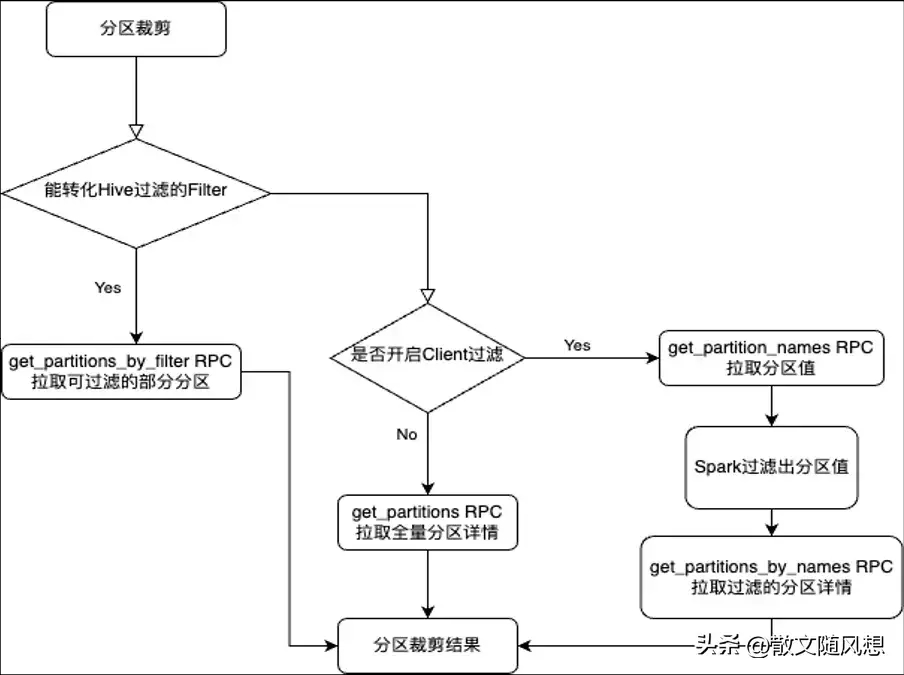
分析 Spark 关于分区裁剪的调用链路,Spark 先是把支持的算子转换成 Hive 支持过滤的 Filter SQL,如果支持转换,就直接使用 get_partitions_by_filter RPC 获取分区详情。如果不支持转换,则使用 get_partitions RPC 获取所有分区详情,再通过 Spark 的算子进行分区值的过滤,调用代价太高。
如果是借鉴 Hive 的实现,因为 Spark 的函数和 Hive 提供的函数定义不一定一样,Spark 的函数可能在 Hive 没有实现,所以 Hive 实现的 get_partitions_by_expr 在 Spark 侧不太适用。
[SPARK-33707][SQL] Support multiple types of function partition pruning on hive metastore
这里采取了另外一个思路,在不支持转换 Filter SQL 的时候,先是获取调用 get_partition_names RPC 获取分区列表,再通过 Spark 算子过滤出所需的分区值,接着调用 get_partitions_by_names RPC 获取过滤后对应的分区值的详情,调用耗时从数十分钟降到秒级别,极大的提升了分区裁剪的效率。
社区版本提供了一个配置项,需要通过
spark.sql.hive.metastorePartitionPruningFastFallback=true 打开此特性。
[SPARK-35437][SQL] Use expressions to filter Hive partitions at client side
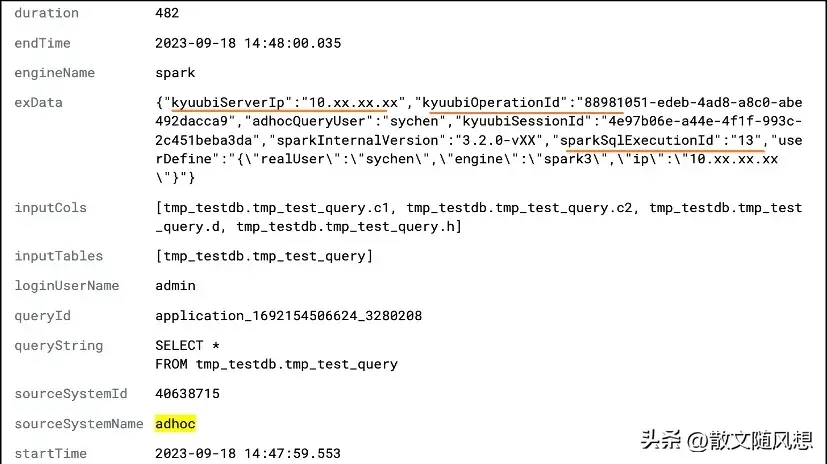
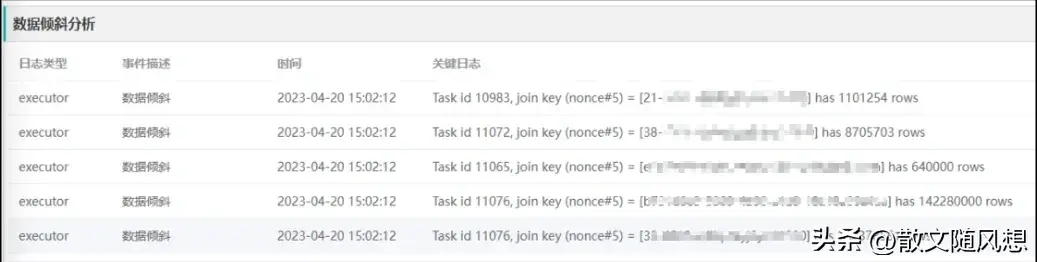
3)数据倾斜
虽然在 Spark3 AQE 可以自动优化倾斜 Join,但是在部分场景仍然存在倾斜 Key 的情况,比如 Stage 没有 Shuffle,缺少运行时统计信息,而 Skew join 需要通过统计信息计算出不同的 Partition 是否存在倾斜才可以进行优化。
首先在 Spark 实现定位数据倾斜 Key,在 SortMergeJoin 注入 JoinKeyRecorder,采集每个 Task join 的 key 的行数和最大行数的 key,类似于 Hive 的 JoinOperator 的实现。
接着在诊断平台的 Event log parser 实现相应的解析,提取 Join key 和行数,当用户诊断作业的时候,可以显示是否存在倾斜 Key 和倾斜行数。
诊断平台是基于罗盘 (compass) 开源二次开发,集成在 Spark History UI 和企业 IM 的诊断机器人,用户可以自助诊断,输入调度系统的作业 Id 或者 App Id,Bot 即可生成诊断报告。
诊断机器人
生成的诊断报告
2、Kyuubi
1)Spark2 Thrift Server
与 Hive 提供的 HiveServer2 对应的 Spark Thrift Server (STS) 是 Apache Spark 社区基于 HiveServer2 实现的一个 Thrift 服务,目标是做到无缝兼容 HiveServer2。与 HiveServer2 类似,通过 JDBC 接口提交 SQL 到 Thrift Server。
相比于 HiveServer2,Spark Thrift Server 是比较脆弱的。Spark Driver 比 Hive Driver 更为繁忙一点。Hive 负责编译和优化 SQL,提交 MapReduce Job,轮询结果,而 Spark Driver 不仅仅要做 Hive 的类似事情,还需要管理资源调度,按需增加和减少 Executors,调度 Job、Task 执行,广播变量、小表,这也导致了 Spark Driver 更容易有 OOM 的问题,当这个问题出现在 Driver 与 Server 绑定的同个进程中,问题就更为严峻,Server crash 的话可能导致多个 Session 的查询直接失败。
原生的 STS 还存在下列的问题:
Server 单点问题
不支持类似 HiveServer2 通过 Zookeeper 实现 High Availability
[SPARK-11100] HiveThriftServer HA issue,HiveThriftServer not registering with Zookeeper
不支持多个不同的用户
Thrift Server 不能以提交查询的用户取代启动 Thrift Server 的用户来执行查询语句,类似 HiveServer2 hive.server2.enable.doAs
[SPARK-5159] Thrift server does not respect hive.server2.enable.doAs=true
不支持 Cluster 模式,受限于 Driver 启动的机器的内存
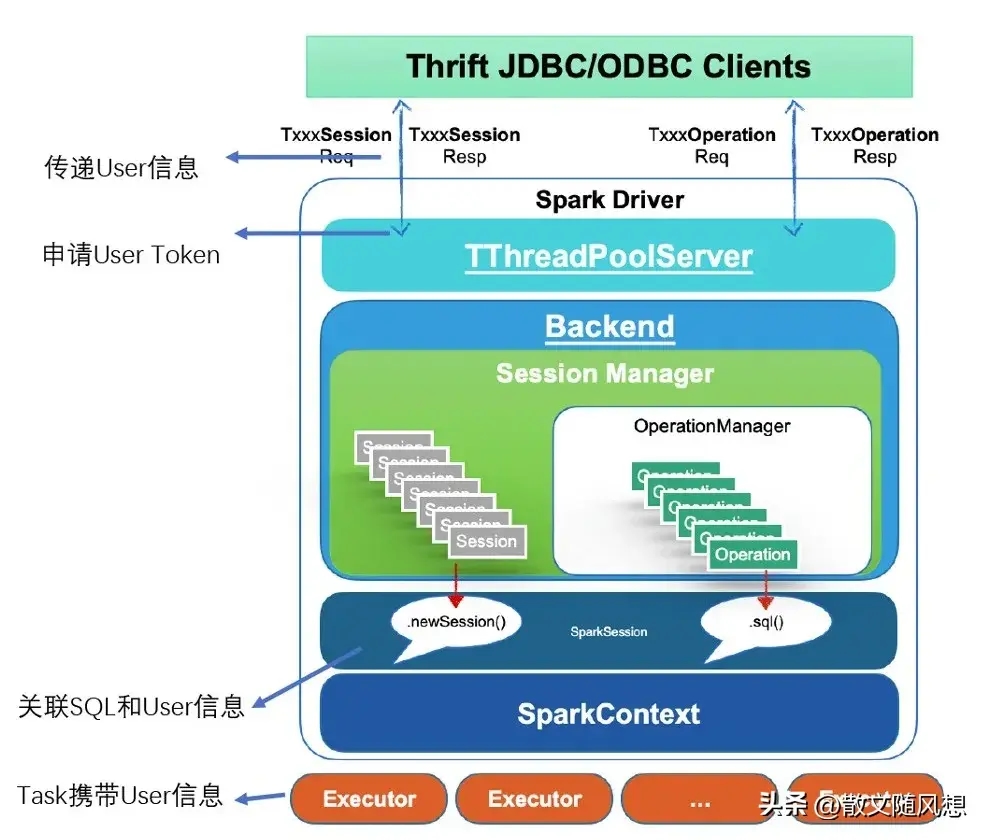
基于上述原生 Spark Thrift Server 不能够满足需求,在 Spark2 扩展了一些实现,比如支持多租户,基于 Zookeeper 实现 High Availability。
实现多租户的功能,是在 Client 发起 openSession 时,Server 在
SparkSQLSessionManager.openSession 对当前的 Session User 申请 HDFS DelegationTokens 和 Hive DelegationTokens。这一块 Token 传递和刷新和 Spark2 Streaming 更新 Token 逻辑类似。
然后在 DAGScheduler submit job 的时候关联 SQL,JobId,User 信息,并绑定到 Task。
接着在 Executor 使用 Task 对应的 UGI doAs 执行。
由于 Spark2 还有多处的实现用到了线程池,这里也需要模拟成不同的用户去执行。
BroadcastExchangeExec.executionContext 全局的线程池
UnionRDD.partitionEvalTaskSupport 全局的 ForkJoinPool
HIVE-13120: propagate doAs when generating ORC splits
这样的实现也存在了不少的局限
在 YARN 层面 App 对应的用户是超级用户,不能细粒度划分资源
Spark Jars、Files 是全局共享的,这导致了 UDF 隔离性不是很好
扩展特性对 Spark Core 、SQL、ThriftServer 模块改动较多,与 Spark 版本深度绑定
2)Kyuubi Spark3 Thrift Server
在升级 Spark3 的时候,决定废弃原有的 Spark2 的 Thrift Server 的改造实现,引入 Apache Kyuubi 项目。
Kyuubi 有如下的优点
隔离性好,支持资源队列隔离,Engine 隔离
设计天然多租户,计费友好,支持 Cluster 模式
不与 Spark 具体版本绑定,支持 N 个大小 Spark3 版本
使用 Explain 模式,可以预解析 SQL
支持 Server、Engine graceful stop
可以按不同的用户进行个性化配置
Kyuubi 的架构分为两层,一层是 Server 层,一层是 Engine 层。
Server 层和 Engine 层都有一个服务发现层,Kyuubi Server 层的服务发现层用于随机选择一个 Kyuubi Server,Kyuubi Server 对于所有用户来共享的。
Kyuubi Engine 层的服务发现层对用户来说是不可见的。它是用于 Kyuubi Server 去选择对应的用户的 Spark Engine,当一条用户的请求进来之后,它会随机选择一个 Kyuubi Server,Kyuubi Server 会去 Engine 的服务发现层选择一个 Engine。如果 Engine 不存在,它就会创建一个 Spark Engine,这个 Engine 启动之后会向 Engine 的服务发现层去注册,然后 Kyuubi Server 和 Engine 之间的再进行一个内部连接。所以说 Kyuubi Server 是所有用户共享,Kyuubi Engine 是用户之间资源隔离。
目前 Kyuubi 完全替换了原先的 Spark2 Thrift Server 服务,作为即度查询,质量校验,报表系统的 Spark 入口。
动态远程配置
基于远程配置中心,推送各种配置,按用户,用户组开启
动态分时注销 Engine
白天允许 Engine 闲置时间更长,避免冷启动 Engine 较慢
动态调度 Engine 集群
历史画像分析,使用资源较小的 Engine 允许调度到离线在线混部集群
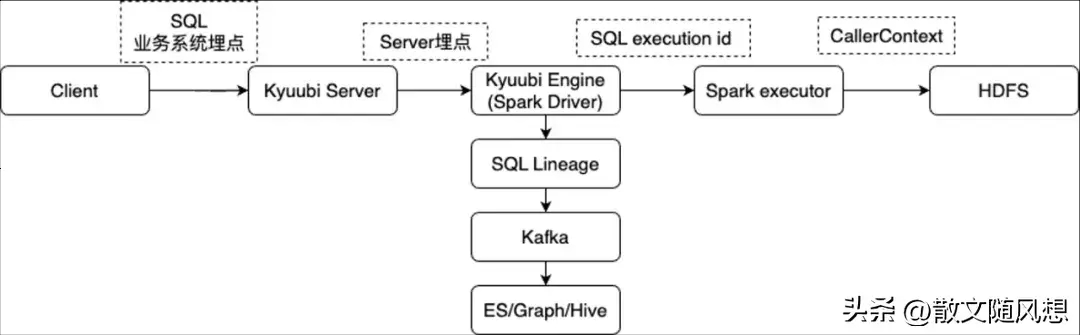
3)Kyuubi 全链路血缘跟踪
在多租户共享 Engine 的情况,如何精细化跟踪每条 SQL?对此,实现了一个全链路的血缘跟踪。
在 SQL Lineage 层面,基于
spark.sql.queryExecutionListeners 的 API 实现,采集了 Kyuubi Server/Engine IP,Session Id,Operation Id 和当前的 Spark 的 YARN Application Id,SQL 执行的 Id。
在 HDFS 的 Audit log 层面,拓展了 Spark Task 的 CallerContext 的实现,埋入 SQL 执行的 Id。
这样可以基于每条的 SQL execution id 关联整条链路,在 SQL lineage 层面可以知道哪个 session 的哪次执行读取了什么数据,写入哪张表,在 HDFS 的 Audit log,可以看到具体是哪个 SQL 对应的 ID 访问了哪些数据文件,以达到精细化追踪和运营的目的。
SQL lineage
HDFS audit log

七、总结
在多个基础组件协同联动,齐头并进,取得了如下的收益:
1、架构层面优化收益
数据基础平台 1.0 架构从 2017 年到 2022 年稳定运行 5 年,达到瓶颈,新的 2.0 架构预期在 2023 落地建设完成后,具备可扩展性,预期在近几年内可以为集团数据保驾护航,确保集团数据计算任务持续、稳定、高效运行,在数据量快速增长的情况下,多数据中心+冷数据上云的架构也将具备很高的韧性。
2、存储引擎优化收益
具备热、温、冷数据,缓存分层存储的能力,支持多数据中心存储和迁移。
3、调度引擎优化收益
优先级调度保证了 P0、P1 任务整体按时达成率,2023 年新版本离线在线混部工具开发完成后,日均借调 CPU 逻辑核心数也有数万核,用在线集群闲置资源为离线计算提速。
4、计算引擎优化收益
从 Spark2 无感升级到 Spark3,支撑日均运行超过 60 万 Spark 任务,提升运行速度约 40%
落地数据服务网关 Kyuubi,动态分时扩缩容,动态调度集群,日均超过 30 万查询量
落地 Alluxio,实现透明访问 Hive 表,自动冷热分离,部分场景下提升 30-50%读取速度
落地 Celeborn,计算引擎 Spark 集成,可支持更小粒度的离线在线混部
支持多种数据湖组件,支持多种存储类型,热数据,EC 冷数据,云上冷数据读取多种特性
未来将持续深入数据组件生态,并适时引入新的技术栈,通过不断探索和创新,致力于优化系统架构,以提升集群的稳定性和提高数据处理效率,确保系统的可靠性和性能,满足不断增长的业务需求,为用户提供更优质的服务体验。


上篇:
Apache SeaTunnel 及 Web 功能部署指南
下篇:
大数据安全架构设计方案
1 电商必懂的数据公式 2 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 3 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 4 跨境电商的疑难杂症,被1688这个AI全包了 5 用AI自动生成爆款文案的完整流程 6 地理空间AI应用:YOLO vs. SAM 7 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 8 AI应用快速原型开发:FastAPI + htmx ——无需React,为了快! 9 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 10 根据工作岗位要求, 写一份现场面试者工作自我介绍简述, 要求800字 11 5分钟一键生成软著申请材料,coze工作流全教程,含提示词 12 Vaex :十亿行每秒的 Python 大数据神器,探索与可视化的新标杆