Easy Dataset 简介
Easy Dataset 是一个专为创建大型语言模型(LLM)微调数据集而设计的应用程序。上周刚开源。它提供了直观的界面,让用户可以轻松上传特定领域的文件,智能分割内容,自动生成问题,并为模型微调生成高质量的训练数据。
通过 Easy Dataset,我们可以将领域知识高效转化为结构化数据集,兼容所有遵循 OpenAI 格式的 LLM API(支持ollama,deepseek等),大大简化了微调过程。
核心功能
智能文档处理:自动将上传的 Markdown 文件分割为有意义的片段
智能问题生成:从每个文本片段中提取相关问题
答案生成:使用 LLM API 为每个问题生成全面的答案
灵活编辑:在流程的任何阶段编辑问题、答案和数据集
多种导出格式:支持 Alpaca、ShareGPT 等格式和 JSON、JSONL 文件类型
广泛的模型支持:兼容所有遵循 OpenAI 格式的 LLM API
用户友好界面:适合技术和非技术用户的直观 UI
自定义系统提示:添加自定义系统提示以引导模型响应
如何部署 Easy Dataset
本地部署
使用 NPM 安装
克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git cd easy-dataset
安装依赖:
npm install
构建并启动服务:
npm run build npm run start
在浏览器中访问 http://localhost:3000
使用 Docker 部署
拉取镜像:
docker pull conardli17/easy-dataset:latest
运行容器:
docker run -d -p 3000:3000 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset conardli17/easy-dataset:latest注意:为了防止数据丢失,请将 {YOUR_LOCAL_DB_PATH} 替换为你希望存储本地数据库的实际路径。
在 Render 上部署
Render 是一个云服务平台,可以让我们轻松部署 Web 应用。下面是在 Render 上部署 Easy Dataset 的步骤:
注册并登录 Render
点击 "New +" 按钮,选择 "Web Service"
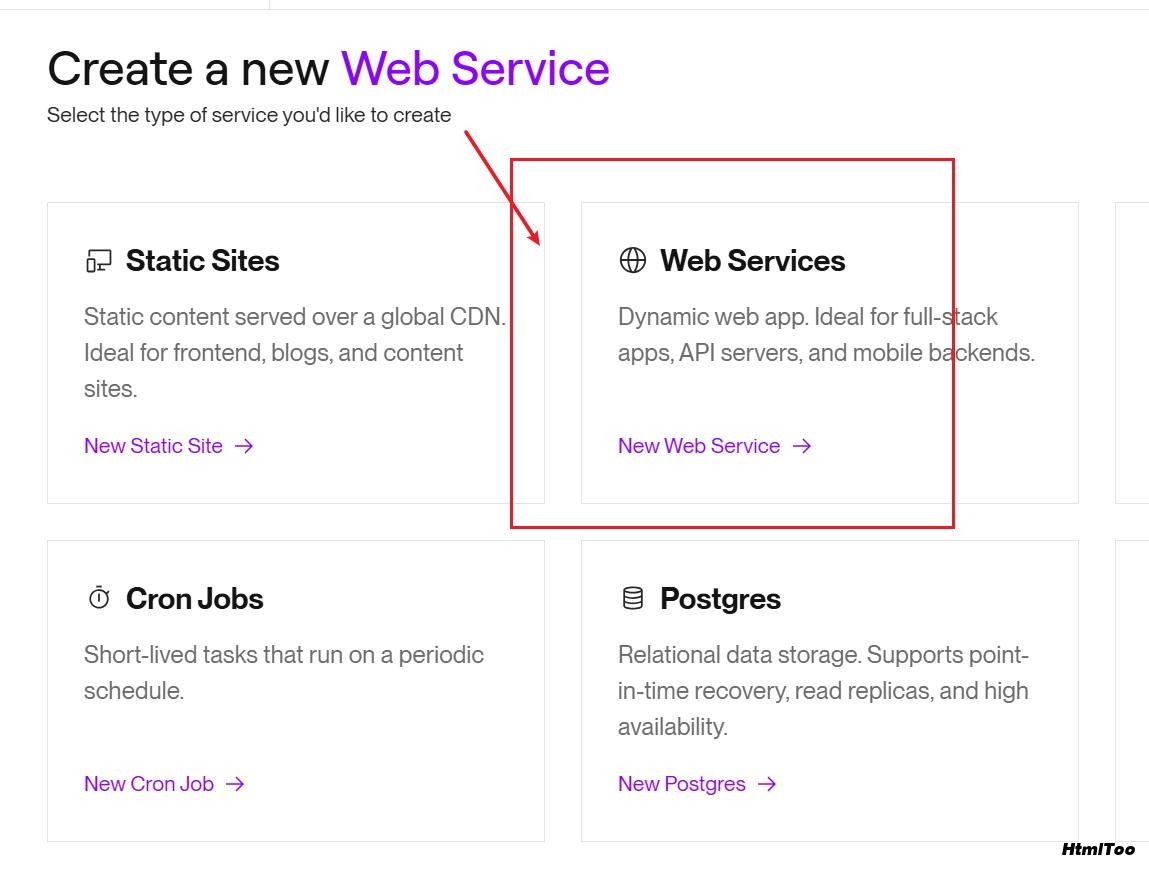
连接到你 fork 的 GitHub 仓库或直接使用原始仓库 URL
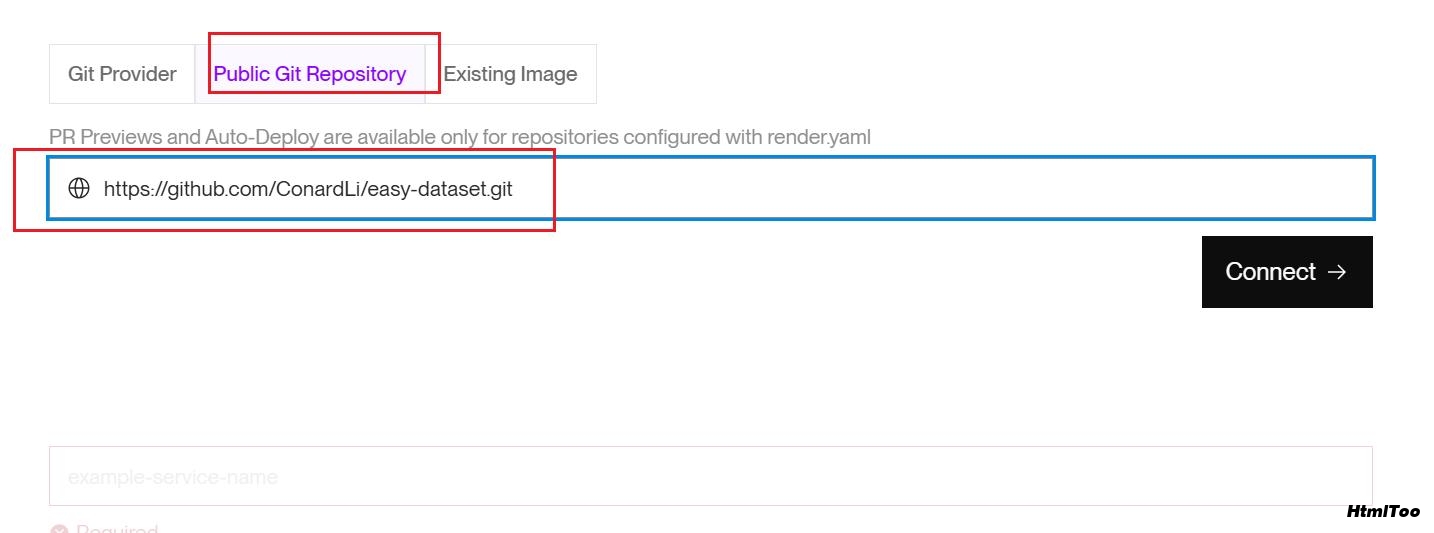
配置以下参数: Name: easy-dataset(或你喜欢的名称) Environment: Docker Branch: main Build Command: 留空(Docker 会处理) Start Command: 留空(Docker 会处理)
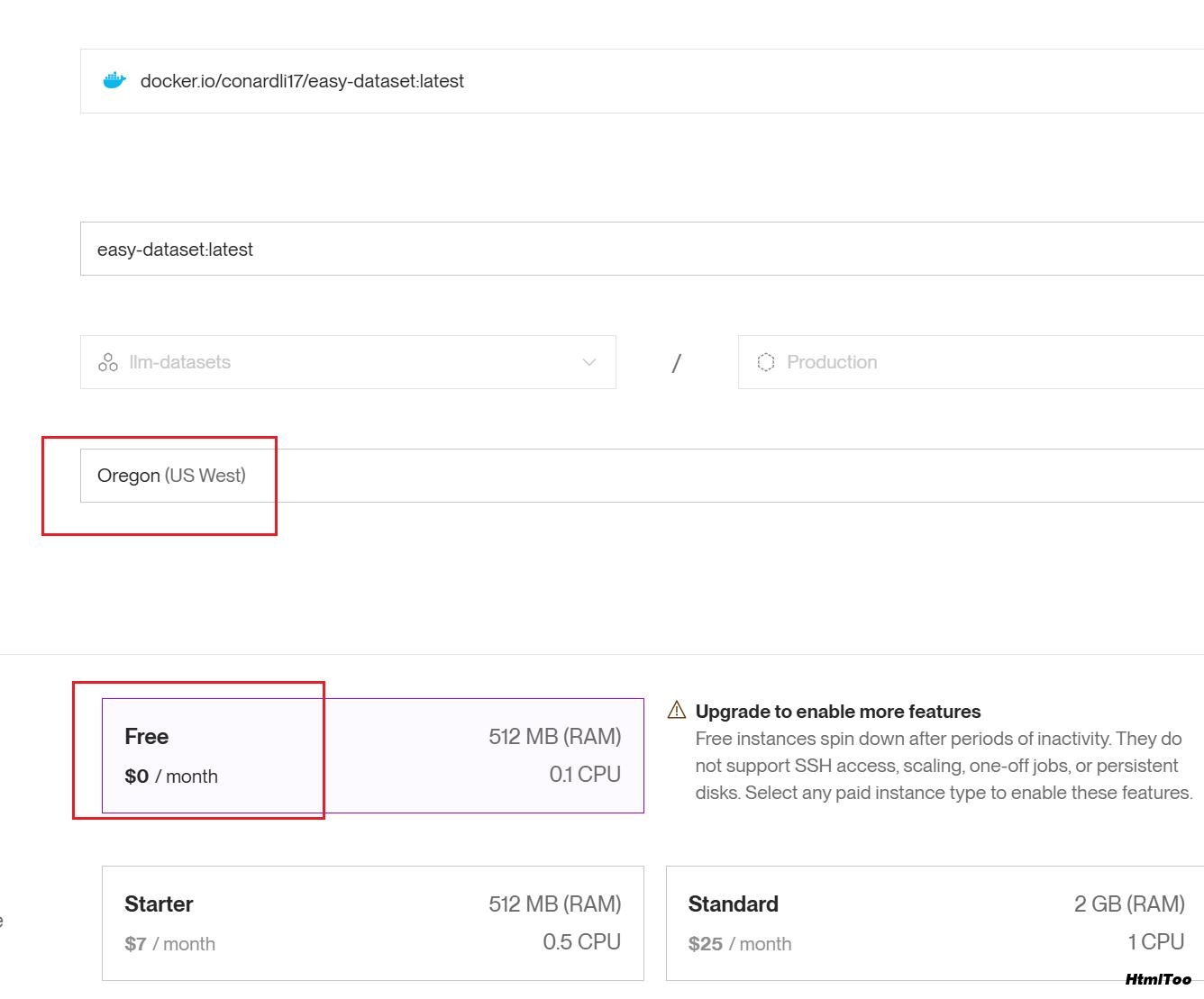
点击 "Create Web Service"
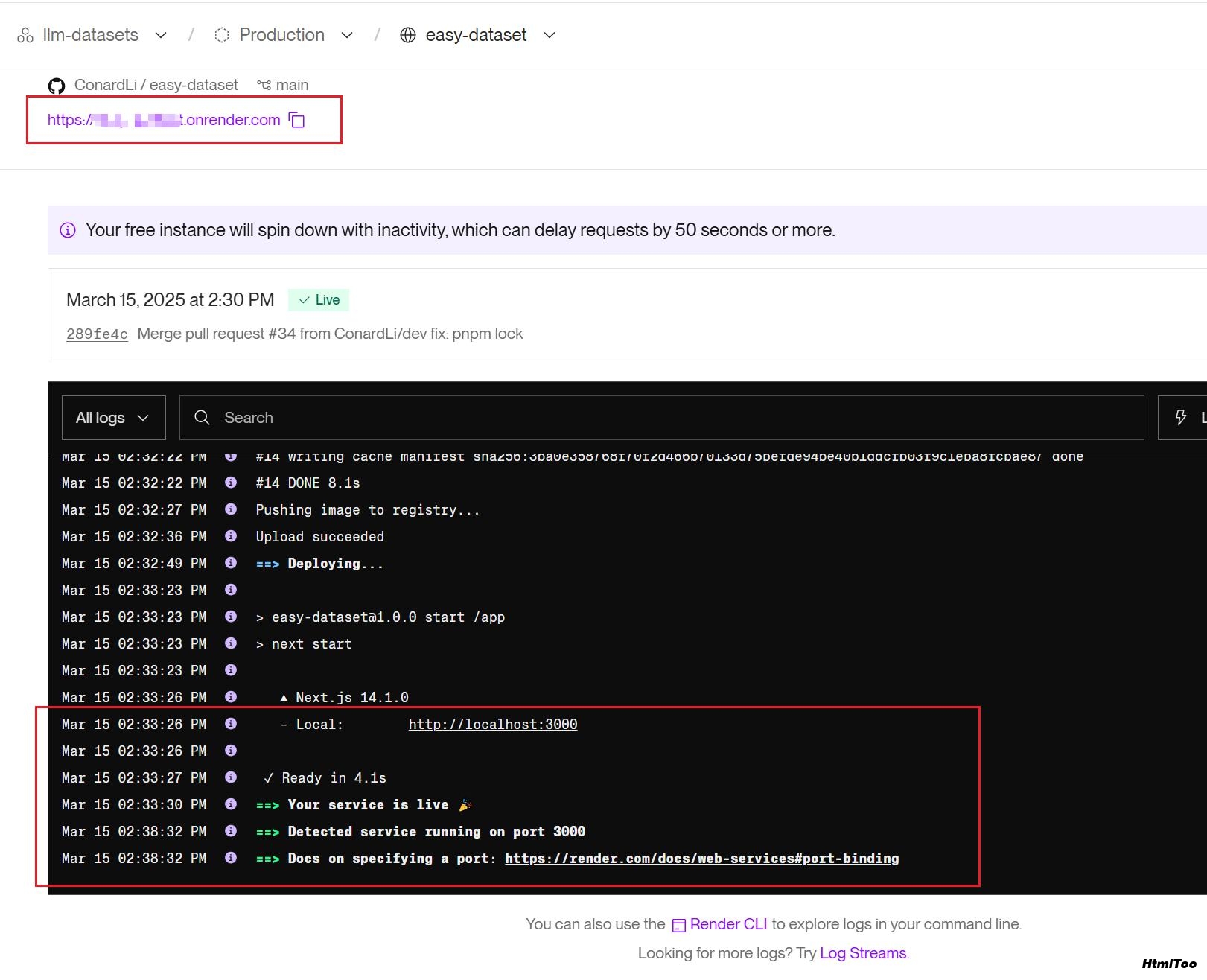
部署完成后,Render 会提供一个 URL,部署大概需要1分钟,耐心等待。
看到下面log出现就可以通过这个 URL 即可访问你的 Easy Dataset 应用。
使用流程详解
1. 创建项目
在首页点击"创建项目"按钮
输入项目名称和描述
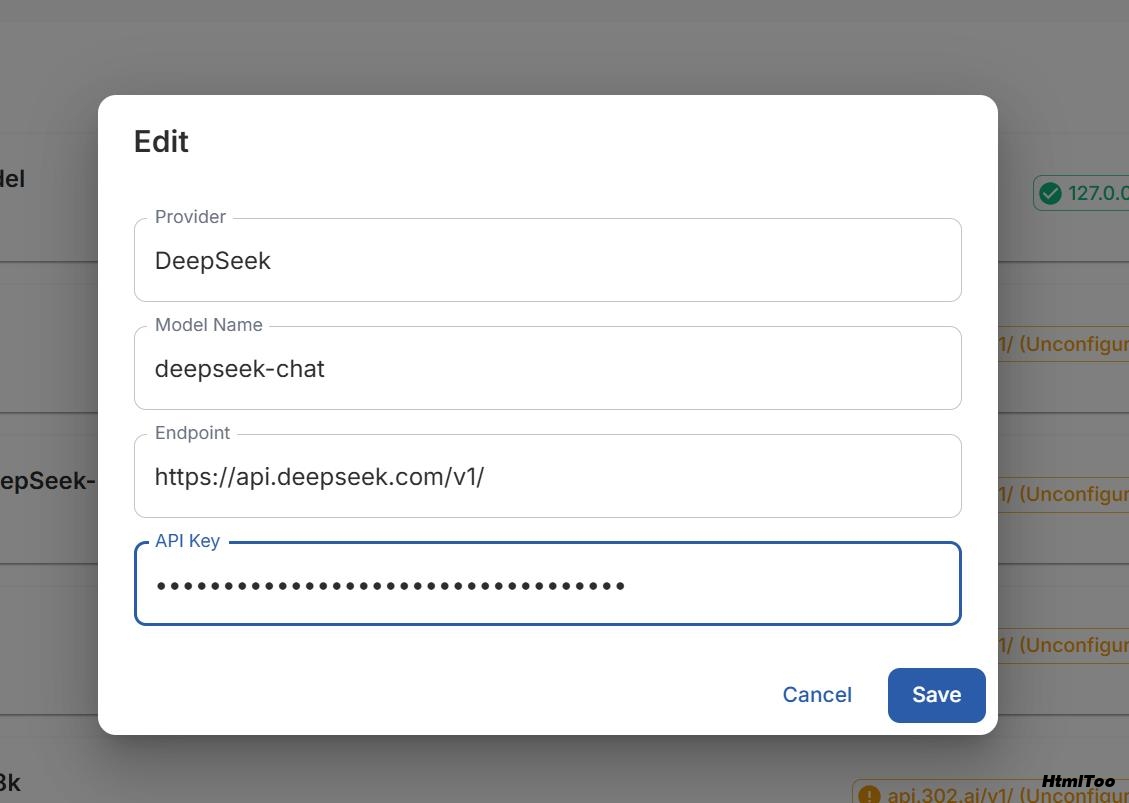
配置 LLM API 设置(OpenAI、Ollama 等)
2. 处理文档
在"文本分割"部分上传你的 Markdown 文件
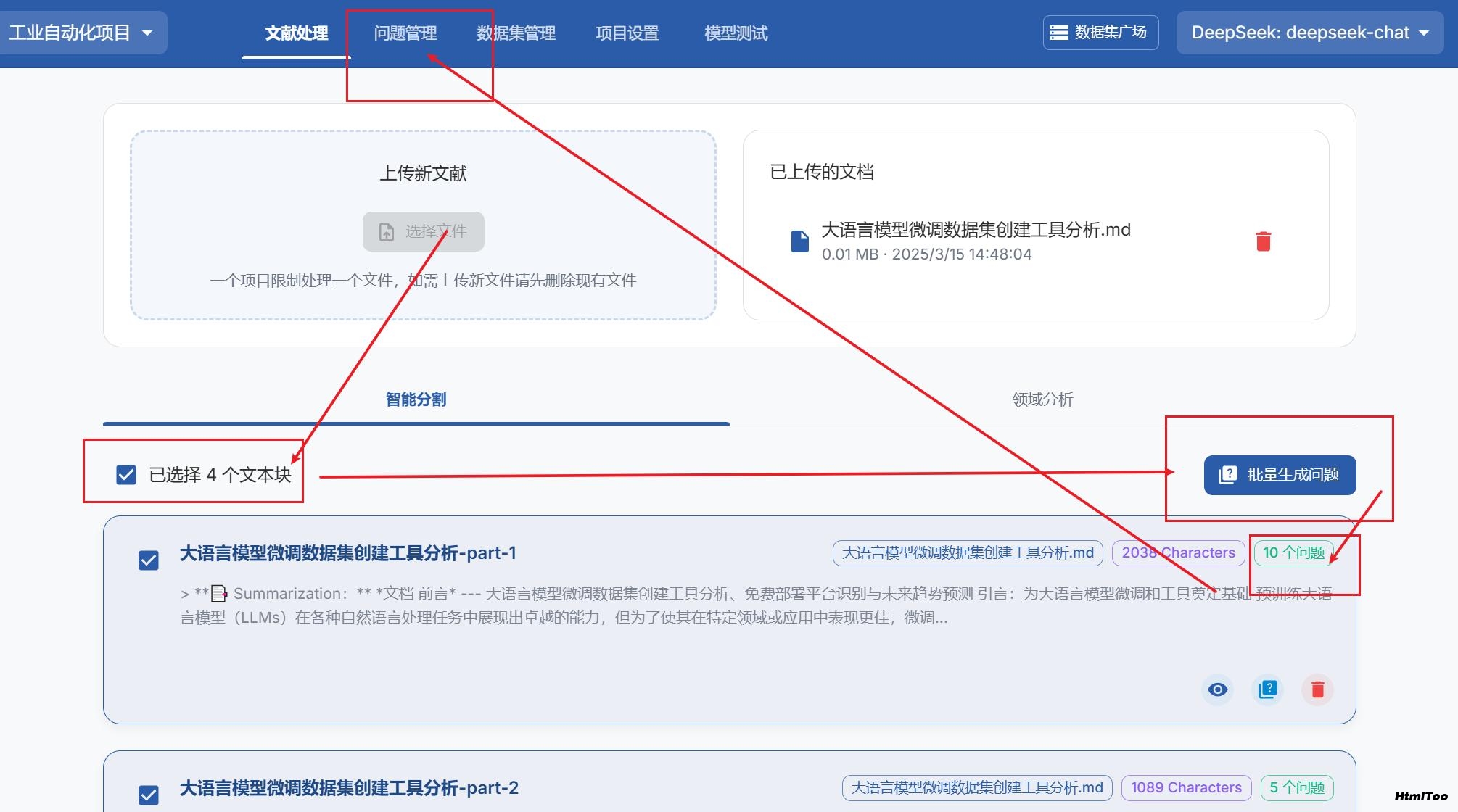
系统会自动分割文本片段
你可以根据需要调整分段大小和内容
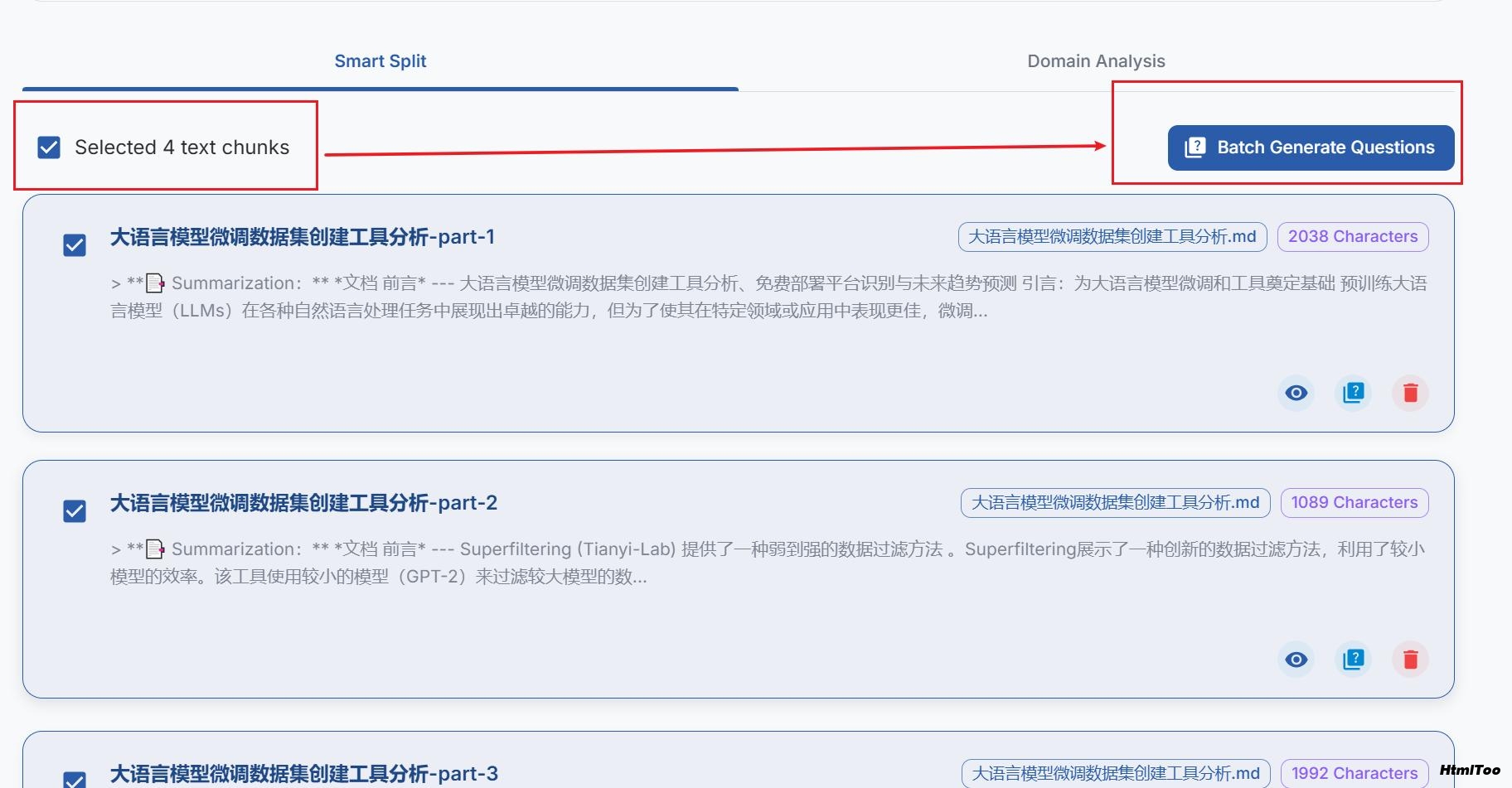
3. 生成问题
导航到"问题"部分
选择要生成问题的文本片段
系统会自动提取相关问题
你可以查看、编辑和使用标签树组织这些问题
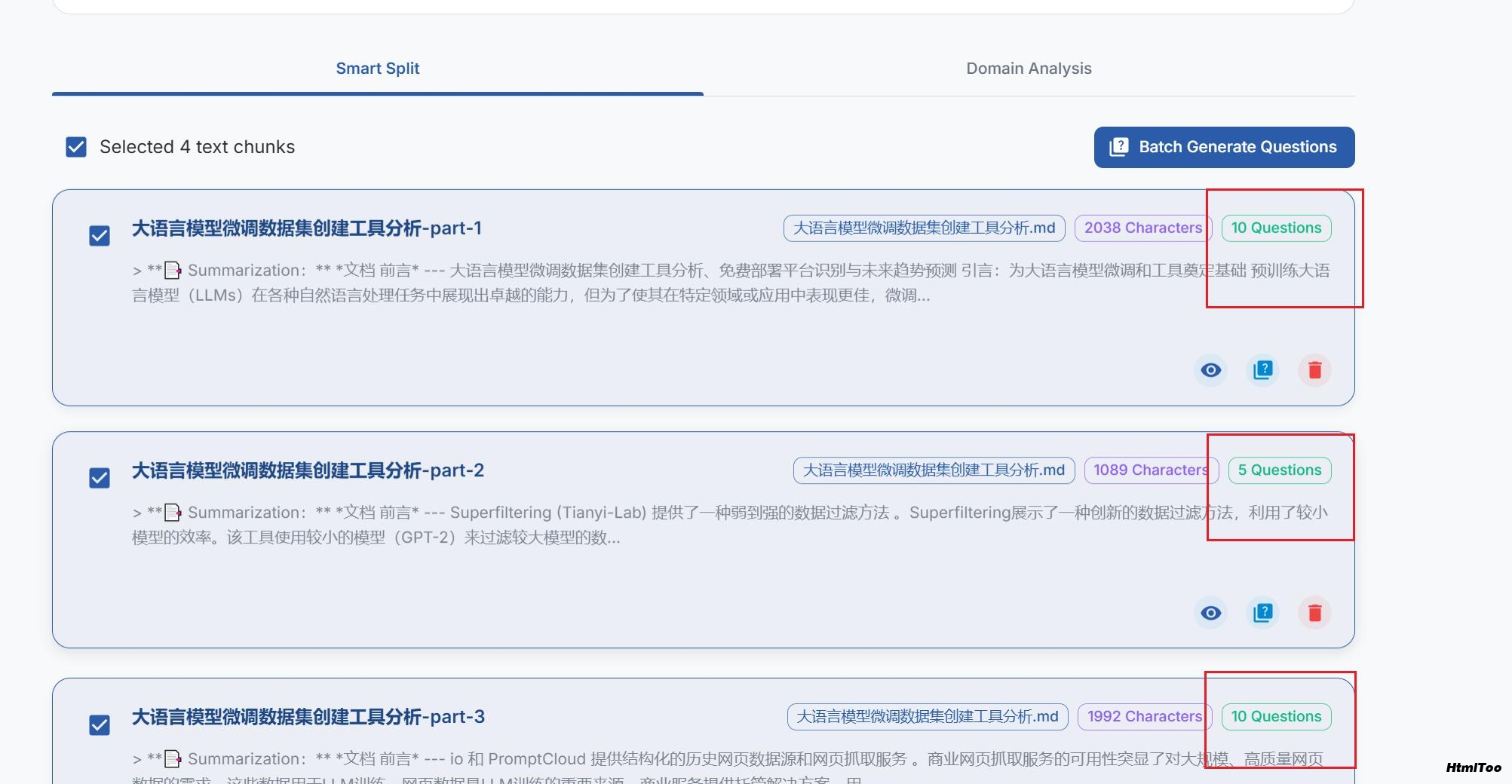
4. 创建数据集
转到"数据集"部分
选择要包含在数据集中的问题
使用配置的 LLM 生成答案
查看并编辑生成的答案,确保质量

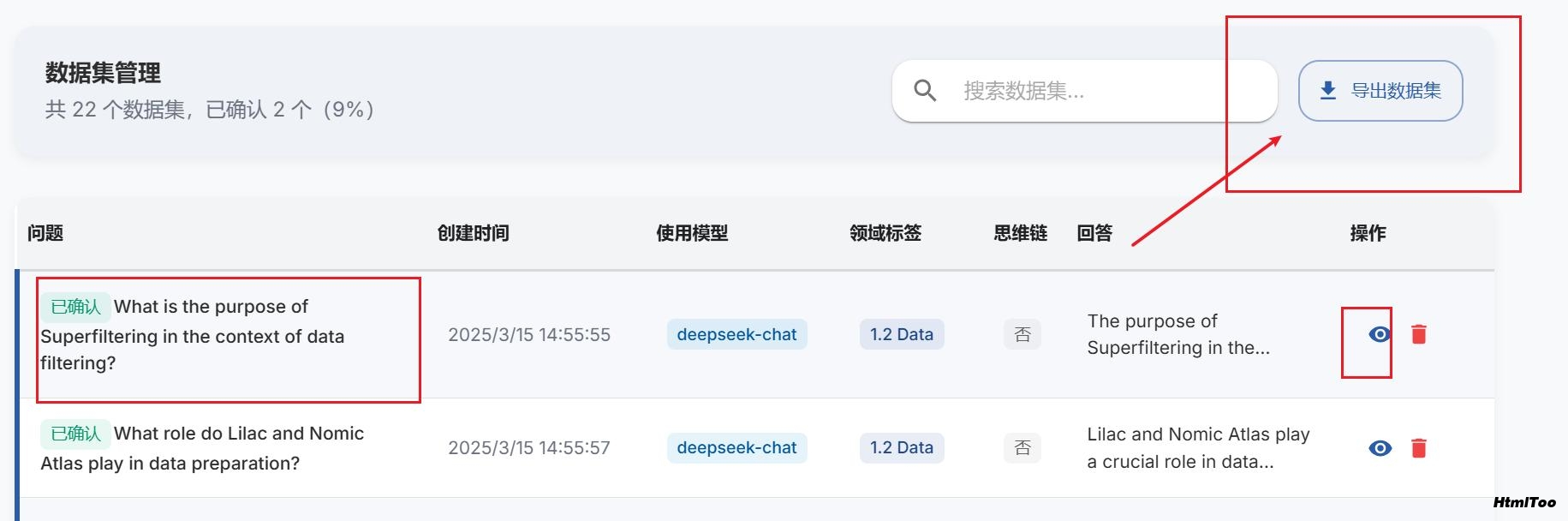
5. 导出数据集
在数据集部分点击"导出"按钮
选择格式(Alpaca 或 ShareGPT)
选择文件格式(JSON 或 JSONL)
添加自定义系统提示(可选)
导出你的数据集用于模型微调

项目结构
Easy Dataset 的代码组织非常清晰,主要包括以下几个部分:
app/:Next.js 应用目录,包含 API 路由和前端页面
components/:React 组件,包括数据集、项目管理等相关组件
lib/:核心库和工具,包括数据库操作、LLM 集成、文本分割工具等
locales/:国际化资源,支持中英文
local-db/:本地文件数据库,存储项目数据
总结与建议
Easy Dataset 作为一个强大的数据集准备工具,极大地简化了大模型微调的前期工作。对于关注行业专业领域应用的开发者和研究者来说,这是一个不可多得的效率工具。
使用建议:
选择高质量的领域文档进行上传
适当调整文本分割的大小,保证每个片段的完整性和连贯性
生成问题后进行人工筛选和编辑,确保问题的多样性和代表性
对生成的答案进行质量检查,确保准确性和专业性
尝试不同的导出格式,找到最适合你的微调框架的格式
如果你正在进行大模型微调和领域适应研究,强烈推荐尝试 Easy Dataset 这个开源工具。它将大大提高你的数据准备效率,让你能够更专注于模型训练和优化环节。
项目地址:https://github.com/ConardLi/easy-dataset
欢迎关注我的后续文章,我将分享使用这个工具创建的数据集进行大模型微调的详细过程和效果对比。


上篇:
被验证过的40个商业提示词模板
下篇:
SFT 指令微调数据 如何构建?
1 电商必懂的数据公式 2 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 3 2026年人工智能领域,这些岗位急需大量人才 4 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 5 2026 年 AI 创业全景指南:给渴望借 AI 逐梦的人! 6 用AI自动生成爆款文案的完整流程 7 人工智能 AI 在电商全链条的12个主要应用场景 8 信息差搬砖:用AI把小红书火帖变“付费文档”,日入500+ 9 地理空间AI应用:YOLO vs. SAM 10 AI应用快速原型开发:FastAPI + htmx ——无需React,为了快 11 剖析Mini-SGLang,打开LLM推理引擎的黑盒世界 12 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼”