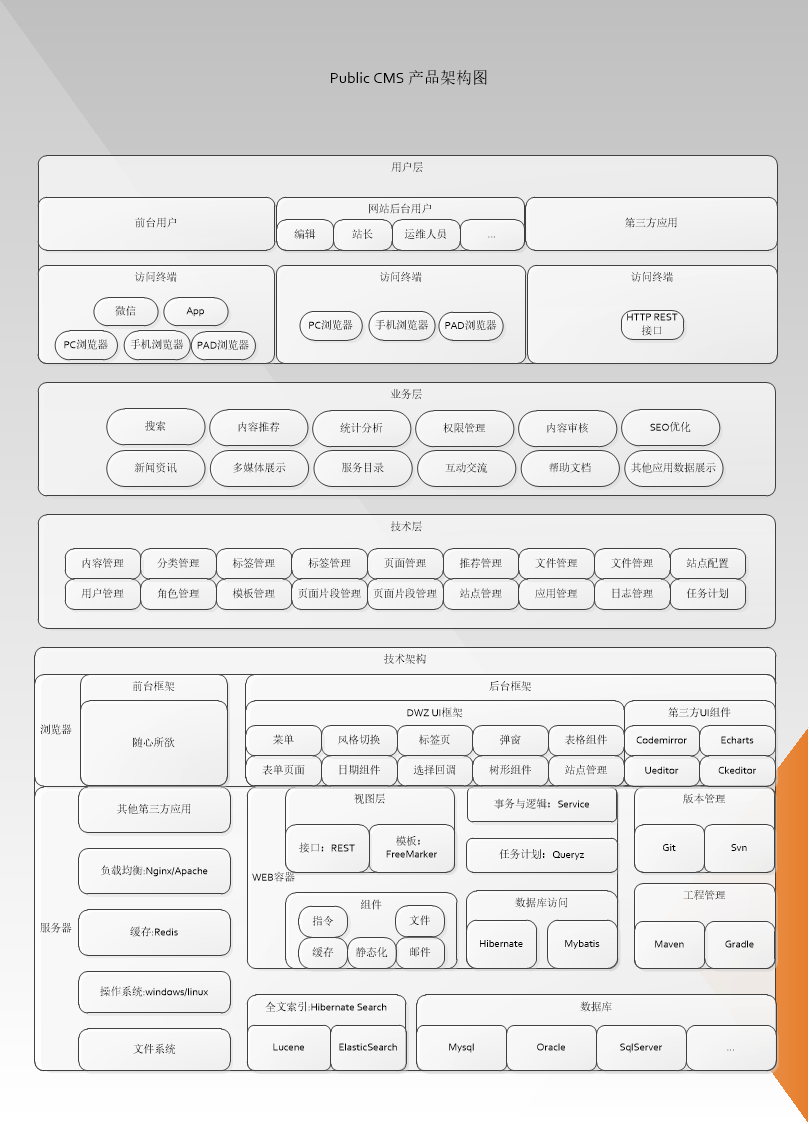
查看CPU是几核: cat /proc/cpuinfo |grep "cores"|uniq
查看CPU的主频: cat /proc/cpuinfo |grep MHz|uniq
直接获得CPU核心数: (该命令即可全部算出多少核): grep 'model name' /proc/cpuinfo | wc -l
取得CPU核心数目N,观察后面2个数字,用数字/N,如果得到的值小于0.7即可无忧。
load average 0.37 0.44 0.50 系统负载,任务队列不同时间段平均长度,分别为1分钟,5分钟,15分钟前到现在
根据经验:我们应该把重点放在5/15分钟的平均负载,因为1分钟的平均负载太频繁,一瞬间的高并发就会导致该值的大幅度改变。
查看系统平均负载使用“cat /proc/loadavg”命令: 0.37 0.44 0.50 1/621 16774
前三个数字是1、5、15分钟内的平均进程数。后面的 1/621 一个的分子是正在运行的进程数,分母是进程总数;另一个是最近运行的进程ID号。
单核CPU, 数字在0.00-1.00之间正常
多核CPU - 多车道 数字/CPU核数 在0.00-1.00之间正常,
多核CPU的话,满负荷状态的数字为 "1.00 * CPU核数",即双核CPU为2.00,四核CPU为4.00。
一般来讲70%左右的负载也就是0.7左右应该是没问题的,要根据实际生产环境中实际需求来进行浮动设定
在Load average 高的情况下如何鉴别系统瓶颈。是CPU不足,还是io不够快造成? 或是内存不足?
一:查看系统负载vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 496056 889316 4065748 0 0 9 41 55 51 0 0 99 1 0
1 : procs
procs
r b
0 0
r :运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b :在等待资源的进程数,比如正在等待I/O、或者内存交换等。
2 : memory
-----------memory----------
swpd free buff cache
0 496056 889316 4065748
swpd :切换到内存交换区的内存数量(k表示)。
如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free :当前的空闲页面列表中内存数量(k表示)
buff :作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache :作为page cache的内存数量,一般作为文件系统的cache,
如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
3 : swap
---swap--
si so
0 0
si :由内存进入内存交换区数量。
so :由内存交换区进入内存数量。
4 : IO
-----io----
bi bo
9 41
bi :从块设备读入数据的总量(读磁盘)(每秒kb)。
bo :块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
5 : system 显示采集间隔内发生的中断数
--system--
in cs
55 51
in :在某一时间间隔中观测到的每秒设备中断数。
cs :每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
6 : cpu 表示cpu的使用状态
-----cpu------
cs us sy id wa st
51 0 0 99 1 0
us :用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy :内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa :IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,
这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id :cpu处在空闲状态的时间百分比


上篇:
100个最常用的linux命令
下篇:
MySQL常用命令
1 约中年女人出来玩,这6个技巧太有用了,一般不会被拒绝 2 微软架构师:用FastAPI+Redis构建高并发服务,性能提升2000%! 3 链路聚合:二层和三层设备都使用链路聚合(实现负载均衡),并使所有vlan可以相互... 4 PVE 给系统盘扩容磁盘空间 5 RH2288v3服务器-磁盘阵列,安装系统 6 CentOS7.7下使用Openfiler+Multipath+UDEV 7 图解RAID存储技术:RAID 0、1、5、6、10、50、60 8 通过模仿海兰之家的模式,无数传统企业在短时间内成为行业领导者 9 H3C UIS超融合一体机 部件更换配置指导 10 RAID0,RAID1,RAID5,RAID10阵列场景应用 11 配置RAID5磁盘阵列 12 RAID 0 1 5 10 磁盘阵列