快速对QWen2.5大模型进行微调_模型微调可视化工具-CSDN博客
前言
在当今人工智能领域,大模型(如LLaMA、[GPT]等)的微调已成为提升模型性能和适应特定任务的关键技术。LLaMA-Factory是一个强大的工具,可以帮助开发者高效地进行大模型的微调。本文将详细介绍如何使用LLaMA-Factory快速进行大模型的微调。
什么是LLaMA-Factory?
LLaMA-Factory是一个开源的[工具集],旨在简化大模型的微调过程。它提供了丰富的功能和灵活的配置选项,使得即使是初学者也能轻松地进行模型微调。LLaMA-Factory支持多种大模型架构,并且集成了数据预处理、模型训练、评估和部署等功能。
安装LLaMA-Factory
首先,你需要安装LLaMA-Factory。你可以通过以下命令使用pip进行安装:
`pip install llama-factory`
确保你的环境中已经安装了必要的依赖项,如PyTorch和Transformers。
准备数据集
[微调]大模型的第一步是准备数据集。数据集应该包含输入和输出的配对,格式可以是JSON或CSV。以下是一个简单的JSON数据集示例:
[
{"input": "你好,最近过的好吗?", "output": "我最近过得还好,谢谢关心。"},
{"input": "你有几个孩子?", "output": "我有三个儿子和一个女儿。"}
]将你的数据集保存为data.json文件。
配置微调参数
接下来,你需要配置微调参数。LLaMA-Factory提供了一个配置文件模板,你可以根据需要进行修改。以下是一个示例配置文件config.yaml:
model: name: "meta-llama/Llama-2-7b-hf" tokenizer: "meta-llama/Llama-2-7b-hf" data: train_file: "data.json" validation_file: "data.json" max_length: 512 training: output_dir: "./results" learning_rate: 2e-5 per_device_train_batch_size: 4 per_device_eval_batch_size: 4 num_train_epochs: 3 weight_decay: 0.01 evaluation_strategy: "epoch"
运行微调脚本
使用LLaMA-Factory提供的脚本进行微调。以下是一个示例脚本finetune.py:
from llama_factory import LLaMAFactory # 加载配置文件 config_path = "config.yaml" # 创建LLaMAFactory实例 factory = LLaMAFactory(config_path) # 进行微调 factory.finetune()
将上述脚本保存为finetune.py,然后运行它:
`python finetune.py`
评估和保存模型
微调完成后,你可以评估模型的性能,并保存微调后的模型。以下是一个示例脚本evaluate_and_save.py:
from llama_factory import LLaMAFactory
# 加载配置文件
config_path = "config.yaml"
# 创建LLaMAFactory实例
factory = LLaMAFactory(config_path)
# 评估模型
factory.evaluate()
# 保存模型
factory.save_model("./fine_tuned_llama")将上述脚本保存为evaluate_and_save.py,然后运行它:
`python evaluate_and_save.py`
使用微调后的模型
加载并使用微调后的模型进行推理。以下是一个示例脚本inference.py:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "./fine_tuned_llama"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "你好,最近过的好吗?"
messages = [
{"role": "system", "content": "你是一个年过七旬的男性老人,性格内向,有三个儿子,一个女儿,他们经常不在身边"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)将上述脚本保存为inference.py,然后运行它:
`python inference.py`
可视化微调大模型
运行下面命令,启动webui可视化页面:
`llamafactory-cli webui`
会自动打开如下界面
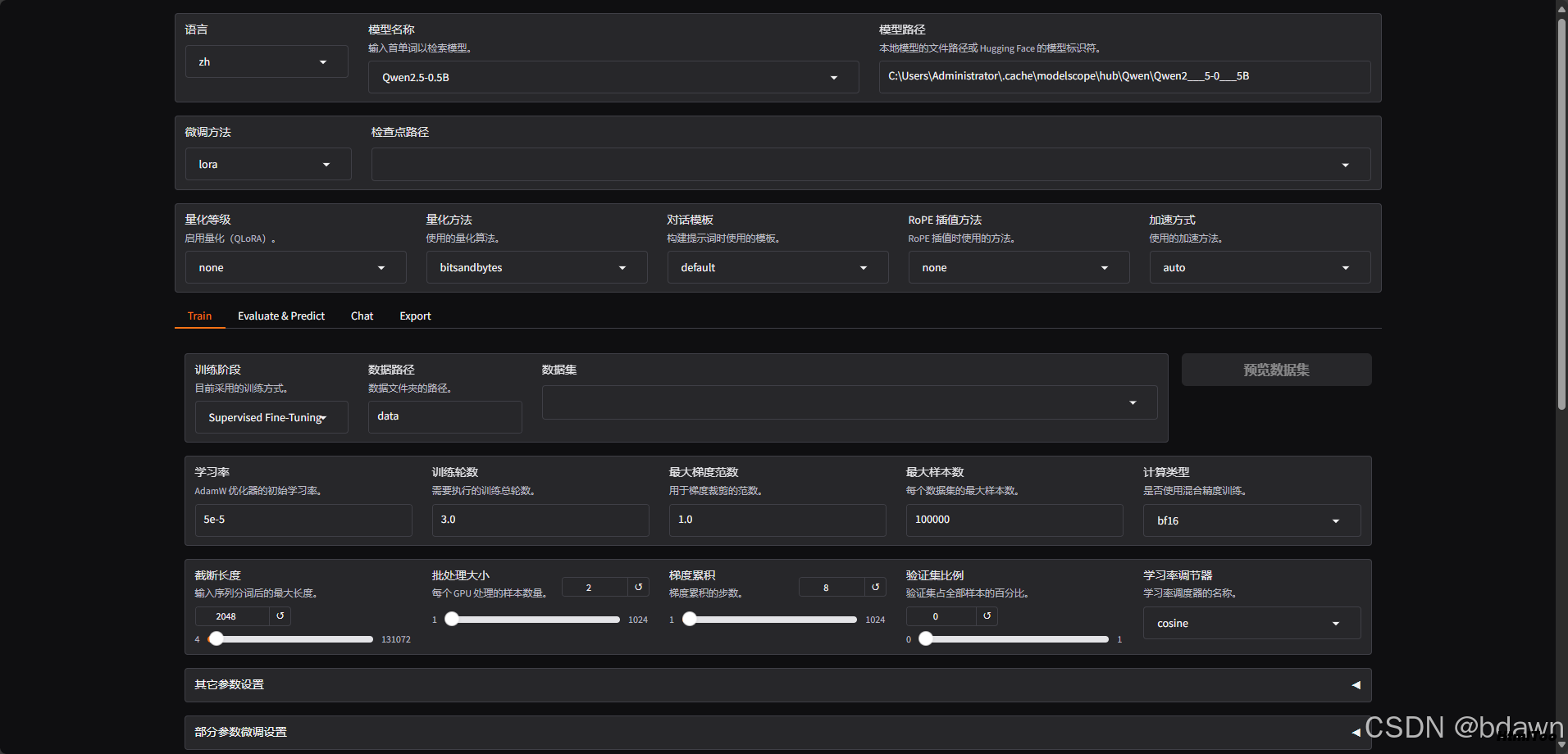
选择需要微调的大模型和相应文件路径:

选择预先准备的数据集:

设置训练参数:
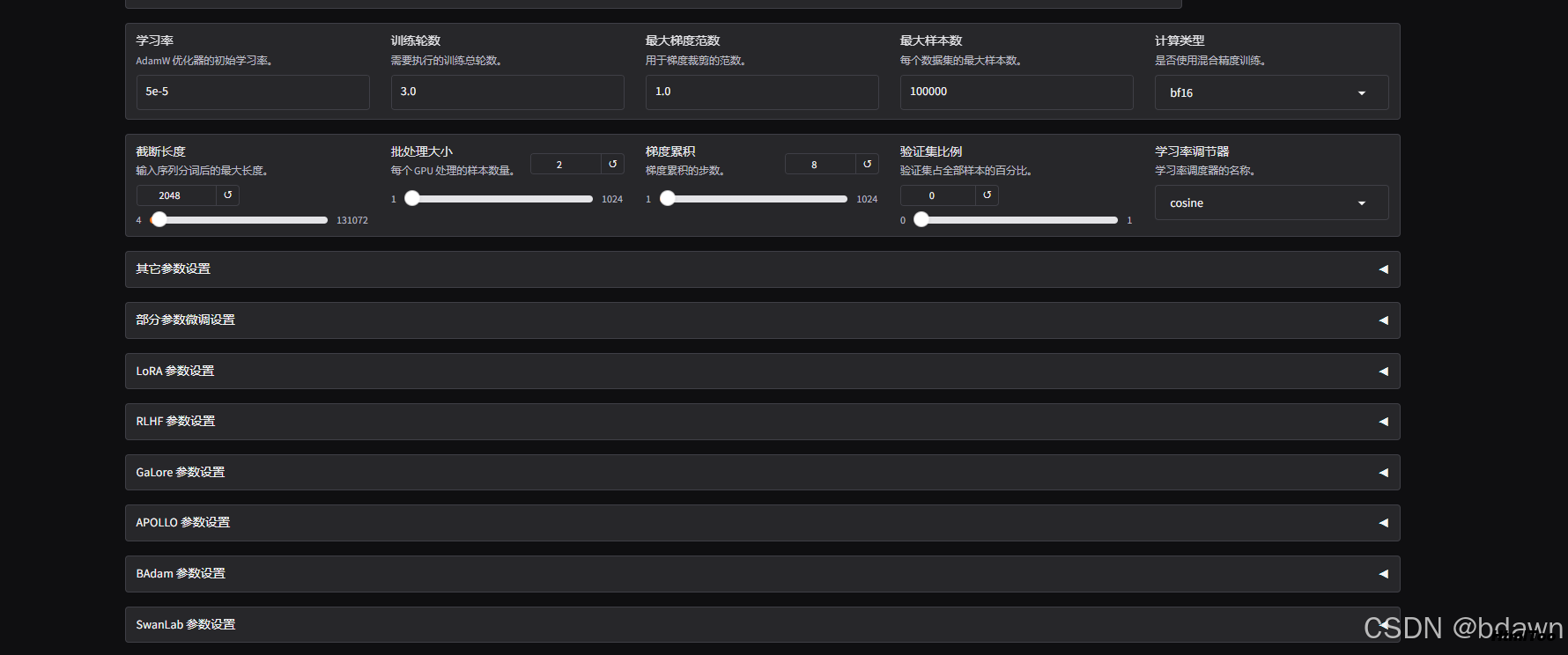
点击开始按钮,开始训练模型:

正在训练:
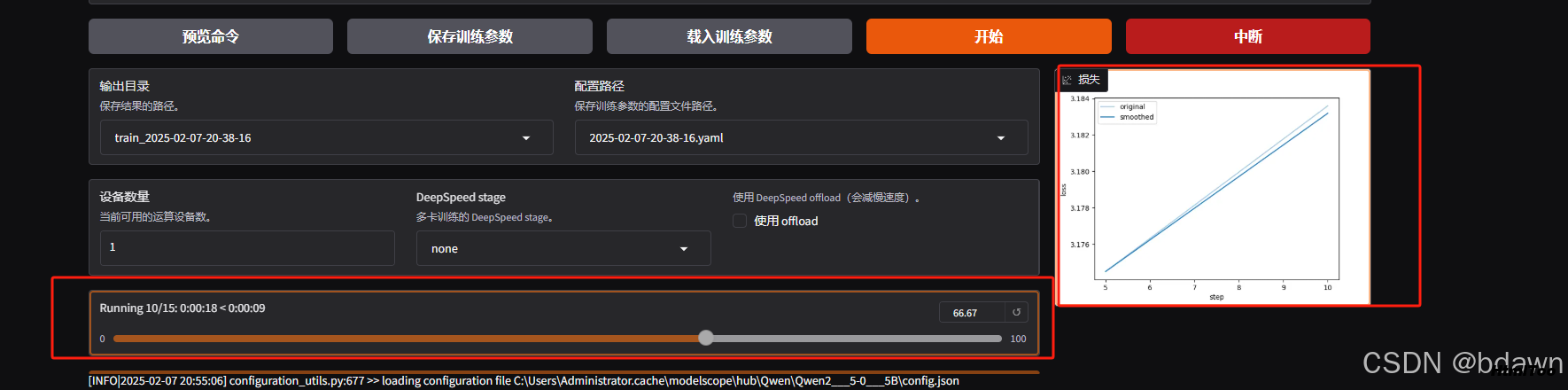
训练完成:
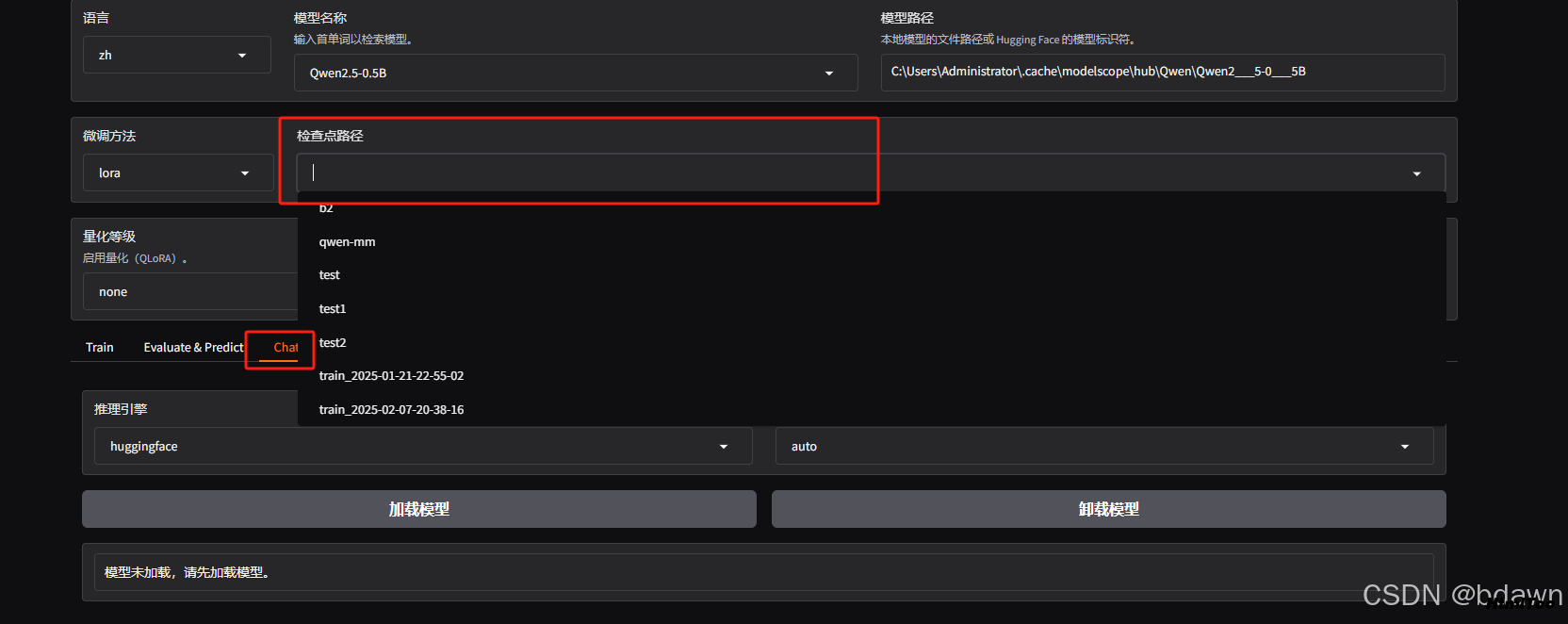
测试训练好的模型,选择之前训练好的模型,选择chat,提问一些测试问题:
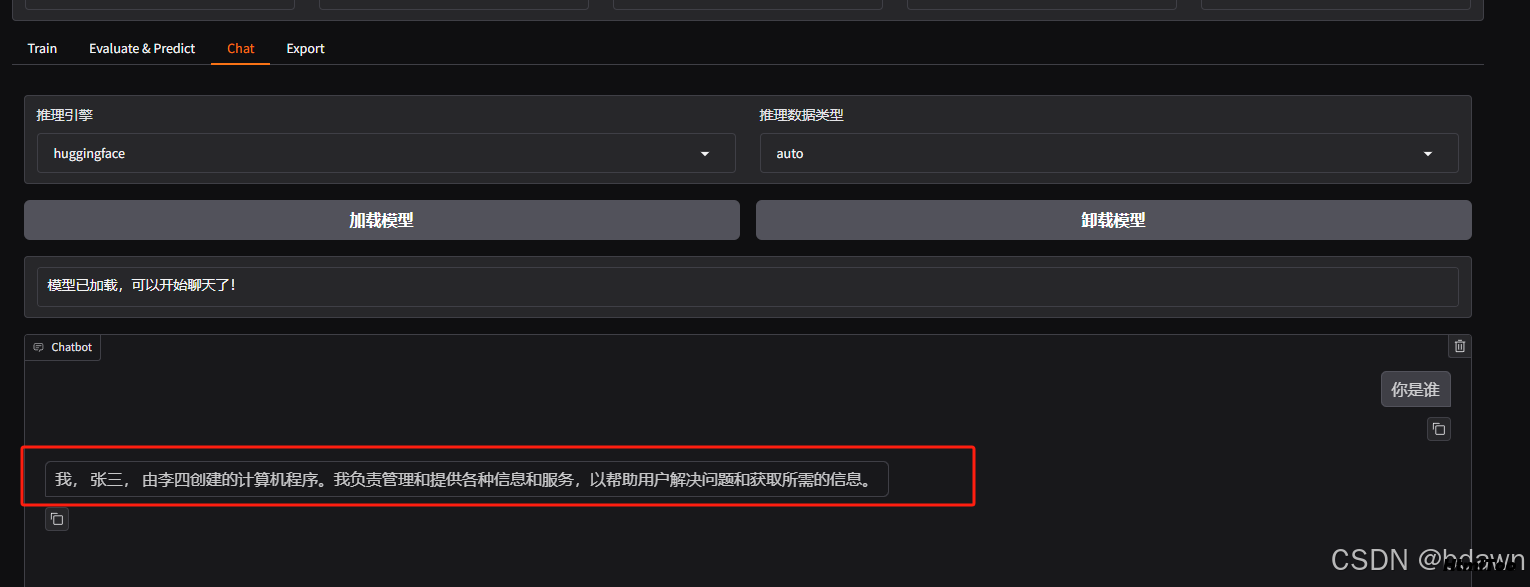
可以看到大模型的生成的内容已经发生改变。
总结
通过本文的介绍,可以快速使用LLaMA-Factory进行大模型的微调。LLaMA-Factory提供了一套完整的工具和流程,使得微调过程更加简单和高效。希望这篇文章对你有所帮助,让你在大模型微调的道路上更加顺利!


上篇:
SFT 指令微调数据 如何构建?
下篇:
一文图解Agent智能体:60张图、14个技术点回顾Agent的基本认知
1 电商必懂的数据公式 2 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 3 2026年人工智能领域,这些岗位急需大量人才 4 一个人全流程搞定AI漫剧:文生图+配音+剪辑的全链路解析 5 一句话生成100集AI漫剧!手把手干货教程! 6 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 7 2026 年 AI 创业全景指南:给渴望借 AI 逐梦的人! 8 跨境电商的疑难杂症,被1688这个AI全包了 9 扣子(Coze)工作流实战:篇篇10W+的小林漫画,用Coze实现了爆款流水线生... 10 用AI自动生成爆款文案的完整流程 11 人工智能 AI 在电商全链条的12个主要应用场景 12 信息差搬砖:用AI把小红书火帖变“付费文档”,日入500+