本文主要是针对UIS一体机硬件设备出现故障时,更换硬件方法的配置指导。主要包括更换网卡、硬盘等部件的操作方法。
1.1 适用范围及注意事项
使用本文档时,请关注如下事项。
· 本文档中所述操作均存在一定风险,可能会损坏已有环境。因此本文档仅适用于H3C服务工程师以及具备相应资质和技术水平的工程师。
· 本文档主要介绍集群节点部件更换过程中软件侧的相关操作,具体的硬件安装拆卸方法请参见对应服务器机型的用户指南。
· 由于产品版本升级或其他原因,本文档内容会不定期进行更新,如需获取最新版本,请联系技术支持。
· 由于产品版本升级或其他原因,产品界面和功能参数可能会变化,请以产品的实际支持情况为准。
· 根据本文档执行部件更换操作前,建议先参考《H3C UIS超融合管理平台 巡检配置指导》手册,对现场进行巡检并记录相关信息。
· 进行某些部件更换时(如CPU、主板和网卡),可能会使设备的硬件信息变更,从而导致产品的授权失效。请联系技术支持提交授权变更申请,更改授权绑定的硬件设备信息。
· 本文档中介绍的阵列卡相关操作方法仅适用于H3C服务器,其他品牌服务器的阵列卡操作方法请联系相应厂家获取。
表1 部件更换工具列表
名称 | 说明 | |
| 用于智能挂耳上的松不脱螺钉(一字螺丝刀也可用于该螺钉) | |
T30 Torx星型螺丝刀 | 用于CPU散热器上的松不脱螺钉 | |
T10 Torx星型螺丝刀(随服务器发货) | 用于拆卸智能挂耳固定螺钉等 | |
一字螺丝刀 | 用于更换系统电池等 | |
十字螺丝刀 | 用于硬盘支架的固定螺钉等 | |
| 防静电腕带 | 用于操作服务器时使用 |
| 防静电手套 | |
| 防静电服 |




更换部件时,请注意如下事项:
· 更换部件时,优先使用同构部件,即新旧部件BOM相同,型号规格完全相同。仅当无法获取到同构部件时,联系技术支持使用异构部件进行更换。
· 部件更换是在已有可靠性基础上进行部件更换,如果现有的可靠性机制无法保证业务无损,则建议提前预警。
· 在进行更换硬件操作时,严禁从UIS系统中删除主机。
UIS支持换盘向导功能,支持的软件版本、一体机型号和操作步骤可参考2.1章节。支持换盘向导时,“节点管理”页面有<更换硬盘>按钮,不支持时,则无该按钮。
· 如果使用UIS 2000 G3系列一体机,硬盘更换的方法请参考《H3C UIS 2000 G3系列超融合一体机操作配置指导》手册中的“UIS2000 G3 故障盘监测及更换”章节。
· 不支持换盘向导的版本或一体机型号,请参考2.2-2.5章节进行硬盘更换。
某些服务器(如R4900,其他支持在线更换硬盘的主机型号请参考兼容性列表)安装了E0716P03及之后版本的UIS软件时支持使用换盘向导更换磁盘,除主机型号外,磁盘需满足下列要求。如果需要更换NVMe缓存盘,需要先正常关机后更换硬盘,再在换盘向导中进行更换操作。
表2 更换磁盘的场景要求
维护对象 | 具体情形 | 插拔要求 | 容量要求 | 接口要求 | 插槽要求 |
SATA或SAS接口的数据盘、缓存盘 | 槽位不变,更换磁盘 | 可带电拔插,对业务无要求 | 新盘容量不小于原盘容量 | 新盘接口类型与原盘保持一致 | 无 |
磁盘和槽位同时更换 | 可带电拔插,对业务无要求 | 新盘容量不小于原盘容量 | 新盘接口类型与原盘保持一致 | 无 |
(1) 确认槽位信息。请根据所用一体机的硬件手册,确认硬盘的槽位信息,使其与界面中显示的位置信息对应。
(2) 选择顶部“存储”页签,选择左侧的节点管理,进入存储节点管理界面。首先选择需要更换硬盘的主机节点,单击<同步磁盘>按钮,避免因为未同步导致的异常。
(3) 同步完成后,界面上显示了故障节点,选择故障节点可以看到该节点下故障的硬盘。故障盘的槽位为5。此时可以手动点亮故障盘的磁盘灯,辅助定位故障磁盘的位置。
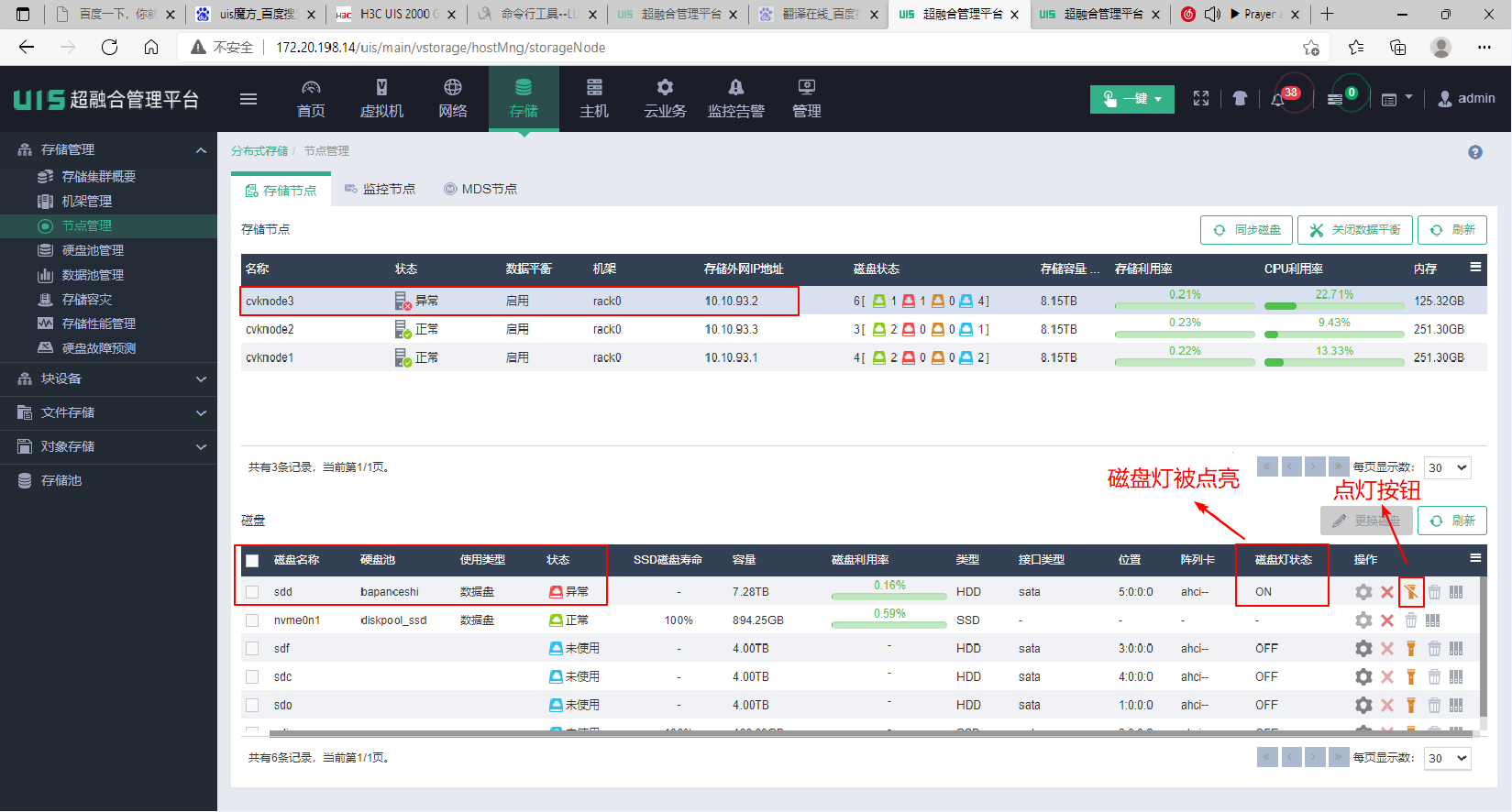
(4) 进入机房,拔下槽位5故障盘,插入新盘。然后再次回到软件界面。单击<同步磁盘>按钮和<刷新>按钮,直到识别到新盘,新盘的盘符可能发生变化,但是新盘的槽位号和原故障盘是保持一致的。
如果新盘中存在已有分区,应先清理分区。在系统后台执行后台sgdisk -o /dev/sdd(sdd为坏盘的盘符,需根据实际坏盘的盘符进行调整)命令,清理分区。
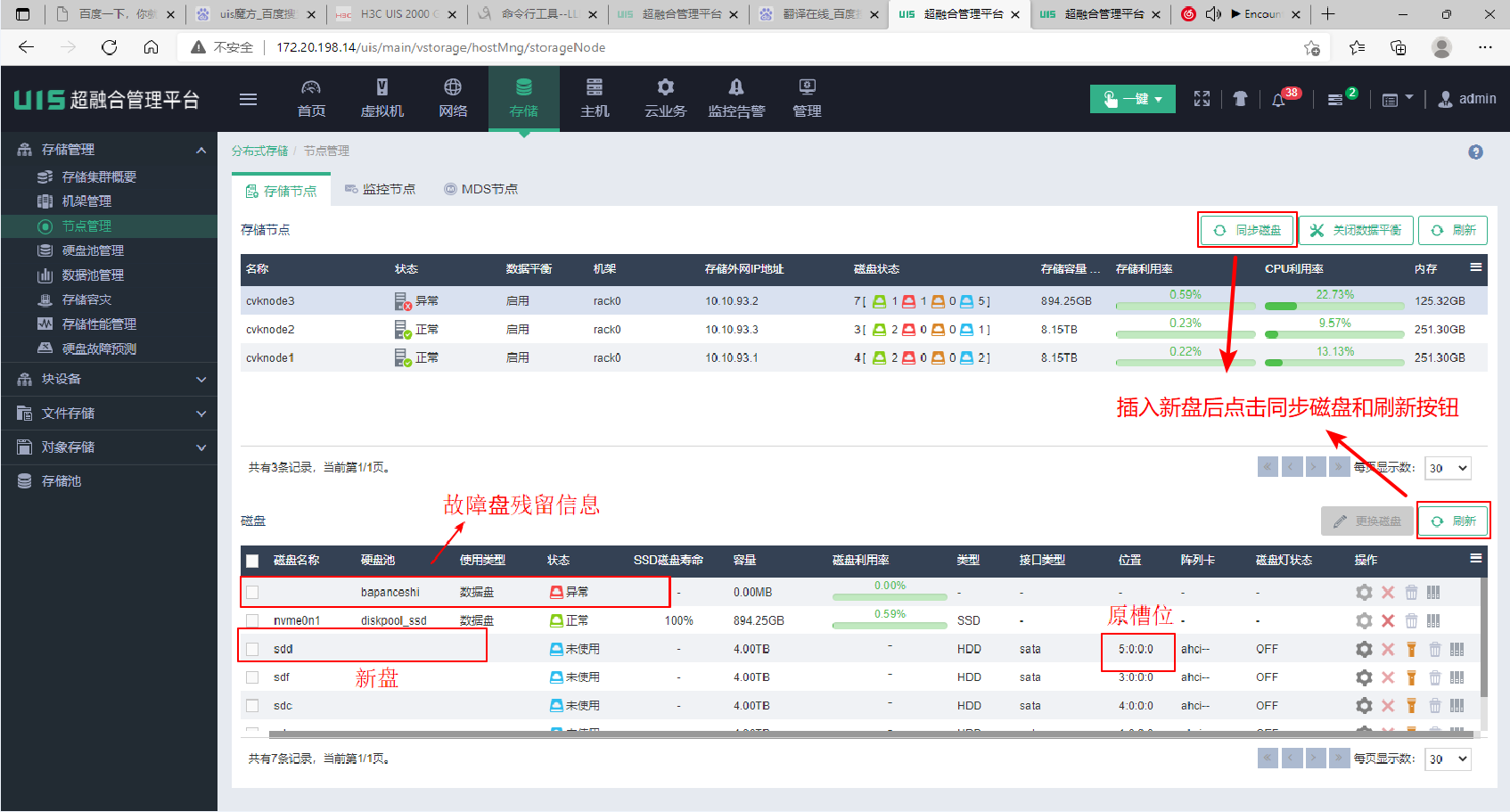
(5) 选中计划更换的故障盘,单击<更换磁盘>按钮。
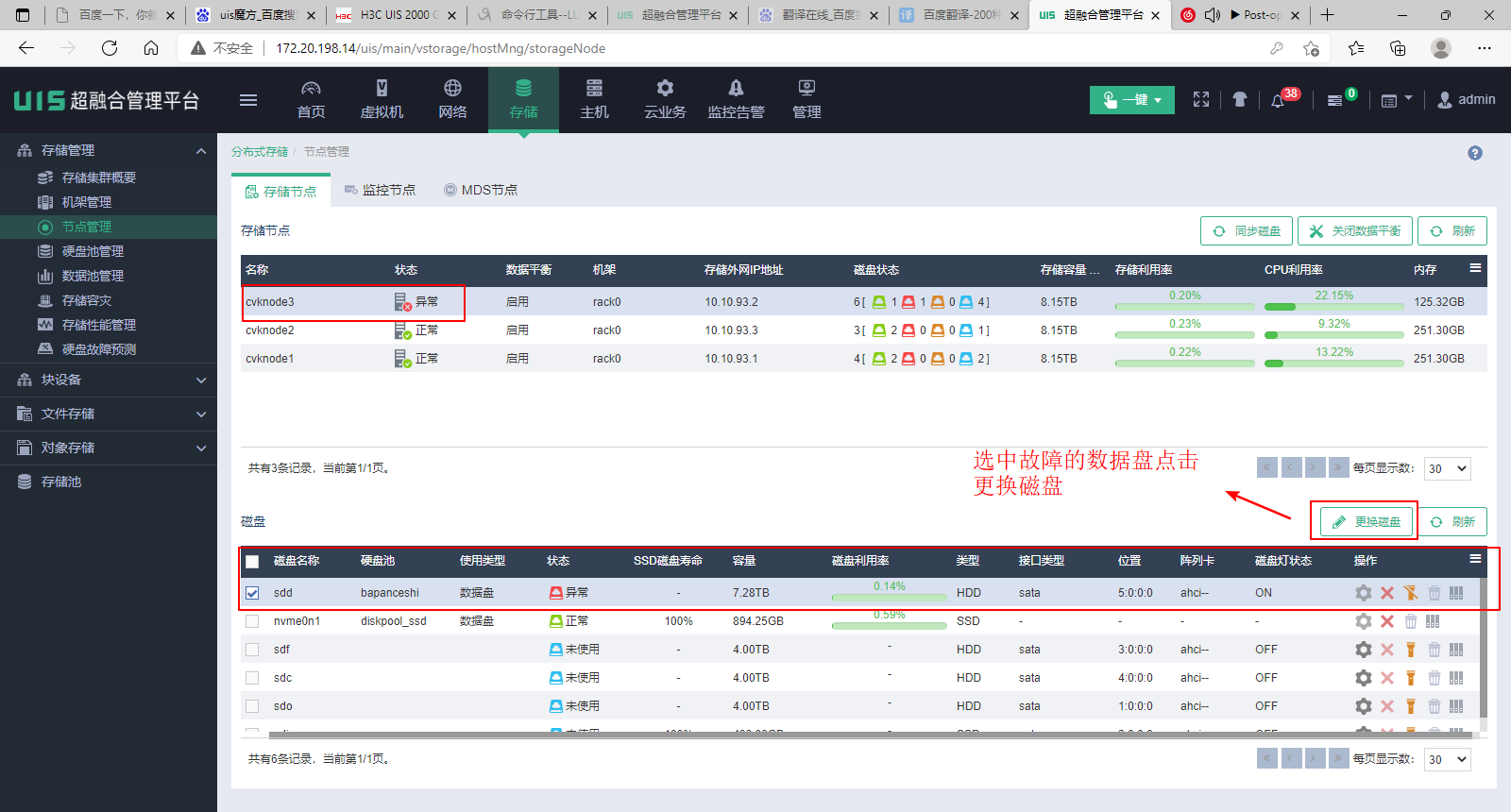
(6) 在跳转界面先选中故障盘。此时盘可能只有一些残留信息了,看不到原来的完整信息,但是只能选择到被单击换盘的数据盘,因此此处就直接选择唯一可选的那块盘。
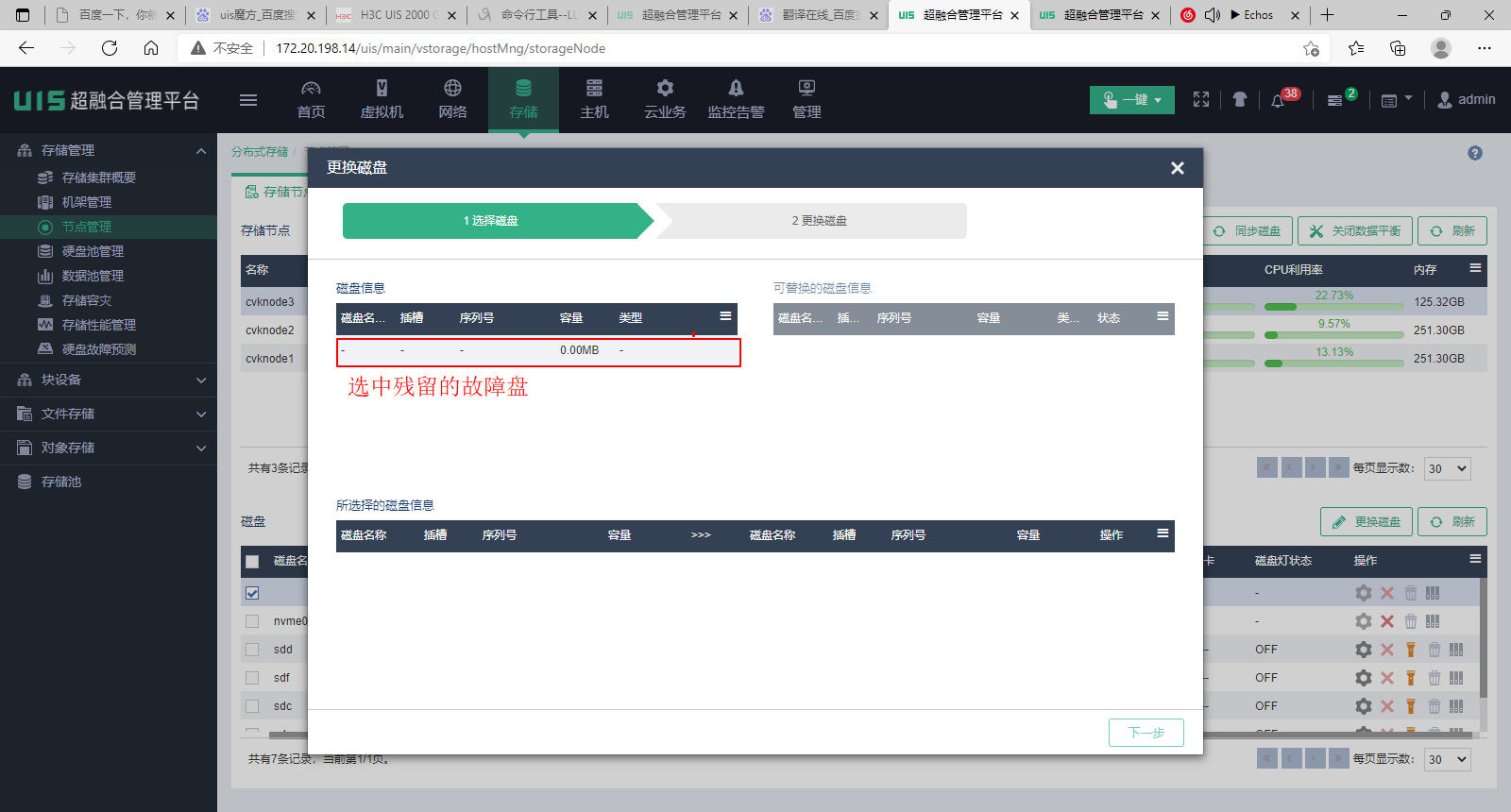
(7) 然后选择插入的新盘。注意查看新盘的容量,类型信息是否正确,槽位号是否正确。
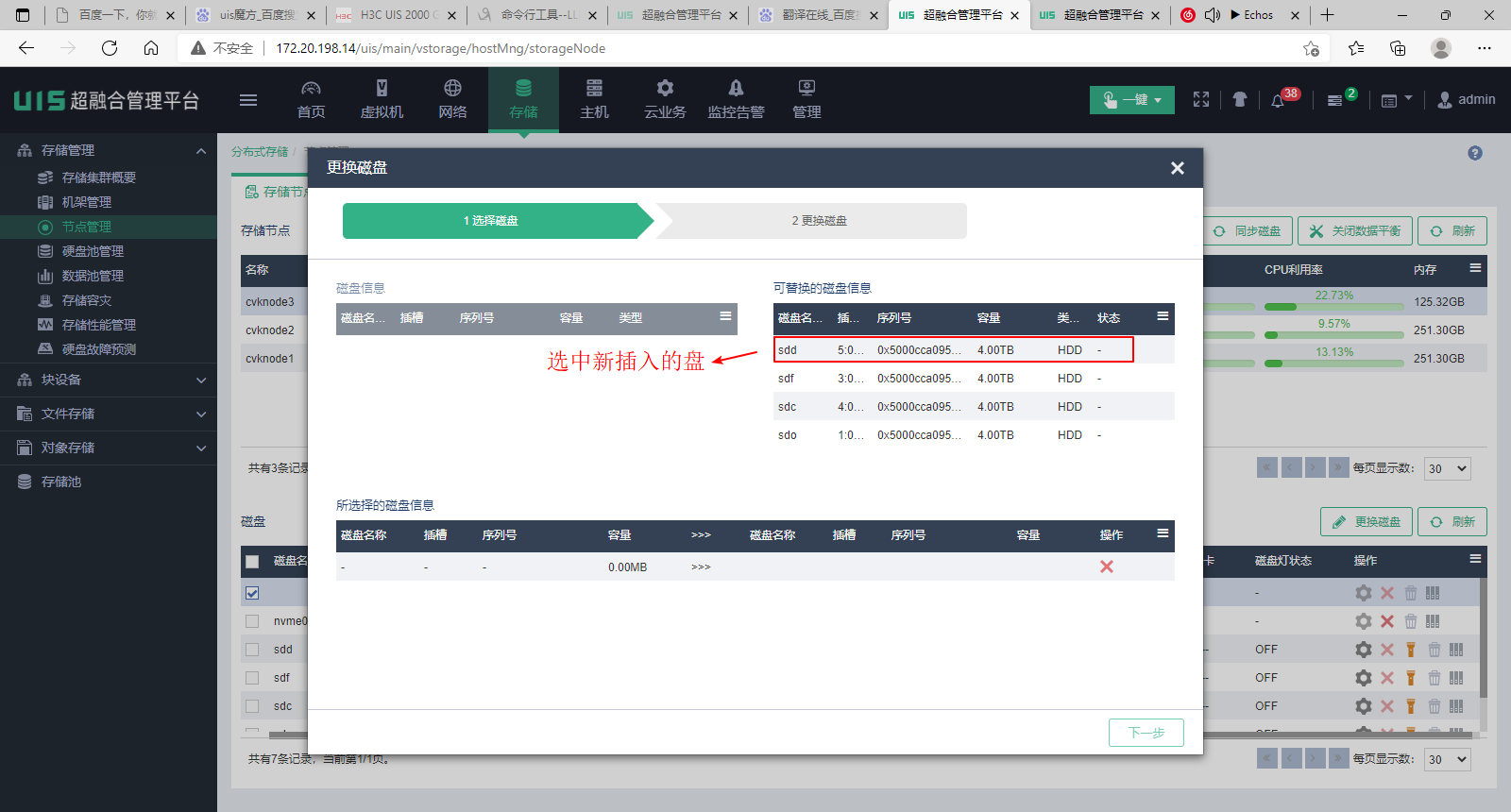
(8) 选择完成后,单击<下一步>按钮。
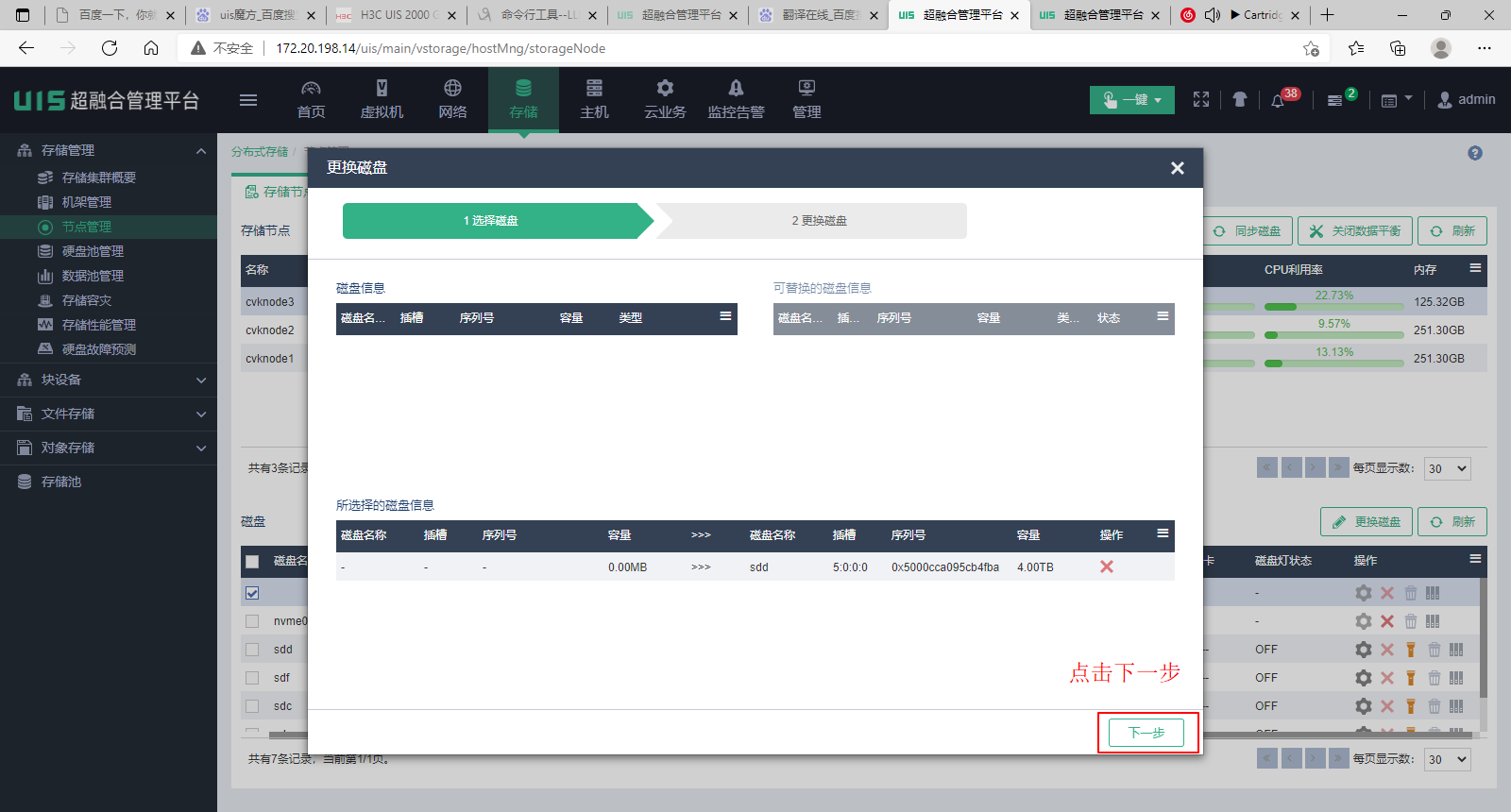
(9) 单击<完成>按钮,系统会自动开始换盘任务。
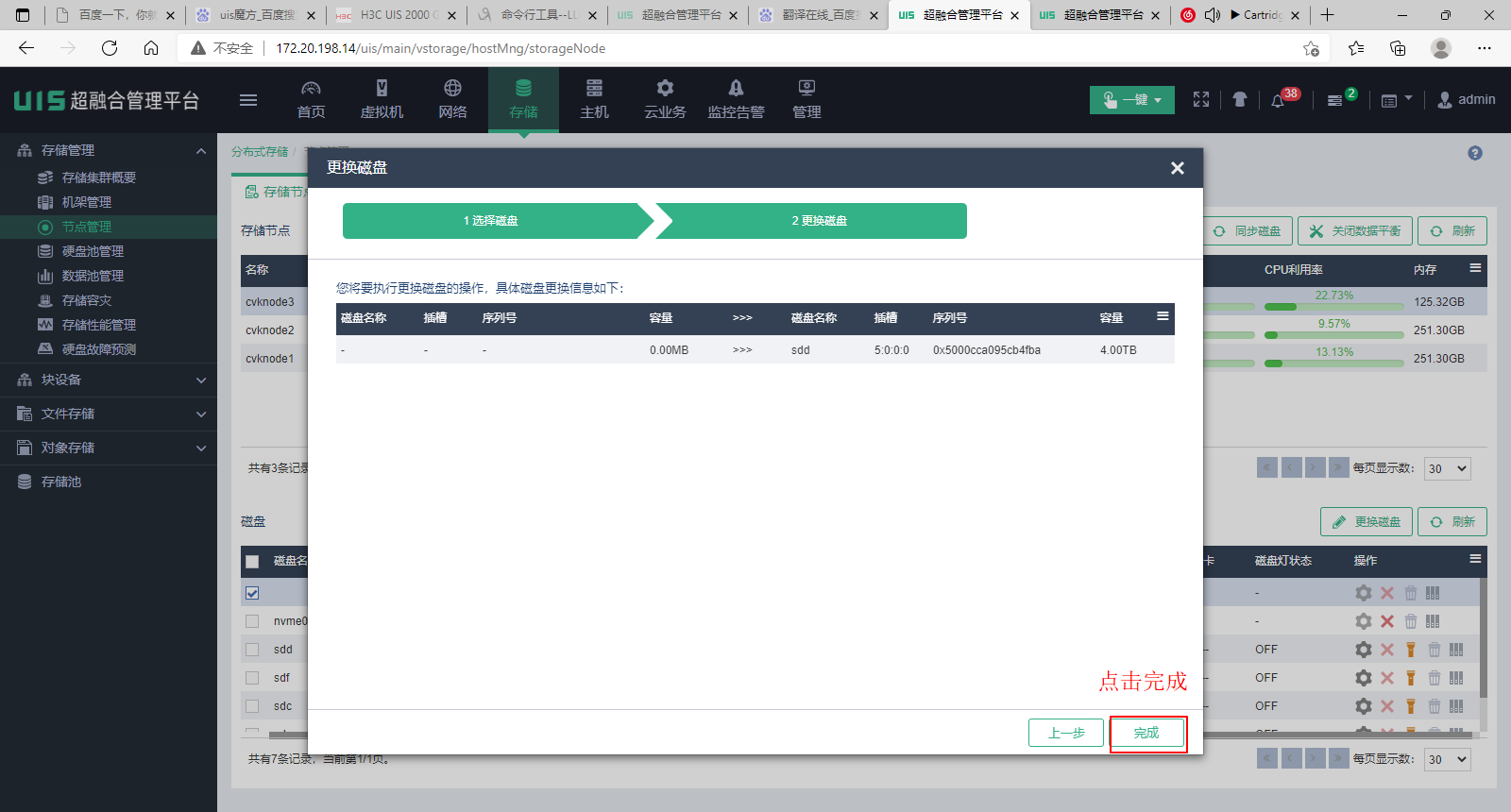
(10) 单击<完成>后,打开任务台查看进度,等待换盘任务完成。
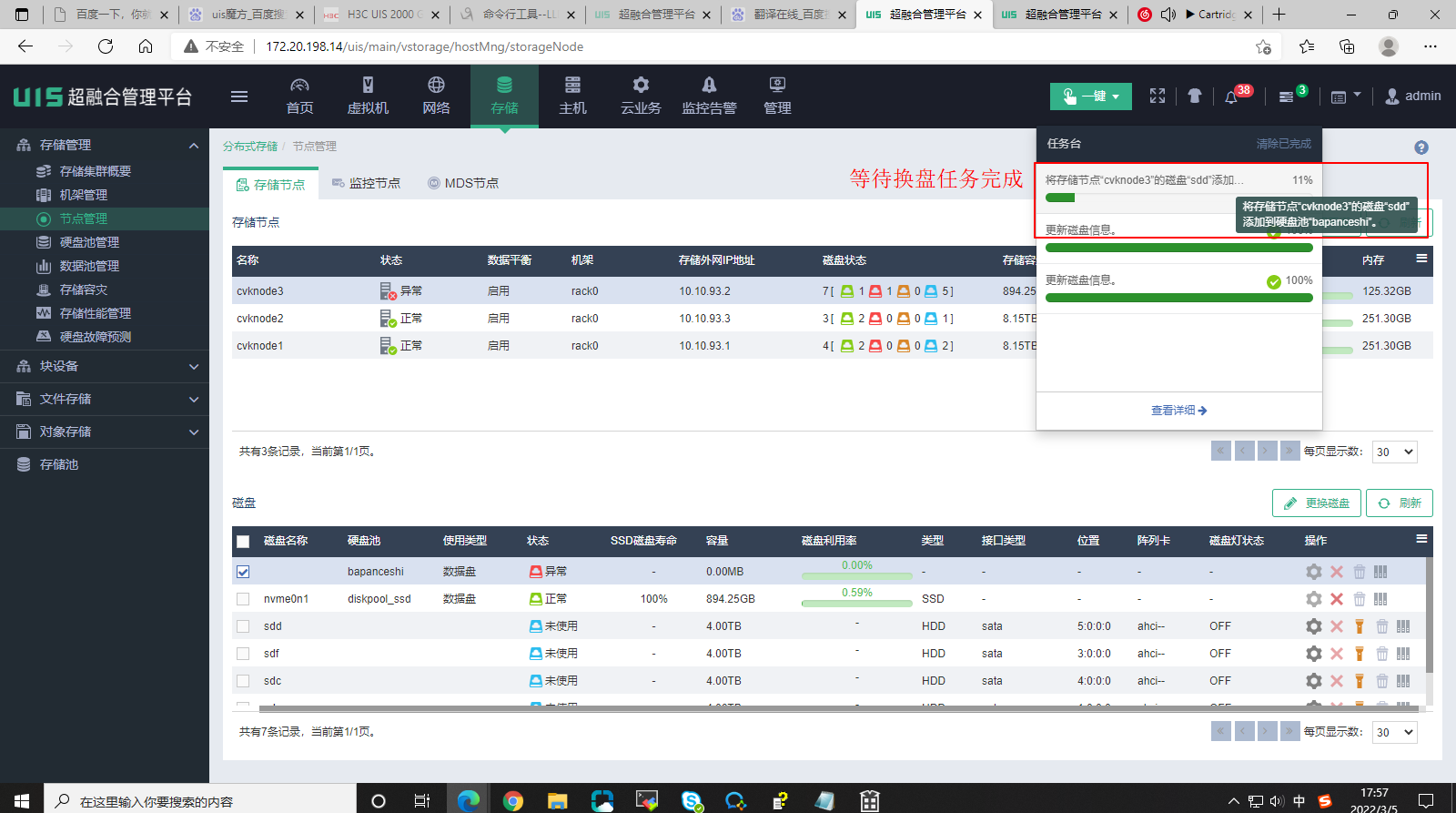
(11) 当换盘任务完成,单击存储节点和磁盘的<刷新>按钮可以看到存储节点和硬盘均显示为正常了。
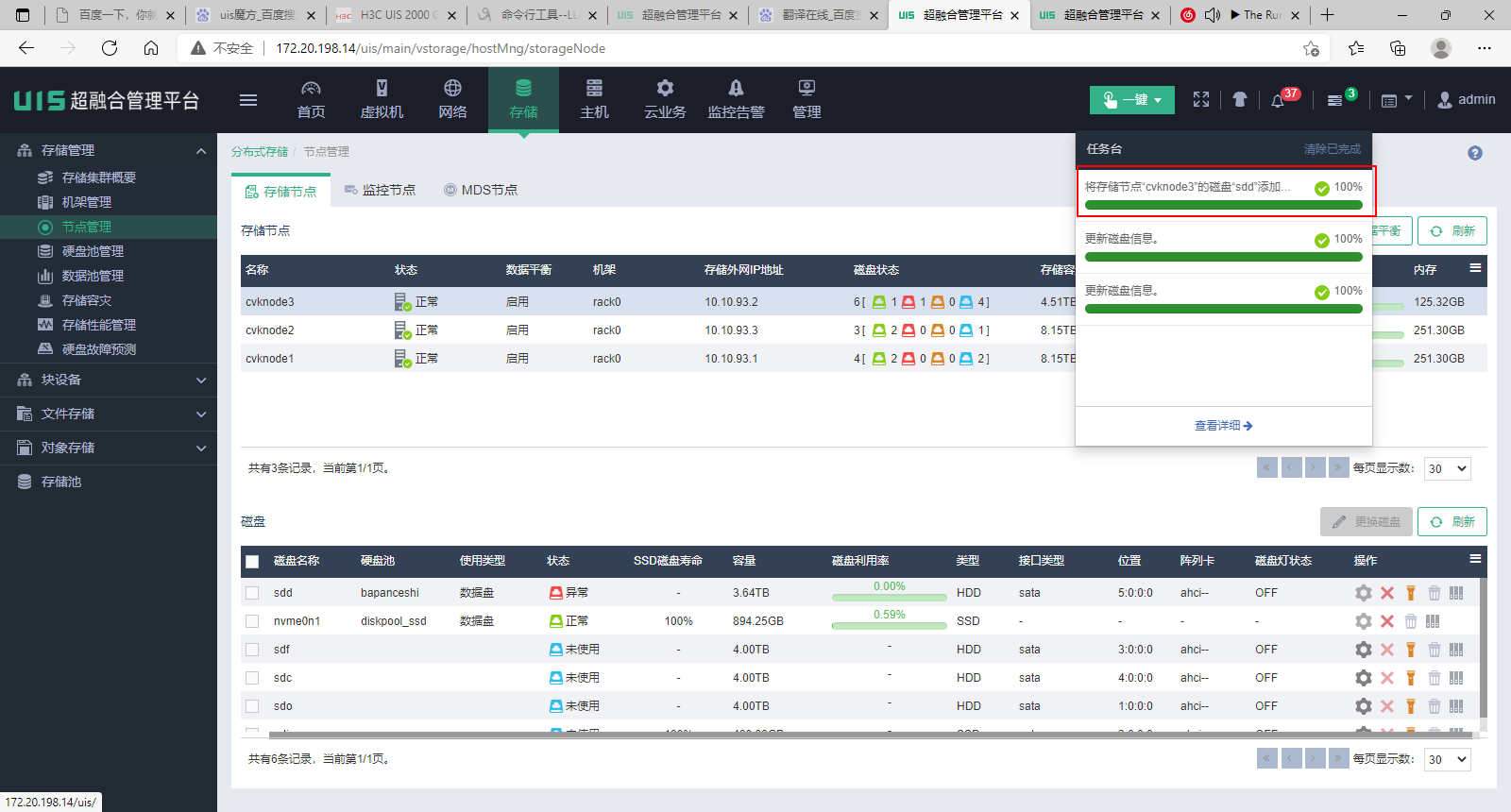
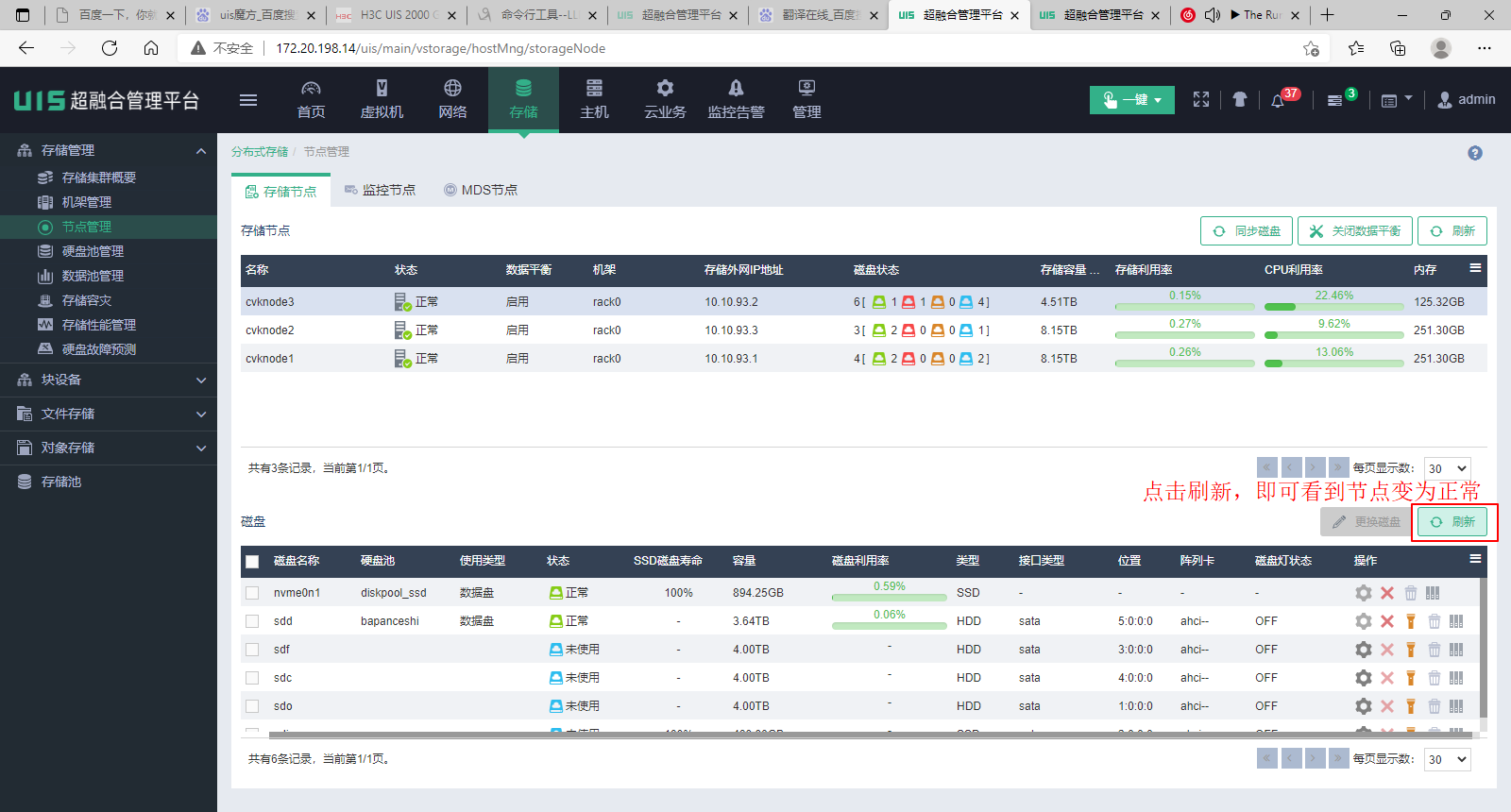
2.2 判断硬盘类型
硬盘类型分为系统盘、journal加速SSD、flashcache加速SSD、Scache加速SSD/NVMe以及数据盘几种类型。若更换硬盘时对硬盘类型不明确,请参考本章节进行判断。
· 如果已知待更换硬盘槽位号,但不知道硬盘在操作系统下的盘符,请参考本章节进行查询。
· 如果已知在操作系统下的盘符,请跳过本章节。
· 某些情况下硬盘彻底故障,会导致阵列完全离线,这种情形下系统下无法查询到盘符。若无法查询到盘符、又不知道待更换硬盘是什么类型,请联系技术服务获取帮助。
· 不同阵列卡型号的查询方法不同,请参考对应章节。
1. PMC阵列卡(PM8060)
(1) 首先查询阵列卡编号。执行arcconf list命令,输出信息中的Controller ID代表阵列卡编号。如图所示,查询到阵列卡编号为1。

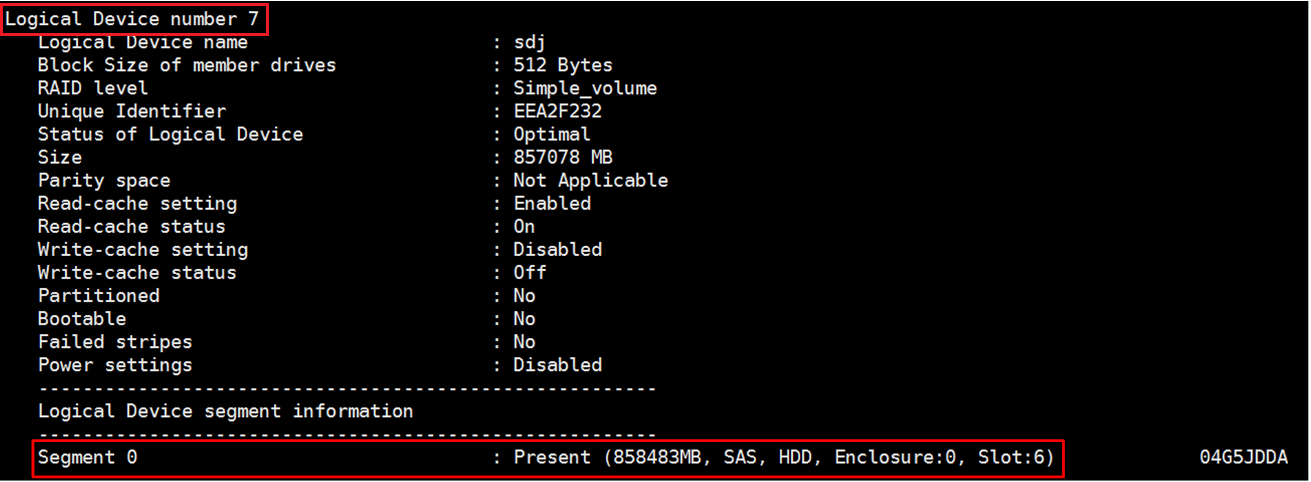
(2) 执行arcconf getconfig 1 ld命令(1为步骤1中查到的阵列卡编号),找到对应slot号的硬盘的Logical Device number。如图所示,查询到槽位号为Enclosure 0,Slot 6的硬盘对应的Logical Device Number为7。
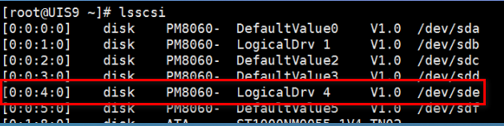
(3) 执行lsscsi命令,前面方括号中的4位数字中的第3位即为Logical Device Number,末尾的/dev/sdx表示此逻辑阵列在系统下对应的盘符。如图所示,查询到Logical Device Number为4的逻辑阵列,其在操作系统下对应的盘符为sde。
2. PMC阵列卡(P460)
(1) 首先查询阵列卡编号。执行arcconf list命令,输出信息中的Controller ID代表阵列卡编号。如图所示,查询到阵列卡编号为1。

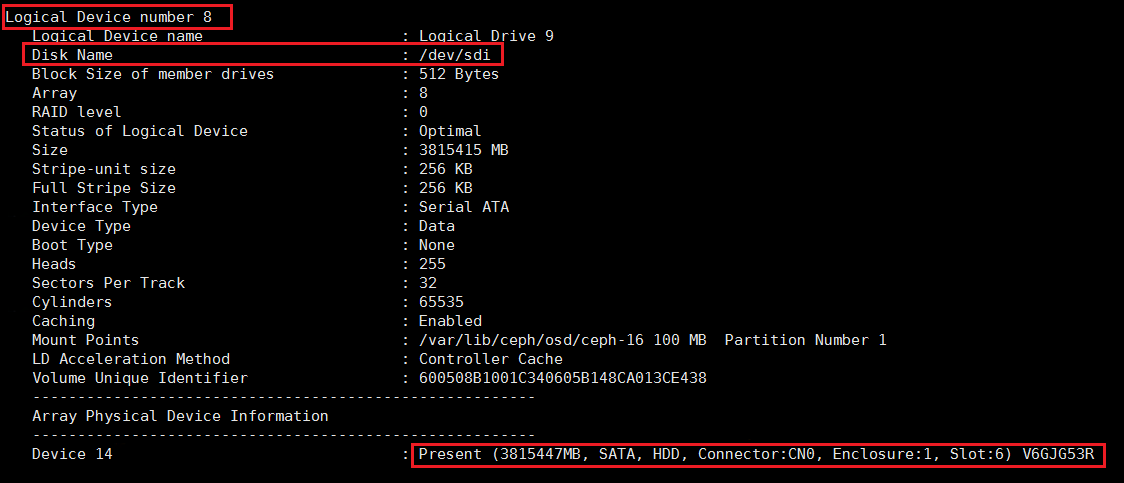
(2) 执行arcconf getconfig 1 ld命令(1为上一步中查到的阵列卡编号),找到对应slot号的硬盘的Logical Device number和Disk Name。如图所示,查询到槽位号为Enclosure 0,Slot 6的硬盘对应的Logical Device Number为8,其对应的Disk Name即为操作系统下的盘符sdi。
3. LSI阵列卡
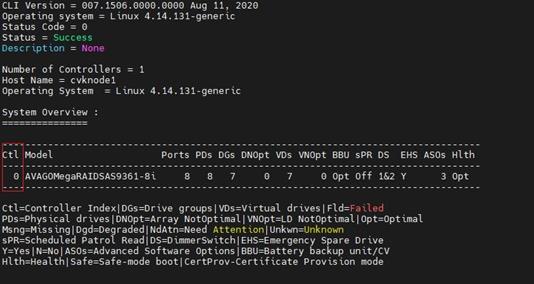
(1) 首先查询阵列卡编号,执行/opt/MegaRAID/storcli/storcli64 show命令,输出信息中的“Ctl”下方的数字代表阵列卡编号。如图所示,查询到阵列卡编号为0。
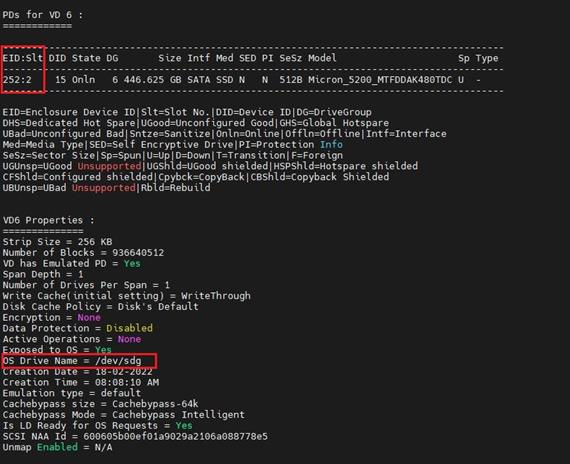
(2) 执行/opt/MegaRAID/storcli/storcli64 /c0 /vall show all命令(0为上一步中查询到的阵列卡编号),找到对应slot号的硬盘的Virtual Drive编号。如图所示,查询到槽位号为Enclosure 252,Slot 2的硬盘对应的Virtual Drive为3。
4. HP SSA阵列卡
(1) 首先查询阵列卡编号,执行ssacli ctrl all show命令,输出信息中的Slot号代表阵列卡编号。如图所示,查询到阵列卡编号为1。
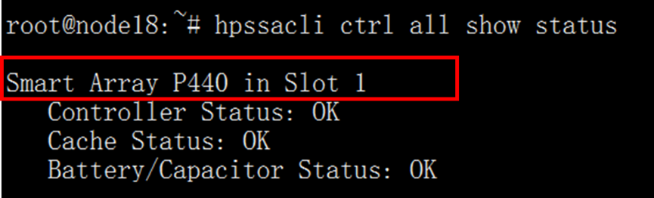
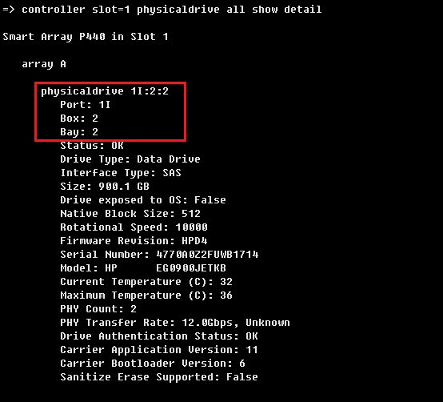
(2) 执行ssacli ctrl slot=x physicaldrive all show detail命令,显示物理盘slot号与逻辑阵列的对应关系。如图所示,1I:2:2对应的逻辑阵列为array A。
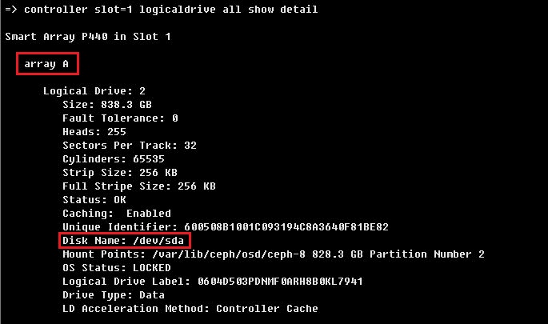
(3) 执行ssacli ctrl slot=x logicaldrive all show detail命令,显示对应的逻辑阵列编号和系统下盘符的对应关系。如图表示array A对应sda。
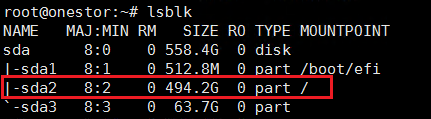
2.2.2 通过分区和挂载判断硬盘类型
1. 系统盘
执行lsblk命令,查看结果。有挂载到“/”的分区的磁盘为系统盘。如图sda为系统盘。
2. journal加速SSD
仅UIS 6.0版本会有journal加速SSD,UIS 6.5及以上版本不存在journal加速SSD。
执行lsblk命令,查看结果。journal加速SSD的第一个分区大小为15MB或16MB,其余的多个分区大小相同,且分区没有挂载。如图所示,sdf为journal加速SSD。
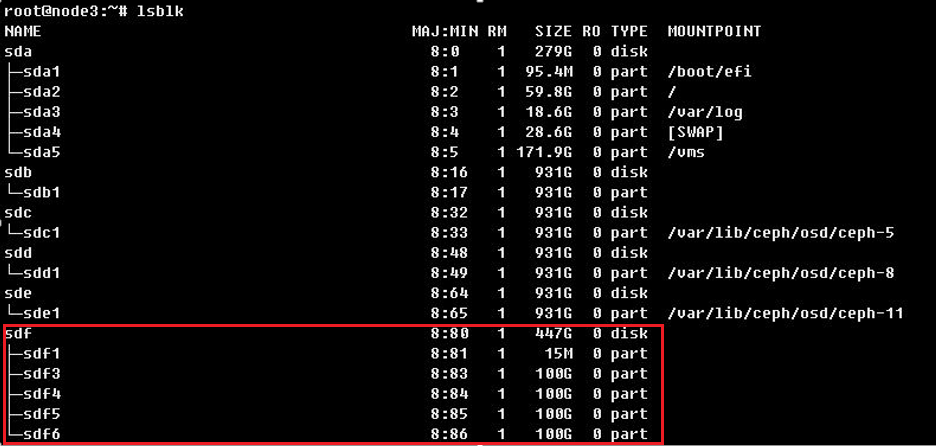
3. flashcache加速SSD
· UIS 6.0版本
执行lsblk命令,查看结果。flashcache加速SSD的第一个分区大小为15MB或16MB,其余的多个分区大小相同,且分区下有较长的uuid,其后显示挂载路径/var/lib/ceph/osd/ceph-x(x为osd编号)。如图所示,sdo为flashcache加速SSD。

· UIS 6.5及以上版本
执行lsblk命令,查看结果。flashcache加速SSD的第一个分区大小为15MB或16MB,其余的多个分区大小相同,且分区下有较长的uuid,其后没有挂载。如图sdo为flashcache加速SSD。

4. Scache加速SSD/NVMe
SSD盘给HDD盘做缓存加速以及NVMe盘给SSD盘做缓存加速两种情况的查询方法一致,仅盘符处存在区别。
(1) 执行lsblk命令。存在一个固定为2G的磁盘分区,以及另外两个被拆分的缓存分区,即为Scache加速缓存SSD,如本例中的sdd。
sdd 8:48 0 447.1G 0 disk
├─sdd2 8:50 0 132G 0 part
├─sdd3 8:51 0 66G 0 part
├─sdd1 8:49 0 16M 0 part
└─sdd4 8:52 0 2G 0 part
(2) 再执行fdisk-l命令,可以看到查询信息如下,可确认sdd为缓存加速分区。
[root@E0721P03Node1 ~]# fdisk -l /dev/sdd
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
# Start End Size Type Name
1 2048 34815 16M unknown scache default HDD
2 34816 276858879 132G unknown Flashcache
3 276858880 415270911 66G unknown ceph block.db
4 415270912 419465215 2G unknown ceph block.wal
5. 数据盘
(1) 执行lsblk命令,查看结果,查询信息与下图sdf类似的即为数据盘,可以看到对应的OSD编号。

(2) 如果无法找到故障盘,则需要执行mount|grep sdg(sdg指故障盘盘符)命令,可以查看OSD编号。
[root@cvknode1 ~]# mount |grep sdg
/dev/sdg1 on /var/lib/ceph/osd/ceph-2 type xfs (rw,noatime,attr2,inode64,noquota)
sdg 8:96 1 1.8T 0 disk
├─sdg1 8:97 1 100M 0 part /var/lib/ceph/osd/ceph-2
└─sdg2 8:98 1 1.8T 0 part
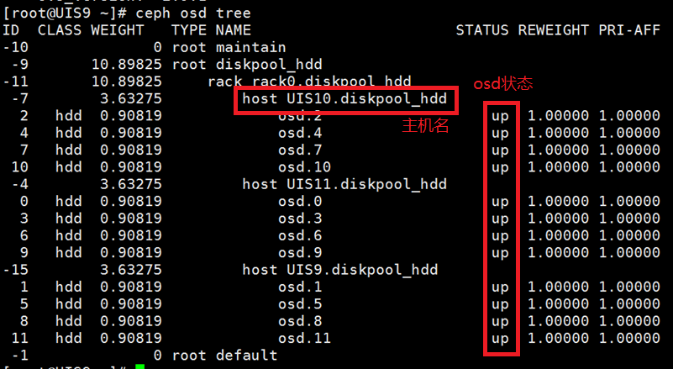
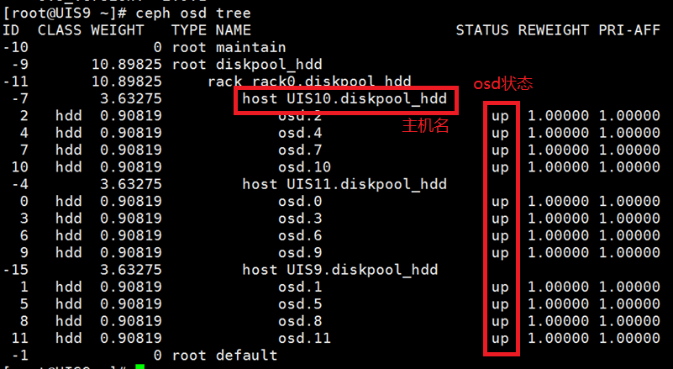
(3) 执行ceph osd tree命令,确认OSD2的状态处于DOWN,即可定位故障的数据盘。
[root@cvknode1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-10 0 root maintain
-9 7.84584 root diskpool_ssd
-11 7.84584 rack rack0.diskpool_ssd
-15 5.22926 host cvknode1.diskpool_ssd
2 ssd 1.74309 osd.2 down 1.00000 1.00000
5 ssd 1.74309 osd.5 up 1.00000 1.00000
6 ssd 1.74309 osd.6 up 1.00000 1.00000
-7 0.87219 host cvknode2.diskpool_ssd
1 ssd 0.43610 osd.1 up 1.00000 1.00000
4 ssd 0.43610 osd.4 up 1.00000 1.00000
进行换盘操作前,请务必执行本章的所有检查项,确认符合前置条件后,再进行更换硬盘操作。
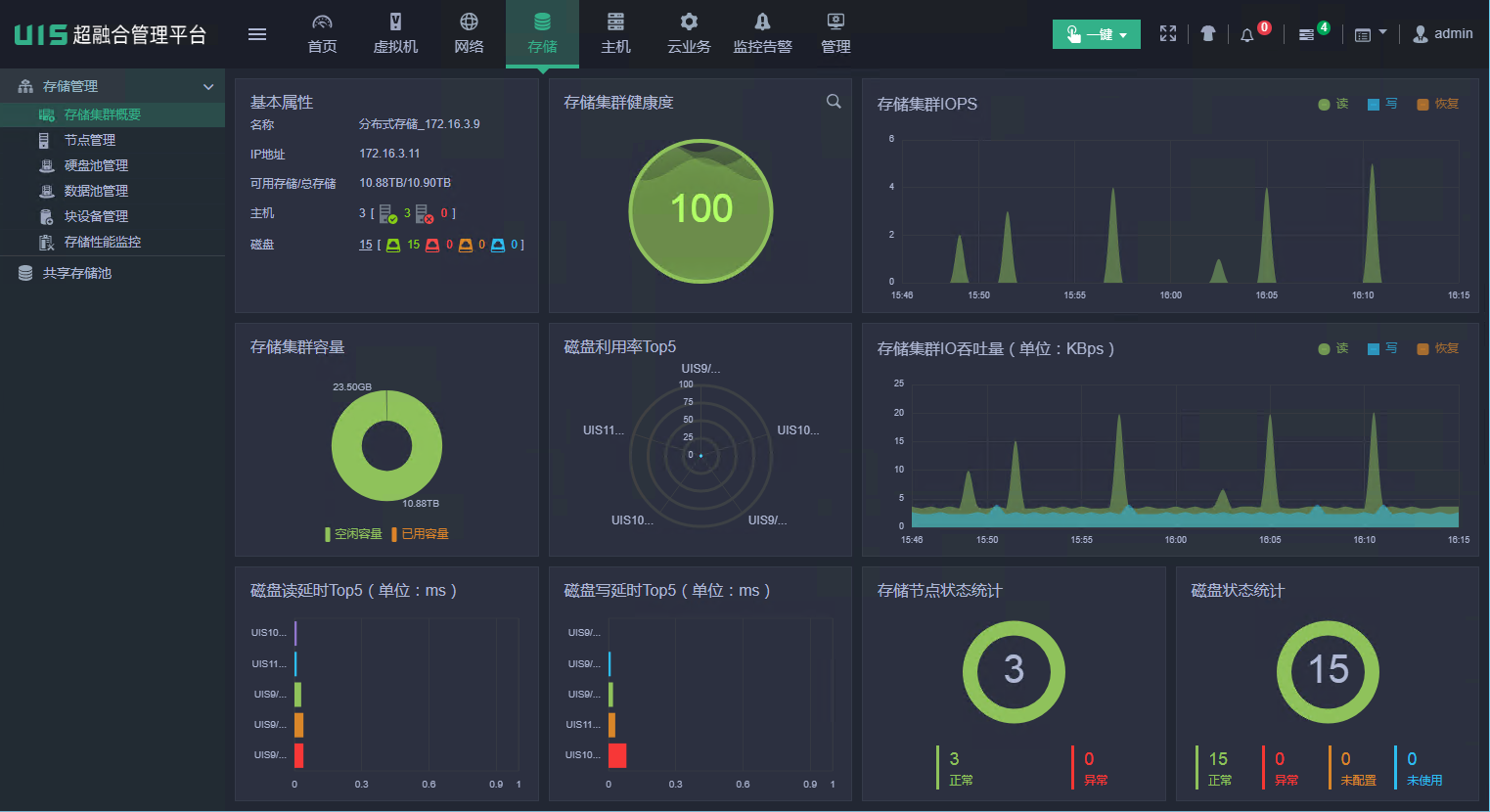
(1) 登录UIS管理页面,在“存储”页面,确认存储健康度为100%。若集群健康度不为100%,请等待集群自动恢复或排除故障后再操作。若等待一段时间仍然没有恢复进度,请联系技术支持。
图1 确认存储健康度
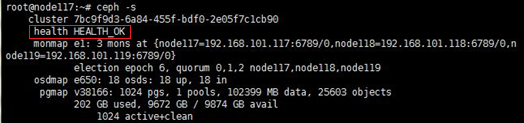
(2) 在集群中任意节点后台执行watch ceph –s命令持续观察集群健康状态,正常情况下状态为Health_OK。观察一分钟左右,确认健康状态正常。若健康状态不为Health_OK,请联系技术支持进行确认。
图2 后台确认集群健康状态
2.3.2 检查集群业务压力
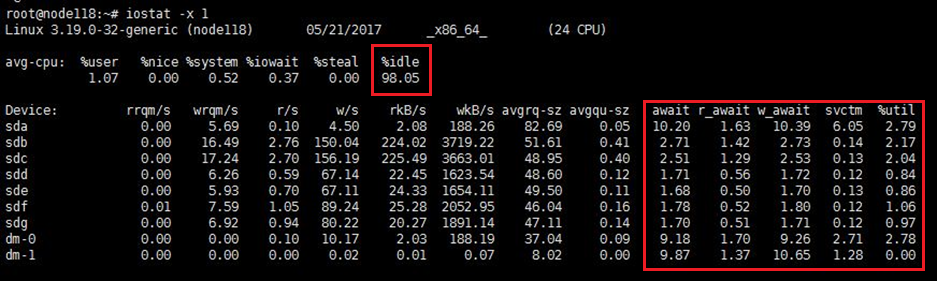
使用ssh登录至到集群中所有主机的后台。执行iostat -x 1命令,持续观察所有节点的CPU使用率和磁盘压力。该命令每秒会刷新输出iostat,建议每台主机观察2 min左右。
· 空闲的CPU %idle应该在40以上。
· %util(磁盘IO繁忙度)需在40%以下。
· svctm(平均每次IO请求的处理时间)需在20以下(单位为ms)。
· await(平均IO等待时间)和 r_await(平均读操作等待时间),以及w_await(平均写操作等待时间)需在20以下(单位为ms)。
如果偶有超过上限的情况,属于正常现象,但如果持续保持在上限以上,则需要等待业务压力变小或暂停部分业务,直到集群业务压力满足条件。
图3 iostat输出
2. 检查内存使用率
执行free –m命令检查内存使用率。内存使用率需要在80%以下。
内存使用率为第一行的used值与内存总容量的比值。
图4 内存使用情况

2.3.3 检查配置
以下操作在存储集群中每台服务器的后台执行。如果检查结果与预期不符,请联系技术支持处理。
1. PMC阵列卡(PM8060)
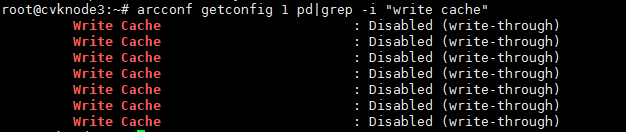
(1) 检查硬盘写缓存是否关闭。执行arcconf getconfig 1 pd | grep -i “write cache”命令(1为阵列卡编号,按实际情况修改),所有的输出结果应为Disabled (write-through)。
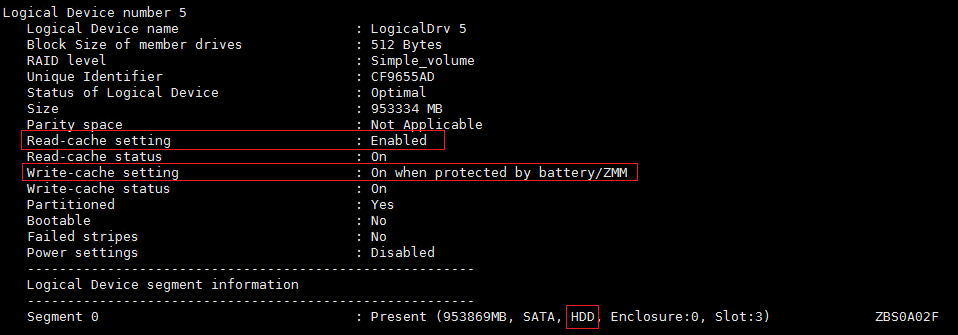
(2) 检查所有HDD阵列卡读写缓存是否开启并设置为掉电保护模式,所有SSD阵列卡读写缓存是否关闭。执行arcconf getconfig 1 ld命令,进行查询(1为阵列卡编号,按实际情况修改)。
¡ 对于HDD硬盘,如下为正常情况。
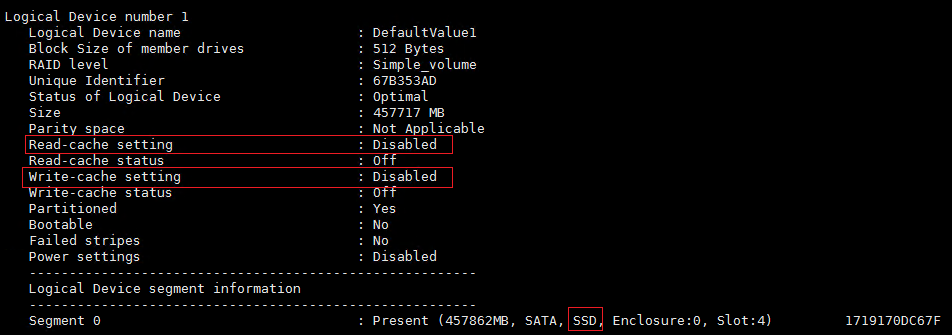
¡ 对于SSD硬盘,如下为正常情况。
2. PMC阵列卡(P460)
(1) 检查硬盘写缓存是否关闭。执行arcconf getconfig 1 ad |grep " Physical Drive Write Cache Policy Information" -A4命令(1为阵列卡编号,按实际情况修改),所有的输出结果应为Disabled。

(2) 检查所有HDD阵列卡读写缓存是否开启并设置为掉电保护模式,所有SSD阵列卡读写缓存是否关闭。
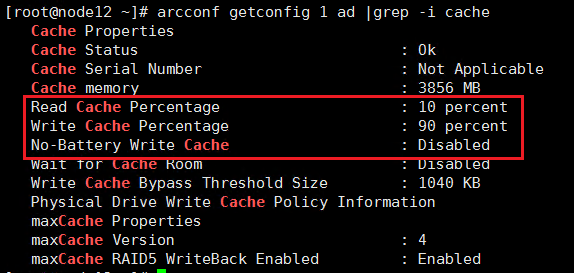
a. 首先执行arcconf getconfig 1 ad | grep -i cache命令,查询阵列卡配置(1为阵列卡编号,按实际情况修改),默认情况Read Cache为10%,Write Cache为90%,No-Battery Write Cache为Disabled。
b. 然后执行arcconf getconfig 1 ld命令,进行查询(1为阵列卡编号,按实际情况修改)。
- 对于HDD,如下为正常情况。
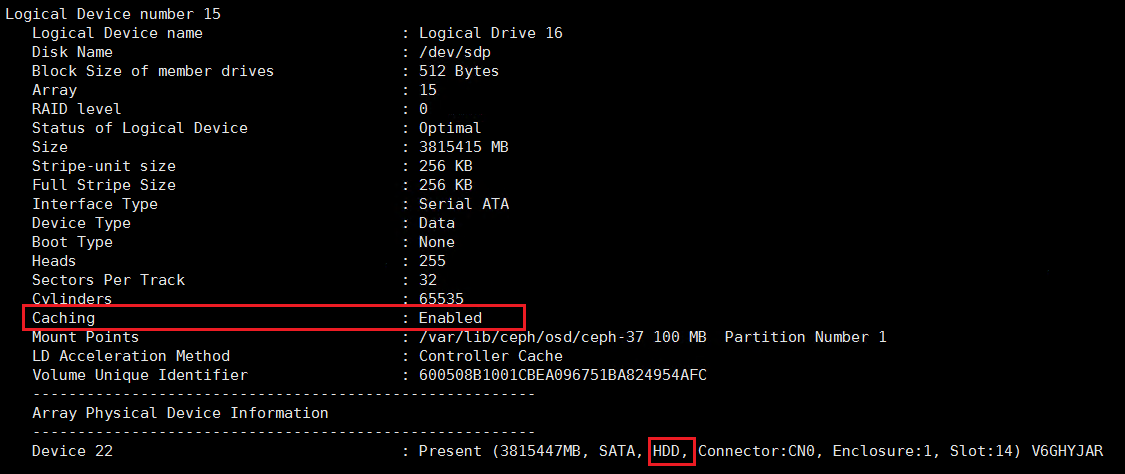
- 对于SSD,如下为正常情况。
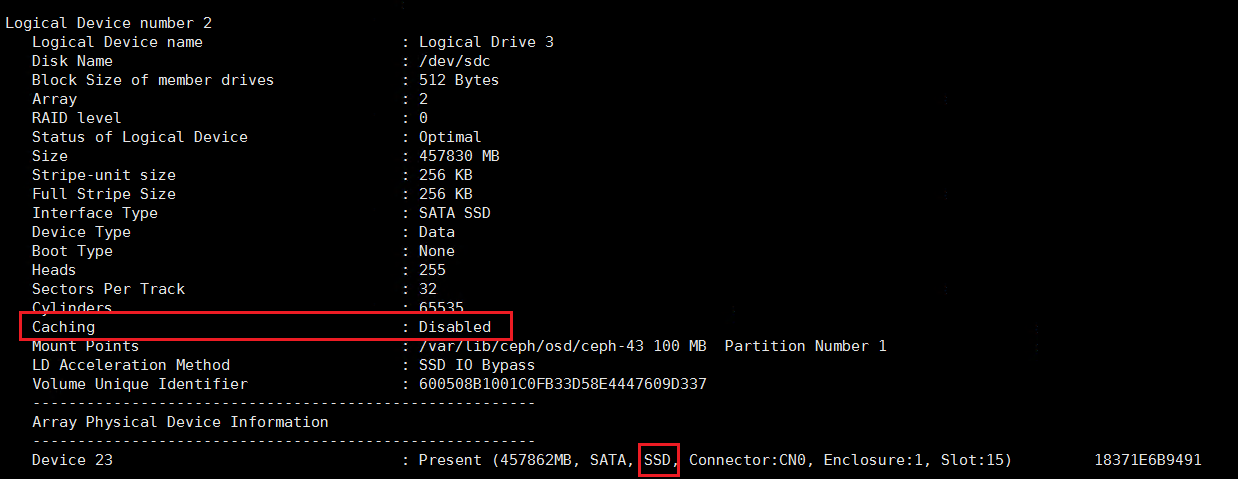
3. LSI阵列卡
检查硬盘写缓存和阵列卡缓存状态。执行/opt/MegaRAID/storcli/storcli64 /c0 /eall /sall show命令(0为阵列卡编号,按实际情况修改)。
· 对于HDD,如下为正常情况。
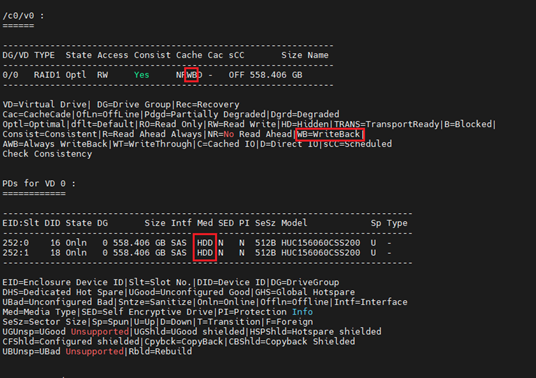
· 对于SSD,如下为正常情况。
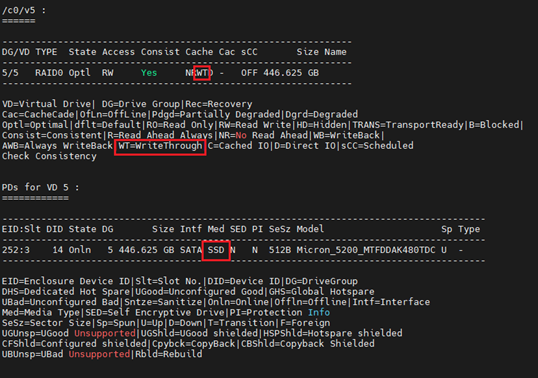
4. HP SSA阵列卡
(1) 检查硬盘写缓存是否关闭。执行ssacli ctrl all show config detail | grep -i cache命令,未做过特殊调整的情况下,Cache Ratio应为10%读,90%写;Drive Write Cache 应为Disabled;No-Battery Write Cache应为Disabled。
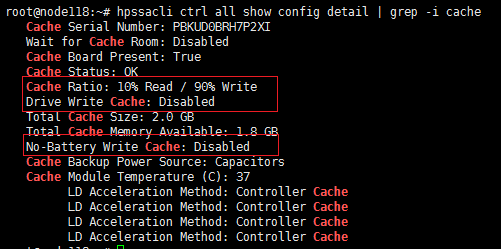
(2) 检查各阵列的缓存模式设置是否正确。执行ssacli ctrl slot=n ld all show detail命令(其中n为阵列卡槽位号,请按照实际情况修改),查看结果。
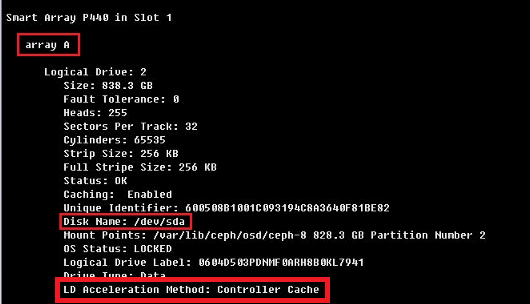
¡ 对于HDD,LD Acceleration Method应为Controller Cache。
¡ 对于SSD,LD Acceleration Method应为Disabled或Smart IO Path。
(3) 检查阵列卡是否设置为Max Performance模式。执行ssacli ctrl all show config detail | grep -i Power命令,其中Current Power Mode应设置为MaxPerformance模式。

2.3.4 检查集群硬件状态
登录集群中所有节点的HDM/iLO,检查是否有硬件报错。若有除了此次待更换的硬件之外的硬件报错,请联系技术支持确认。
2.4 硬盘更换
不同类型的硬盘对应的更换方法不同,请根据需要对应的硬盘类型参考相应的章节。
UIS 6.0及部分UIS 6.5版本的缓存盘的更换方法,请参考2.4.3或2.4.4章节。
UIS E0716及UIS 7.0版本的缓存盘更换方法,请参考2.4.5章节。
(1) UIS系统盘通常为RAID 1,在只有一块系统盘故障的情况下,拔下故障盘,插上新盘即可自动开始重建(可通过硬盘灯状态判断,具体参考服务器的用户手册)。若系统盘不为RAID 1,请联系技术支持处理。
(2) 若插上新盘后未自动重建,则需要重启后进入BIOS手动选择重建,关机及开机步骤请参照《H3C UIS超融合产品正常开关机配置指导》,在BIOS中选择重建的操作请参考对应机型的BIOS使用手册。
如果是管理节点或仲裁节点故障,请参考《H3C UIS超融合产品双机热备配置指导》中的“双机常用操作”章节进行恢复。如果是其他节点故障,需要先将故障节点在管理平台中移除,重装UIS软件后再将其加回集群机。
这种情况下系统分区中的数据(如/vms分区等)无法恢复。
(1) 将故障主机从管理平台中删除。单击顶部“主机”页签,选择左侧导航树的[主机管理]菜单项,选中对应的主机,进入该主机概要页面。单击<…更多操作>按钮,选择弹出下拉框的“删除主机”选项。
删除主机前请先确认主机中是否存在未被迁移的虚拟机。如有,请先联系技术支持处理遗留虚拟机,再更换硬盘、重装系统。
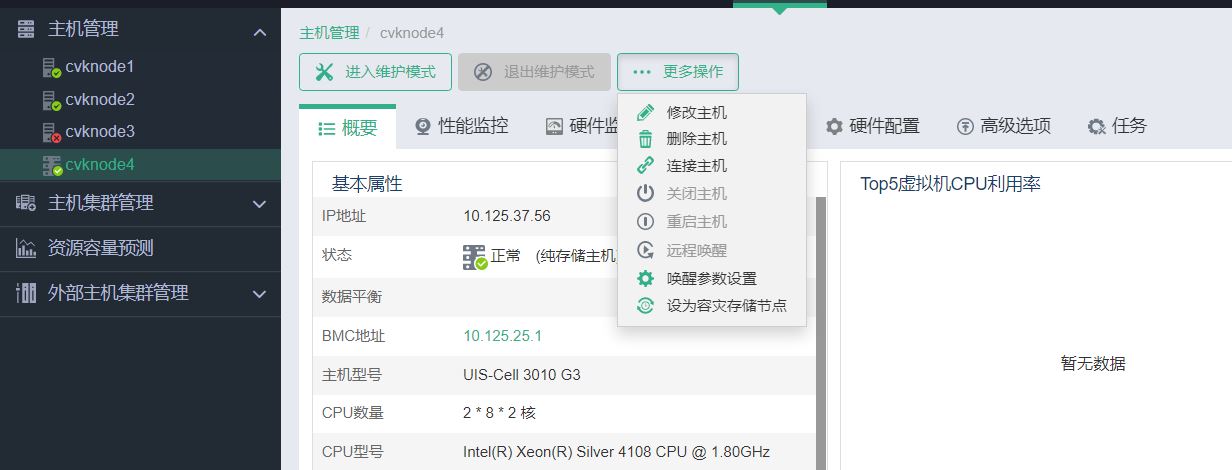
(2) 更换故障硬盘。如果系统盘已损坏,请更换主机中已损坏的硬盘。如果硬盘未损坏,则无需更换。
(3) 为主机重新安装与集群中其他主机相同版本的UIS软件,具体方法请参考对应版本的《H3C UIS超融合管理平台安装部署指导》。
(4) 安装完成后可将其加回集群,具体方法请参考《H3C UIS超融合产品扩容与缩容配置指导》中的“
集群主机扩容”章节。
3. 更换M.2 SSD系统盘
系统盘使用M.2 SSD硬盘时,由于这类硬盘内置在服务器中,无法通过常规的点灯识并插拔硬盘的方式进行换盘,需要关机后打开机箱更换硬盘,本章节主要介绍如何区分正常和故障的M.2 SSD硬盘。M.2 SSD系统盘更换的其他事项请参考2.4.1 1. 只有一块系统盘故障及2.4.1 2. 两块系统盘都故障章节。
图5 M.2 SSD硬盘

UIS一体机中通常只有两块M.2 SSD硬盘,分别插在插槽上的两侧。因此需要根据磁盘的S/N 号,确认需要更换的硬盘(故障盘)。本章节提供两种确认方法,如果两种方法均无法确认,请联系技术支持处理。
(1) 查询硬盘S/N号,区分正常硬盘和故障硬盘。
方法一:在UIS主机页面中确认
a. 选择顶部“主机”页签,进入主机管理信息页面。若系统中有多个集群,还需在左侧导航树选择目标主机所在的集群,进入主机集群管理页面。
b. 选择目标主机,进入主机的概要信息页面。选择“硬件监控”页签,进入主机硬件摘要信息页面。
c. 选择[硬盘]菜单项,进入主机硬件监控的硬盘信息页面,查询正常工作的硬盘。
d. 如图所示,M.2 SSD硬盘的“位置”参数显示为“/dev/sd*”,“阵列卡”参数显示为“-”,其中“序列号”参数即为M.2 SSD硬盘的S/N号。如果硬盘故障,通常在此页面无法查看到硬盘信息,可通过该方法区分正常硬盘和故障硬盘。
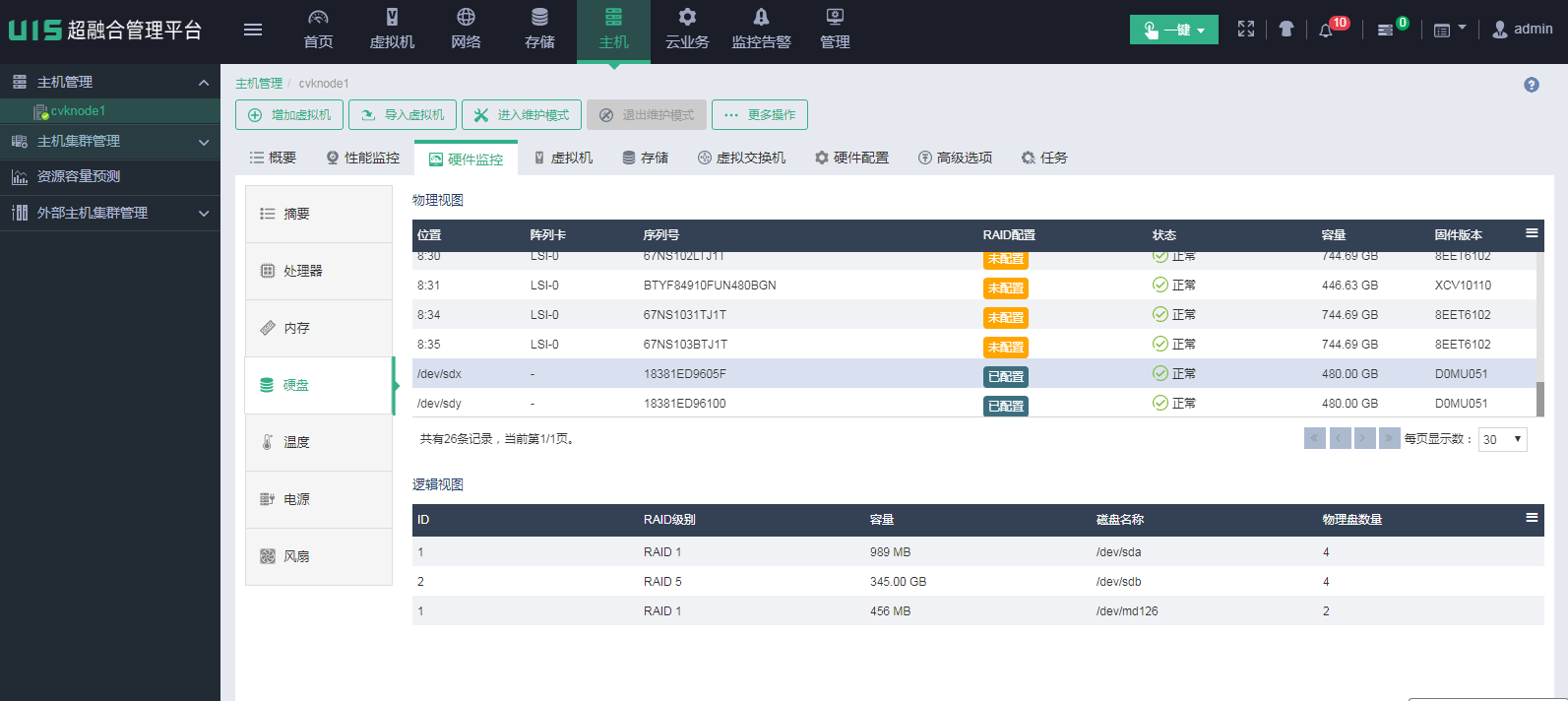
方法二:登录系统后台确认
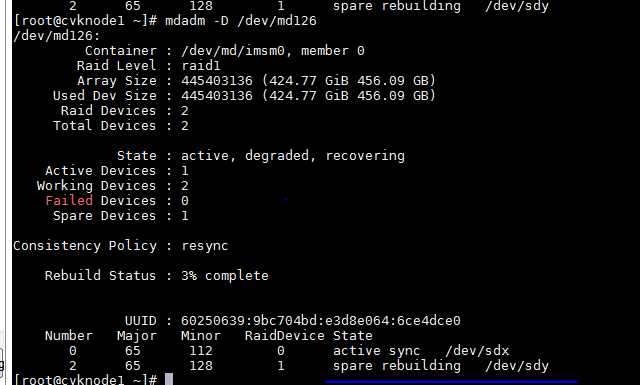
a. 登录系统后台,通过M.2 SSD硬盘的raid名称查看硬盘信息。例如,raid名称为md126,则执行mdadm –D /dev/md126命令,查看md126中的硬盘信息。如果硬盘信息的“State”处不为“active sync”则说明硬盘处于异常状态。
图7 查看硬盘信息
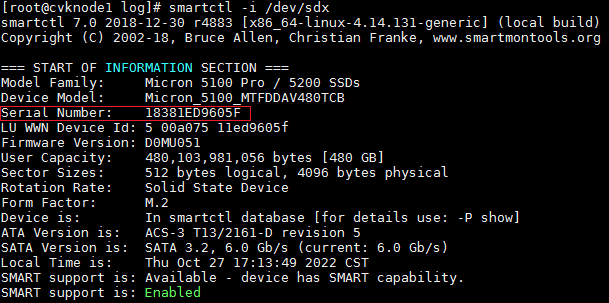
b. 查看正常硬盘的S/N号。执行smartctl -i /dev/sd*命令查看正常磁盘的S/N 号,sd*即为在上一步中查询到的信息。
图8 查看硬盘S/N号
c. 查询到正常硬盘的S/N号后,即可分辨正常硬盘和故障硬盘。
(2) 关闭一体机电源。
关机及开机步骤请参照《H3C UIS超融合产品正常开关机配置指导》。
(3) 根据查询到的S/N号,更换故障硬盘。
(4) 更换完成后开启主机。
更换硬盘前,需要先删除故障盘。
1. 通过前台页面删除故障盘
当故障硬盘的挂载路径丢失的情况下,在前台页面会无法删除,此情况下可以通过后台命令行删除。
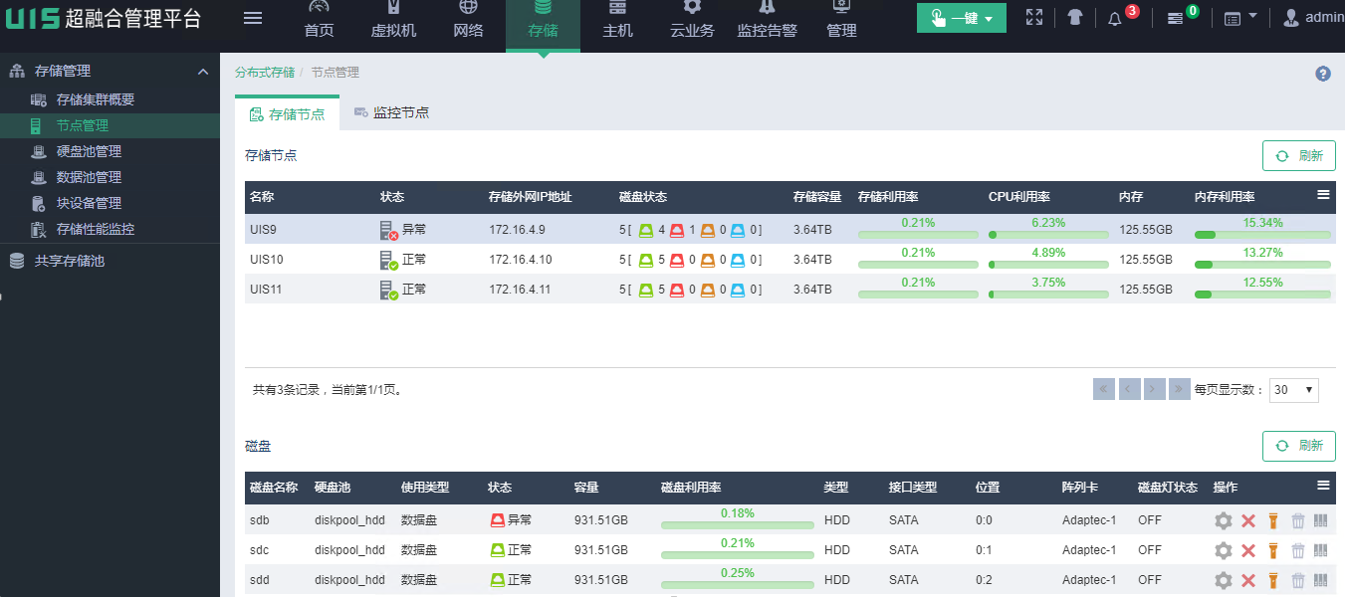
(1) 硬盘故障会,UIS主机硬盘状态会显示为异常。
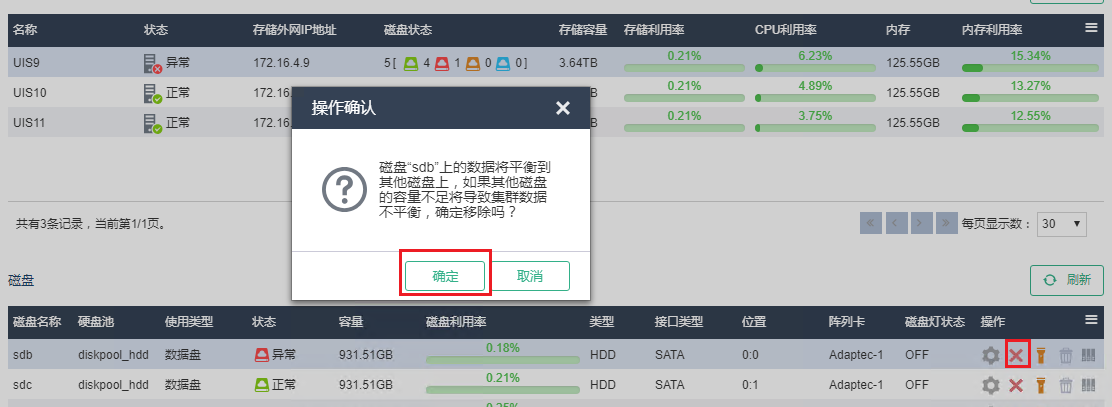
(2) 在前台页面删除故障硬盘:确保存储的健康度是100%,单击异常硬盘的删除按钮,等待删除过程完成。
每次只能在一个节点操作。删除完一个节点的故障盘后,需等待数据平衡完毕,才能继续删除其他节点的故障盘。考虑到数据平衡需要一定时间,建议在备件到达现场之前提前一天完成此操作。
2. UIS 6.0后台删除换分分区方法
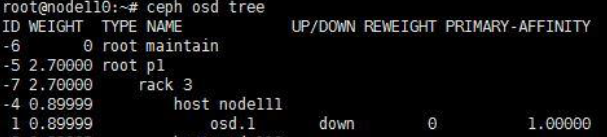
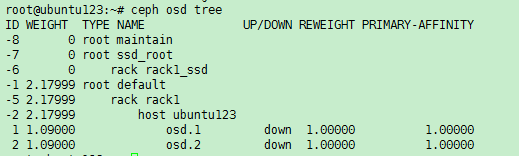
(1) 通过ssh方法登录到故障节点的后台,执行ceph osd tree命令,找到状态为down的osd编号,如图所示,故障的osd编号为1。
(2) 如果硬盘是带有journal或flashcache加速的数据盘,还需要找到对应的加速分区,待后续删除用。查询硬盘是否有journal或flashcache加速的方法请参考2.2.2 判断硬盘类型。
· 确认硬盘带有journal加速后,首先需要确定journal SSD上哪个分区是待更换硬盘对应的加速分区。
¡ 查询方法一(推荐):
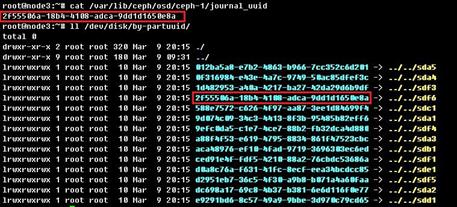
a. 执行cat /var/lib/ceph/osd/ceph-x/journal_uuid命令(x为故障的osd号),找出待删除硬盘缓存分区的uuid。
b. 执行ll /dev/disk/by-partuuid/命令,查看所有磁盘分区对应的uuid。
c. 在步骤b的输出结果中找到和步骤a相同的,该磁盘分区即为需要删除的写缓存分区。例如:下图中,sdf6即为待更换硬盘sdb对应的写缓存分区。
¡ 查询方法二:
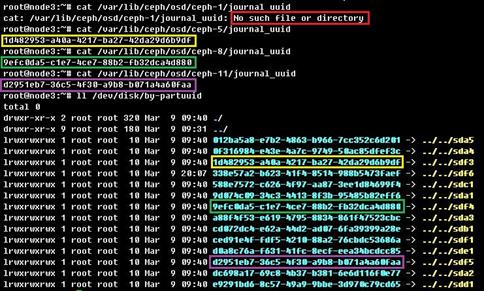
如果执行cat /var/lib/ceph/osd/ceph-x/journal_uuid命令查找不到,此时可以先对应出此台服务器上的其他活动的数据盘对应的写缓存分区,那么剩下没有对应关系的写缓存分区就是被删除的硬盘对应的写缓存分区了。
如下图所示,对应出osd.5的写缓存分区为sdf3,osd.8的写缓存分区为sdf4,osd.11的写缓存分区为sdf5,那么sdf上还剩下sdf1和sdf6,其中sdf1只有15M,是标识sdf为写缓存SSD的分区,因此sdf6就是被删除的硬盘的写缓存分区。
· 确认硬盘带有flashcache加速后,需要确定flashcache SSD上哪个分区是待更换硬盘对应的加速分区。
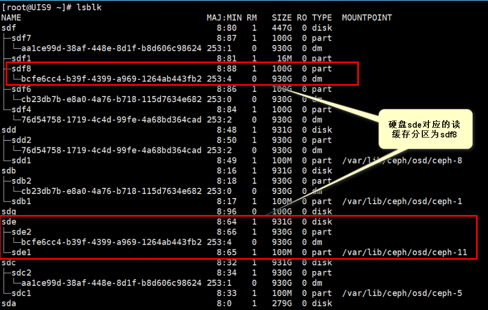
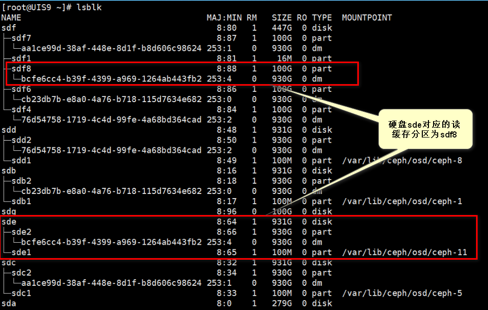
执行lsblk命令查看osd的挂载路径和软连接信息。例如下图中查询的osd.11对应的数据盘为sde,通过uuid比对,与sde下面的uuid相同的flashcache 加速分区为sdf8。
若使用此方法查询不到故障osd对应的uuid,则需要使用排除法,将所有正常的osd对应的flashcache加速分区找出来,那么剩下的加速分区则属于故障osd。
查询完毕之后,执行以下命令移除flashcache软连接。
umount /var/lib/ceph/osd/ceph-x//x为故障osd编号
dmsetup remove /dev/mapper/xxxx-xxxx-xxxx//xxxx-xxxx-xxxx为flashcache加速分区下的一长串uuid
(3) osd可能还有挂载残留,执行umount /var/lib/ceph/osd/ceph-x命令(其中x为osd编号,按照实际情况修改),取消挂载。如果执行此命令后提示“umount: /var/lib/ceph/osd/ceph-x: not mounted”,属于正常情况。
(4) 执行如下命令将osd删除。其中x为osd编号,按照实际情况修改,注意不要删错。
ceph osd crush remove osd.x
ceph auth del osd.x
ceph osd rm osd.x
(5) 将步骤2中查询到的加速SSD分区删除。
使用parted /dev/sdx和rm y命令(sdx为加速SSD的盘符,y为分区号,按实际情况修改),删除上文确认过的故障硬盘对应的读写缓存分区,如需要删除sdo2分区。
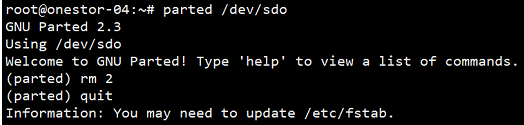
(6) 确认分区是否已经删除
(7) 删除完毕后,刷新管理界面查看,确认该故障盘已经消失,并等待集群健康度恢复100%。
3. UIS 6.5版本后台删除缓存分区方法
(1) 取消故障硬盘的挂载。
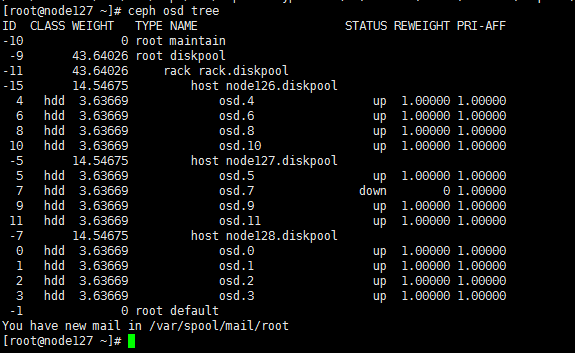
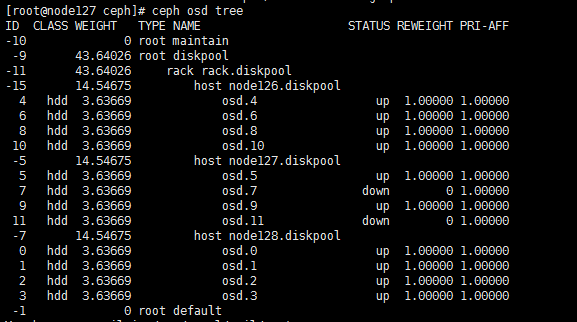
a. 通过ssh方法登录到该节点,执行ceph osd tree命令,查看故障的osd(如图中osd 7)。
b. 执行mount命令查看该osd的挂载信息。

c. 执行umount命令,取消被拔硬盘的挂载(图中以osd 7为例)。
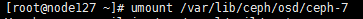
(2) 执行如下命令,将故障osd删除,其中x为osd编号,按照实际情况修改,注意不要删错。
ceph osd crush remove osd.x
ceph auth del osd.x
ceph osd rm osd.x
(3) 删除flashcache标识码和缓存盘上的缓存分区
a. 确认被故障盘的flashcahe 标识码。
若系统下已没有了故障盘的盘符,则可以执行lsblk | grep “缓存盘的flashcahce标识码”命令。结果只有1条记录的,则说明该flashcahce标识码为故障硬盘的flashcahce标识码,而唯一被挂载的分区为故障盘对应的读缓存分区。
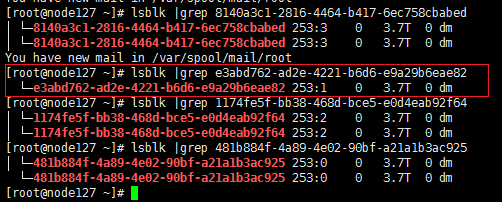
执行lsblk命令,查看缓存盘下flashcache的标识码。(如下图所示,两个SSD缓存盘sdk、sdj)。


执行lsblk |grep “flashcache标识码”命令,只有一条记录的即为被拔掉硬盘的flashcache分区的标识码,图中e3abd762-ad2e-4221-b6d6-e9a29b6eae82标识码即为故障盘对应的标识码,而对应的sdk2分区为故障盘对应的读缓存分区。
b. 使用命令ls /proc/sys/dev/flashcache命令,查看是否有残留的flashhcahde信息,如果有则删除。否则则跳过下一步。
执行ls /proc/sys/dev/flashcache |grep “flashcache标识码”命令,查找flashcache信息。

c. 执行如下命令,移除该硬盘上的flashcache信息。
sysctl -w dev.flashcache.f28c1e04-cf71-4853-b628-8017db519b4a+e3abd762-ad2e-4221-b6d6-e9a29b6eae82.fast_remove=1
dmsetup remove e3abd762-ad2e-4221-b6d6-e9a29b6eae82

d. 执行parted /dev/sdk -s rm 2命令,删除对应缓存盘的分区。

e. 检查缓存盘信息是否被删除干净。
执行lsblk命令,查看对应的缓存盘,(图中sdk的第二个分区已经被删除)

4. UIS 7.0版本(被Scache加速的数据盘)后台删除缓存分区方法
(1) 取消故障硬盘的挂载。
a. SSH登录到该节点,执行ceph osd tree命令,查看故障的osd(如图中osd 7)。
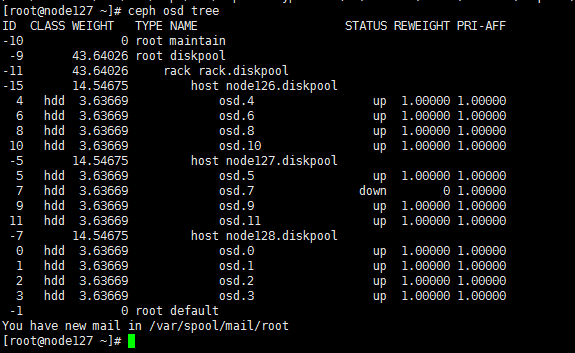
b. 执行mount命令,查看该osd的挂载信息。

(2) 插入的新盘做raid(如果使用NVMe硬盘,则不需要做raid),并且关闭硬盘缓存。
(3) 清除异常磁盘的残留osd信息。
umount /var/lib/ceph/osd/ceph-7 //删除osd 7
· 如果原磁盘异常之后,挂载也自动消失,可以不执行umount操作。
· 后台删除OSD的残留信息,会更新osdmap表,触发数据均衡。删除之后需要赶紧将新盘加回集群。
[root@node127 ~]# ceph osd crush remove osd.7
removed item names 'osd.7' from crush map
[root@node127 ~]# ceph auth del osd.7
updated
[root@node127 ~]# ceph osd rm osd.7
removed osd.8
(4) 找到异常磁盘的残留缓存加速分区。
UIS 7.0使用的是用户态的scache加速,与之前版本的内核态flashcache识别和删除缓存分区差异比较大。
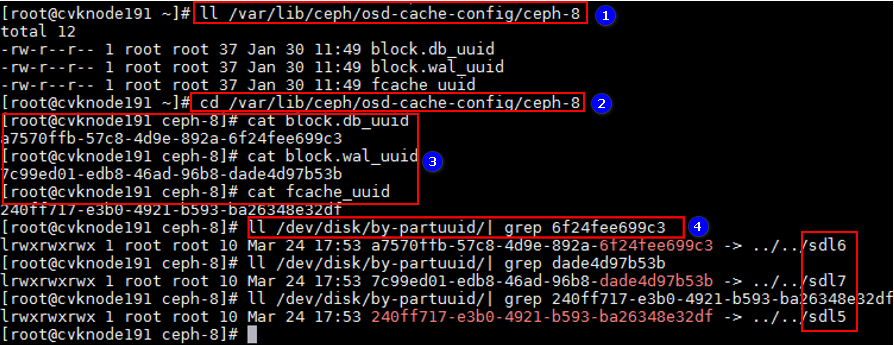
方法一:如图9所示,请依次执行如下命令,查询异常OSD对应的缓存分区。本例中故障盘对应的缓存分区为sdl5、sdl6、sdl7。
ll /var/lib/ceph/osd-cache-config/ceph-x
cd /var/lib/ceph/osd-cache-config/ceph-x
cat block.db_uuid
cat block.wal_uuid
cat fcache_uuid
如果当前使用的是老版本升级而来的环境,则仅需执行cat fcache_uuid这一条命令。删除缓存盘对应的分区时,也仅需要删除一个缓存分区。
图9 查询缓存分区
方法二
a. 缓存分区没有记录对应OSD的uuid。需要根据当前正常的OSD的缓存分区,反向排查找到异常磁盘的缓存分区。通过lsblk命令查看缓存盘盘符,本例中缓存盘盘符为sdl,该缓存盘共存在1~5五个分区。。
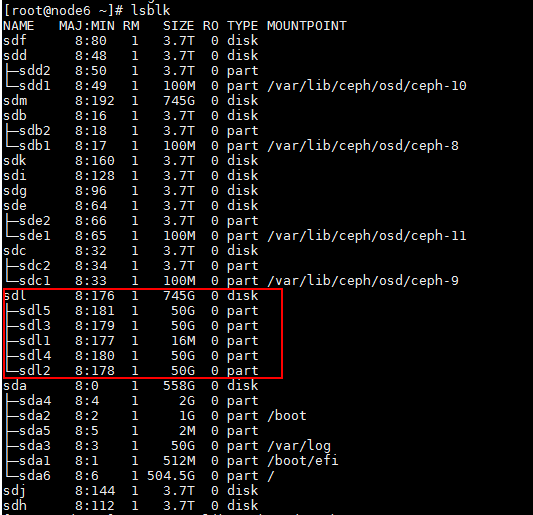
b. 执行for i in `cat /var/lib/ceph/osd/ceph-*/fcache_uuid`; do ll /dev/disk/by-partuuid/ | grep $i ; done命令,查询缓存赋能去信息,执行结果如下所示。

c. 根据该结果对比所有的缓存盘分区,该命令没有显示的非分区1的缓存分区也就是异常磁盘对应的分区。
(5) 删除异常磁盘的残留缓存加速分区。根据上一步反向排查找到的缓存分区(/dev/sdk2),删除osd.7对应的缓存分区。
执行sudo parted /dev/sdk -s rm 2命令,删除对应缓存盘的分区。
执行partprobe命令,更新磁盘分区信息。
(6) block.wal_uuid以及block.db_uuid对应的缓存分区,也需要对应处理。
如果磁盘已经被拔出或者异常,该挂载目录可能无法访问,需要反向通过已存在OSD的编号,找到异常磁盘对应的缓存分区。(E3322版本已经优化修改,就算磁盘异常也可以直接查询到异常磁盘的缓存分区ID),方法如下:通过3个命令依次查询该节点正常磁盘对应的缓存分区信息,
for i in `cat /var/lib/ceph/osd/ceph-*/fcache_uuid`; do ll /dev/disk/by-partuuid/ | grep $i ; done;
for i in `cat /var/lib/ceph/osd/ceph-*/block.wal_uuid`; do ll /dev/disk/by-partuuid/ | grep $i ; done;
for i in `cat /var/lib/ceph/osd/ceph-*/ block.db_uuid `; do ll /dev/disk/by-partuuid/ | grep $i ; done;
上述结果和lsblk 查询所有的缓存分区的分区进行对比,没有显示的非分区1的缓存分区就是异常缓存盘对应的分区。
5. 拔下故障盘,换上新盘
PMC阵列卡或HP SSA阵列卡
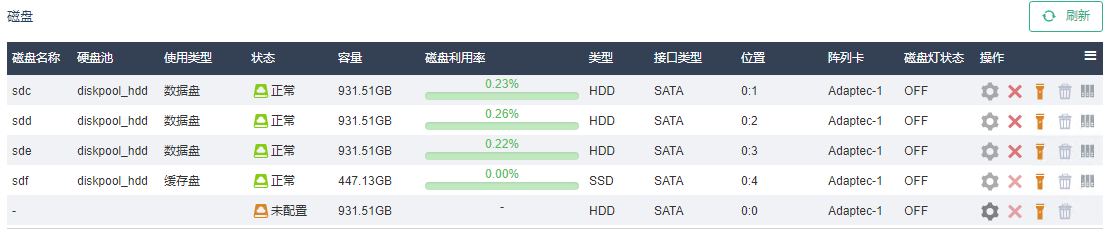
(1) 若故障盘已经亮橙灯,则直接插拔即可。
(2) 若故障盘未亮灯,可以在管理界面单击磁盘右侧点灯按钮点亮硬盘灯。若单击按钮无法点亮硬盘灯,请联系技术支持处理。
(3) 拔下故障盘,换上新盘。
(4) 更换完毕后,界面上会出现一块“未配置”状态的新盘。单击右侧“配置”按钮,将其加入集群。若此步骤执行失败,请联系技术支持进行处理。
LSI阵列卡
(1) 若故障盘已经亮橙灯,则直接插拔即可。
(2) 若故障盘未亮灯,可以在管理界面单击磁盘右侧点灯按钮点亮硬盘灯。
(3) 拔下故障盘,换上新盘。
(4) 清除缓存残留数据。执行/opt/MegaRAID/storcli/storcli64 /cN show preservedcache(N代表阵列卡编号,按实际情况修改)命令,获取残留缓存所属的逻辑阵列编号,如图表示残留缓存属于逻辑阵列1。
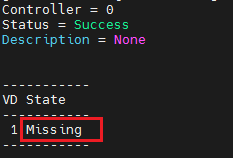
(5) 然后执行/opt/MegaRAID/storcli/storcli64 /cN /vx delete preservedcache(N代表阵列卡编号,x为上一条命令查询到的逻辑阵列编号,按实际情况修改)命令清除残留数据。

(6) 更换完毕后,界面上会出现一块状态为“未配置”的新磁盘。单击右侧<配置>按钮,将其加入集群。
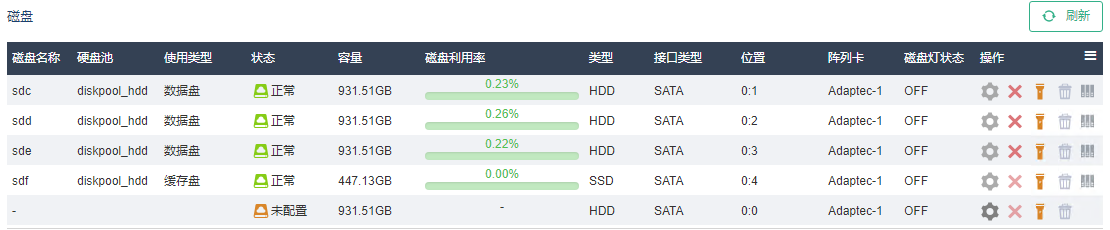
2.4.3 缓存加速盘更换-journal加速SSD
1. 拔下故障盘,换上新盘
参考2.4.2 5. 拔下故障盘,换上新盘进行操作。
2. 恢复journal 加速盘的分区
journal 加速SSD故障后,原本它加速的所有OSD都会down(如果没有业务的情况下down会有延迟)。
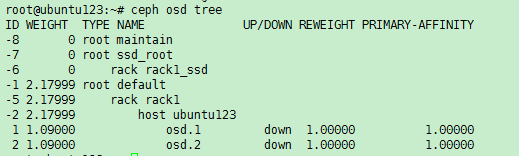
(1) 执行ceph osd tree命令,定位down状态的OSD号,如图所示,osd.1和osd.2状态为down,进行记录。
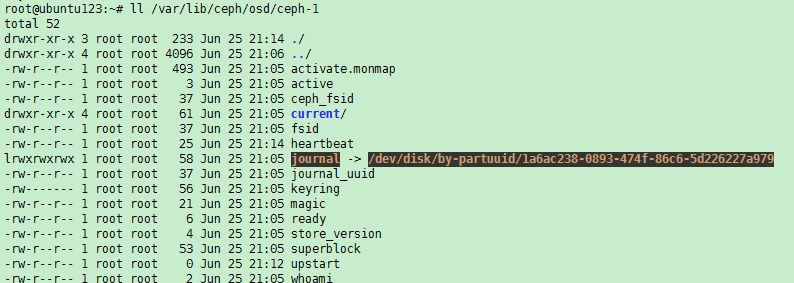
(2) 执行ll /var/lib/ceph/osd/ceph-1命令,分别查看这些OSD的目录,可以看到软连接为红色,即为损坏状态。
(3) 手动创建SSD盘的第一个16M分区。
执行ceph-disk marktype --journal --dev /dev/sdx(其中sdx为新换上的SSD的盘符,按照实际情况修改)命令。
(4) 创建脚本文件,执行vim makejournalssd.sh命令,将以下内容写入脚本文件中。
#!/bin/bash
osds="1 2"
journal_disk=/dev/sdp
num=2
for osd_id in $osds ; do
journal_uuid=$(sudo cat /var/lib/ceph/osd/ceph-$osd_id/journal_uuid)
sgdisk --new=$num:0:+10240M --change-name=$num:'ceph journal' --partition-guid=$num:$journal_uuid --typecode=$num:45b0969e-9b03-4f30-b4c6-b4b80ceff106 --mbrtogpt $journal_disk
num=$(($num+1))
done
其中,osds=”1 2”这里的数字代表之前查询到的down掉的osd编号,journal_disk=/dev/sdp代表新换上的SSD的盘符,10240M为此前的journal SSD上每个分区的大小,按照实际情况修改。
(5) 创建完毕后,执行bash makejournalssd.sh命令,恢复journal SSD的分区。
(1) 需要在主机上创建脚本,执行vim addjournalssd.sh命令,将以下内容写入脚本文件中。
#!/bin/bash
osds="1 2"
journal_disk=/dev/sdp
num=1
for osd_id in $osds ; do
sudo ceph-osd --mkjournal -i $osd_id
sudo start ceph-osd id=$osd_id
num=$(($num+1))
done
其中osds=”1 2”这里的数字代表之前查询到的down掉的osd编号,journal_disk=/dev/sdp代表新换上的SSD的盘符,按照实际情况修改。
(2) 创建完毕后,执行bash addjournalssd.sh命令。完成后,执行ceph osd tree命令查询,down掉的osd均已恢复up且in的状态。等待数据迁移至平衡后,集群恢复健康。
(1) 执行lsblk命令,查看待更换的flashcache SSD盘分区下的16进制字符组成的软连接。
(2) 比较软连接,相同的则代表有对应关系。
如示例中硬盘sde,对应的读缓存分区为sdf8,且sde的挂载路径为/var/lib/ceph/osd/ceph-11,表示sde对应了osd.11。记录下这里的数据盘盘符及对应的osd编号。
如果flashcahce SSD在系统下已经无法查询到,则联系技术支持确认环境中的对应关系。
当flashcahce SSD故障后,所有被其加速的OSD均down。
(3) 执行ceph osd tree命令,找到down状态的osd号,如图为osd.1和osd.2,进行记录。正常情况下,这里查到的osd编号应该与上一步中找到的数据盘一一对应(例如sde对应osd.11)。
(4) 删除这些down掉的osd,具体方法参考2.4.2 1. 通过前台页面删除故障盘。
(5) 然后执行以下两条命令删除软连接:
umount /var/lib/ceph/osd/ceph-x//x为故障加速盘所加速的osd编号
dmsetup remove /dev/mapper/xxxx-xxxx-xxxx//xxxx-xxxx-xxxx为flashcache加速分区下的一长串uuid
2. 拔下故障盘,换上新盘
参考2.4.2 5. 拔下故障盘,换上新盘进行操作。
(1) 将数据盘格式化。
(2) 执行ceph-disk zap /dev/sdx命令,格式化数据盘。
注意:sdx为2.4.4 1. 删除数据盘,并删除flashcache软连接中查找到的数据盘盘符,请严格按查找到的盘符操作,切勿写错。此命令会清除这块数据盘上的所有数据。
(3) 将数据盘重新加回集群。参考2.4.2 5. 拔下故障盘,换上新盘进行操作。
1. 删除数据盘,并删除Scache软连接
(1) 执行ceph osd tree命令查看故障的硬盘,发现被缓存盘加速的数据盘OSD 状态为DOWN。
(2) 删除数据盘对应的scache信息。反向查找异常磁盘对应的scache信息。
缓存盘异常更换新盘对应缓存盘的分区是空的,执行该步骤主要是再次确认信息。
异常缓存盘所在的节点后台执行如下命令:
for i in `cat /var/lib/ceph/osd/ceph-*/fcache_uuid`
do ll /dev/disk/by-partuuid/ | grep $i ; done
上述结果和lsblk查询所有的缓存分区的分区进行对比,没有显示的分区就是异常缓存盘对应的分区。
(3) umount对应的OSD目录,然后删除被缓存加速的数据盘osd的残留信息。
OSD的删除会造成集群性能下降,建议在离线的情况下进行。如果有在线拔插硬盘的需求,请及时联系总部评估对性能的影响!
#删除osd 7
[root@node127 ~]# umount /var/lib/ceph/osd/ceph-7
[root@node127 ~]# ceph osd crush remove osd.7
removed item names 'osd.7' from crush map
[root@node127 ~]# ceph auth del osd.7
updated
[root@node127 ~]# ceph osd rm osd.7
removed osd.7
#删除osd 11
[root@node127 ~]# umount /var/lib/ceph/osd/ceph-11
[root@node127 ~]# ceph osd crush remove osd.11
removed item names 'osd.11' from crush map
[root@node127 ~]# ceph auth del osd.11
updated
[root@node127 ~]# ceph osd rm osd.11
removed osd.7
(4) 格式化对应的数据盘,本例中osd.7和osd.11分别对应/dev/sdf和/dev/sdg。
[root@node127 ~]# ceph-disk zap /dev/sdf
[root@node127 ~]# ceph-disk zap /dev/sdg
2. 拔下故障盘,换上新盘
参考2.4.2 5. 拔下故障盘,换上新盘进行操作。
3. 将数据盘重新加回集群
(1) 将数据盘重新加回集群。参考2.4.2 5. 拔下故障盘,换上新盘进行操作。
(2) 等待集群恢复平衡后,SSD硬盘即可更换成功。
更换完毕后,待数据平衡完毕、存储状态恢复100%后,在UIS管理界面执行一键巡检,若无报错表示更换成功。若有报错,可通过报错提示判断报错原因。若无法确认,请联系技术支持确认。
3 更换非热插拔部件
UIS一体机的中CPU、内存等部件不支持热插拔更换,请根据本章节进行更换此类部件。
在更换部件前,请务必执行本章的所有检查项,确认符合前置条件后,再进行操作。检查方法请参考2.3 操作前检查。
若故障节点未因硬件故障导致宕机,则参考本小节操作。
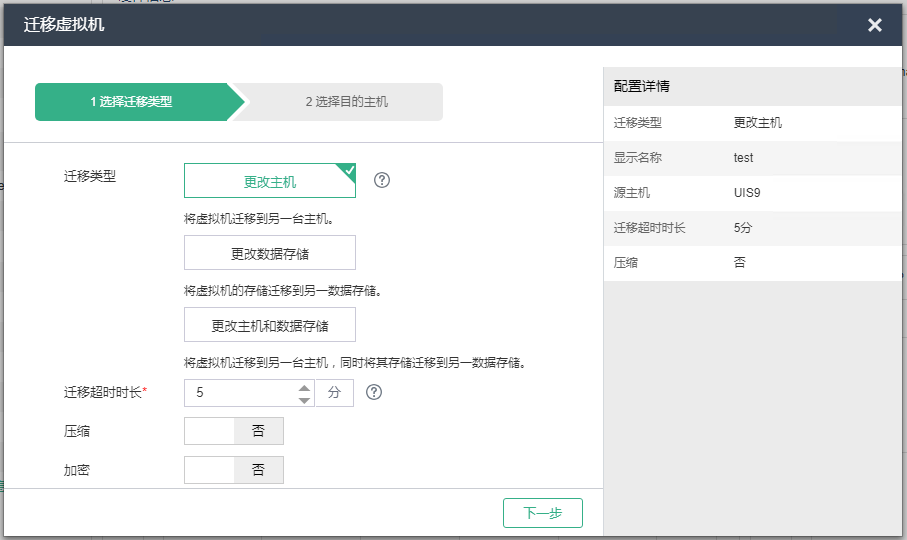
将待关机节点的虚拟机以更改主机方式迁移到其他节点。
(1) 选择顶部“虚拟机”页签,若系统中有多个集群,还需在左侧导航树选择目标集群,进入虚拟机管理页面。
(2) 选择目标虚拟机,在虚拟机卡片上单击<更多>按钮,选择[迁移]菜单项或者进入虚拟机概要信息页面,单击<迁移>按钮,弹出迁移虚拟机对话框。
(3) 根据配置向导完成虚拟机的迁移,迁移类型需选择更改主机。
迁移超时时长建议设置为0,防止虚拟机因迁移超时而暂停。
3.2.2 暂停共享存储池
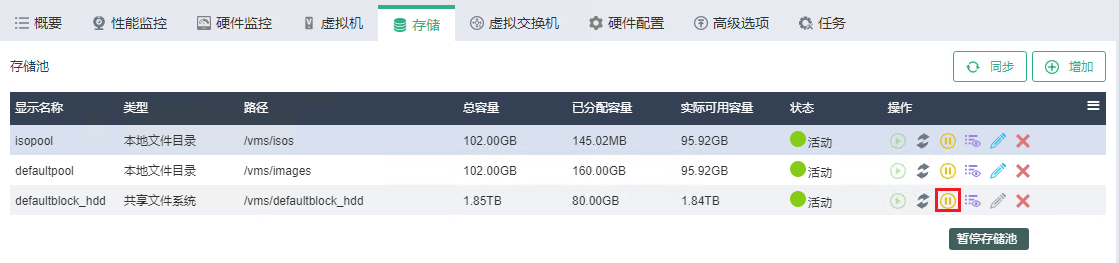
将故障主机上的所有共享存储池暂停。
(1) 选择顶部“主机”页签,进入主机管理信息页面。若系统中有多个集群,还需在左侧导航树选择目标主机所在的集群,进入主机集群管理页面。
(2) 选择故障主机,进入主机的概要信息页面。选择“存储”页签,进入主机的存储池列表页面。
(3) 在存储池列表中选择类型为的存储池“共享文件系统”的存储池,依次单击对应操作列的
 图标,将共享存储池暂停。
图标,将共享存储池暂停。
3.2.3 进入维护模式
1. E0709(不含)之前版本
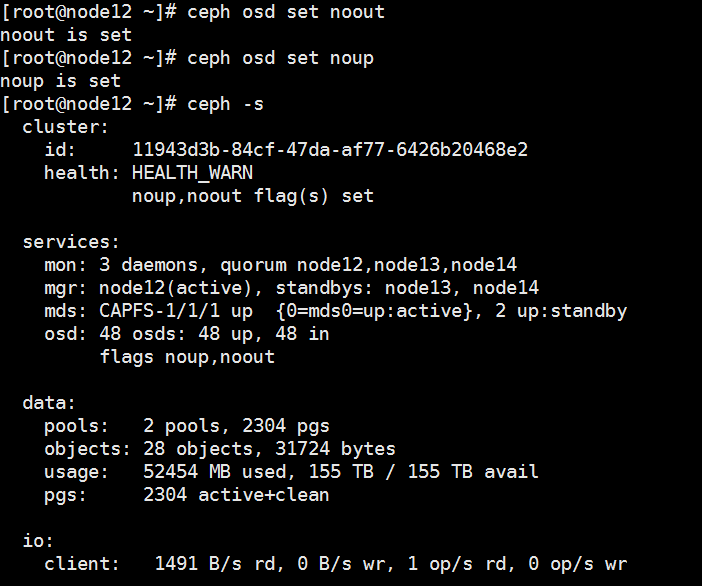
(1) 开启主机维护模式。选择顶部“主机”页签,选择目标主机,进入主机概要信息页面,单击<进入维护模式>按钮。

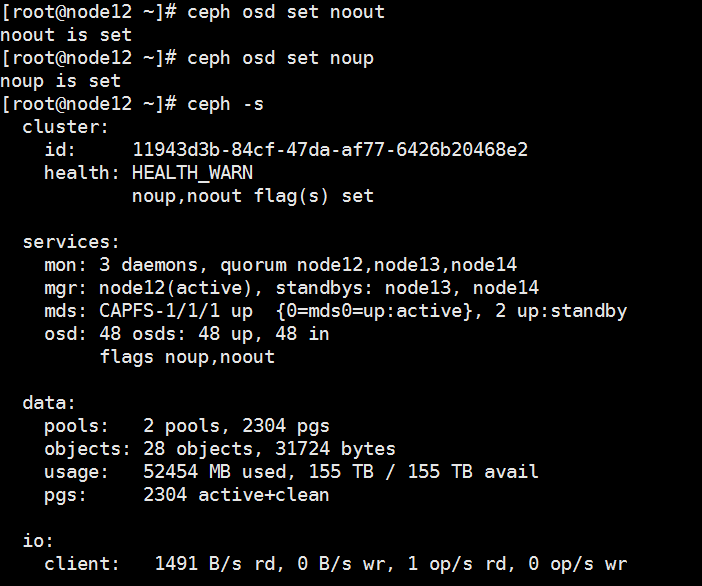
(2) 开启存储维护模式。ssh登录集群中任意正常节点的后台,执行ceph osd set noout和ceph osd set noup命令。
(3) 执行完毕后,执行ceph –s命令,检查状态;状态变为Health_WARN,且提示noout,noup flags set,即表示配置完成,如下图所示。
2. E0709及之后版本
(1) 开启主机维护模式。选择顶部“主机”页签,选择目标主机,进入主机概要信息页面,单击<进入维护模式>按钮,弹出进入维护模式对话框。

(2) 进入维护模式选项,选择“关闭数据平衡”。
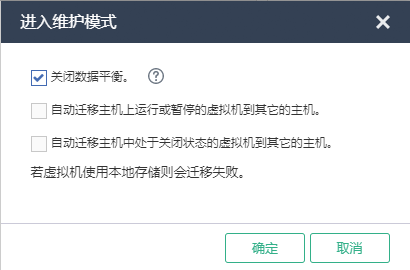
此处的主机维护模式已经包含存储的维护模式,无需单独开启存储维护模式。
(1) 停止故障节点osd。
¡ 对于UIS 6.0版本,在故障节点执行stop ceph-osd-all命令。
¡ 对于UIS 6.5及之后版本,在故障节点执行systemctl stop ceph-osd.target命令。
(2) 等待约1分钟,执行ceph osd tree命令,确认只有故障节点的所有osd状态变为down,其他节点的osd状态仍为up。
(3) 执行ceph –s命令,确认pg状态中不存在pg peering、pg stale、pg activating、pg imcomplete,或pg inactive中的任一状态。
pg peering、pg stale、pg activating属于停止OSD后,pg的中间状态,通常在几秒到十几秒之间就会结束,如果等待1分钟左右还未消失,请联系技术支持进行处理。
拔掉故障节点的管理网、存储网及业务网网线。
注意记住网线、网口的顺序及安装位置,以便部件更换完毕后恢复网络。
3.2.6 备份网卡配置文件
1. UIS 6.0版本
UIS 6.0环境,按如下步骤执行。
(1) 为防止更换网卡和主板后mac地址改变,需要备份网卡配置文件/etc/udev/rules.d/70-persistent-net.rules。
(2) 进入/etc/udev/rules.d/目录下,执行cp 70-persistent-net.rules 70-persistent-net.rules.bak命令备份此配置文件。
root@cvm2:~# cd /etc/udev/rules.d/
root@cvm2:/etc/udev/rules.d# cp 70-persistent-net.rules 70-persistent-net.rules.bak
root@cvm2:/etc/udev/rules.d# ll
total 32
drwxr-xr-x 2 root root 4096 May 9 15:17 ./
drwxr-xr-x 3 root root 4096 Apr 30 17:34 ../
-rw-r--r-- 1 root root 541 Apr 30 17:37 70-custom-net.rules
-rw-r--r-- 1 root root 536 Apr 30 17:33 70-persistent-cd.rules
-rw-r--r-- 1 root root 683 May 9 01:46 70-persistent-net.rules
-rw-r--r-- 1 root root 683 May 9 15:35 70-persistent-net.rules.bak
-rw-r--r-- 1 root root 496 Oct 24 2018 71-persistent-fcoe.rules
-rw-r--r-- 1 root root 1157 Apr 6 2012 README
2. UIS 6.5及之后版本
UIS 6.5及之后版本,请按照如下方式备份网卡配置。
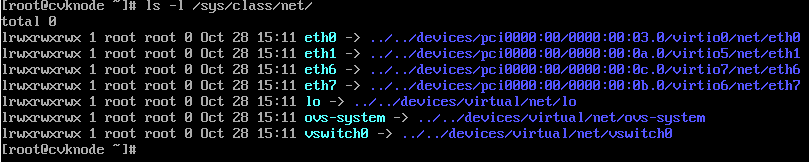
(1) 执行ls-l /sys/class/net/命令,记录硬件更换前的网卡情况。
(2) 如下图所示,以更换前网卡有eth0、eth1、eth6、eth7为例。
3.2.7 手动关机
(1) 执行sync命令,将内存下刷。
(2) 执行hwclock –w命令,将时钟写入BIOS。
(3) 执行shutdown -h now命令,将服务器正常关机。
关机过程中建议关注HDM页面电源状态,避免出现关机命令执行失败或关机命令执行卡住的情况。
(1) 待正常关机后,将故障节点下电,正常更换硬件。
(2) 更换完毕后,将服务器上电开机。检查HDM页面是否有硬件报错,并通过HDM页面登录远程控制台,查看开机自检过程中是否有报错。
(3) 若无报错,可继续进行下一步;若有报错,请排除故障后再继续。
(1) 系统正常启动后,通过HDM远程控制台登录到操作系统命令行界面,使用date命令查看当前节点时间与集群内其他节点是否一致。
(2) 若不一致,则执行date –s命令手动设置时间,保证与其他节点的时间偏差在7s以内。然后执行hwclock –w命令将时钟同步到硬件。
(3) 执行ifconfig –a命令,查看更换硬件后的物理网卡名称是否改变。
¡ 若网卡名称未改变,则连上管理网网线,然后测试故障节点的管理网能否ping通。若能ping通,则继续下一步。若无法ping通,则排查网口状态及链路。
¡ 若网卡名称改变,需要按照以下方法处理。
1. UIS 6.0版本
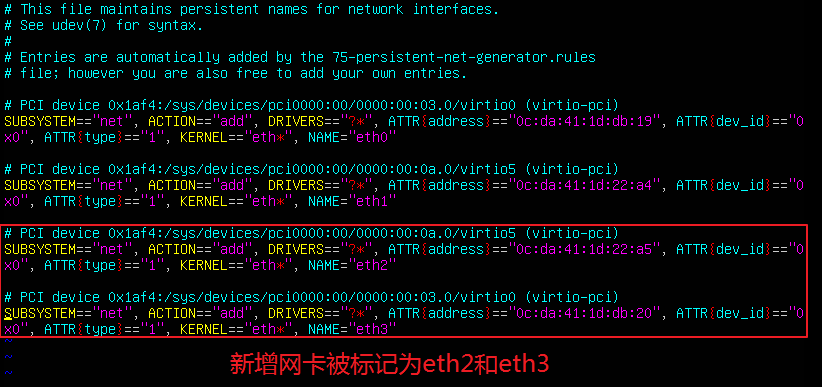
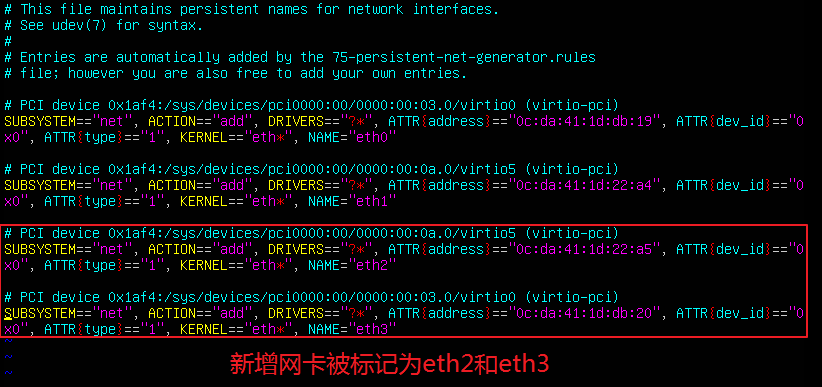
(1) 查看/etc/udev/rules.d/70-persistent-net.rules文件,更换网卡后操作系统会自动更新网卡配置文件(70-persistent-net.rules)。如下图所示,系统将新增网卡标记为eth2和eth3,而eth0和eth1是已经被替换掉的旧网卡。
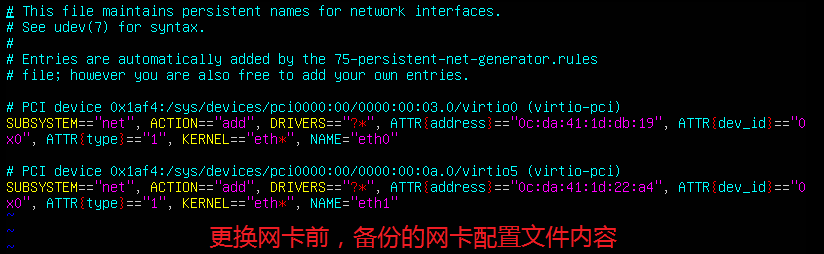
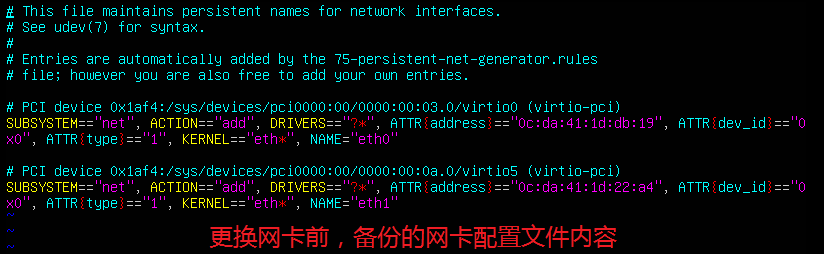
(2) 查看之前备份的/etc/udev/rules.d/70-persistent-net.rules.bak文件。
(3) 找到更换后新网卡与要替换的旧网卡的对应关系。例如,如果要用新网卡eth3替换eth0,用eth2替换eth1,则修改/etc/udev/rules.d/70-persistent-net.rules文件,将eth0对应的ATTR{address}字段替换为eth3的mac地址,将eth1对应的ATTR{address}字段替换为eth2的mac地址。
(4) 确认配置正确后,保存,退出,然后执行reboot重启服务器。重启后,再次检查网卡名称是否恢复到更换之前的名称。
2. UIS 6.5及之后版本
(1) 更换完硬件后,发现原有的网卡不存在,新增了两个网卡,例如新增了eth8、eth9。

(2) 此时需要将原有的网口和网络的绑定关系重新设置。
¡ 针对单网口情况:
例如由之前的eth0换成eth1。
ovs-vsctl del-port
ovs-vsctl add-port
¡ 针对多网口聚合情况。例如更换vswitch0上的聚合口vswitch0_bond,之前的网卡名为eth1+eth2,现在变成eth2+eth3,聚合组模式为静态基本。
ovs-vsctl del-port vswitch0 vswitch0_bond//删除之前ovs上的聚合口
/opt/bin/ovs_bridge.sh mod vswitch0 vswitch0_bond --iface=eth2 --iface=eth3 --lacp=off --bond_mode=balance-slb//将新网卡名加入ovs聚合
(3) 将此前拔掉的网线按原有顺序插好,使用ifup 物理网口名手动启动物理网口,然后执行ip addr命令查看各物理网口状态是否为UP。例如:
ifup ethB03-0//ethB03-0为物理网口名
(4) 检查该节点的存储网和业务网能否与集群中其他节点互相ping通;检查该节点业务网能否ping通客户端。建议持续ping一分钟,若无丢包则为正常。若无法ping通或有丢包,先排除网络故障后再继续下一步。
1. E0709(不含)以前的版本
(1) 关闭存储维护模式。ssh登录集群中任意正常节点的后台,执行ceph osd unset noout和ceph osd unset noup命令。
(2) 执行ceph osd tree命令,查看当前节点的osd状态是否全部变为up状态。
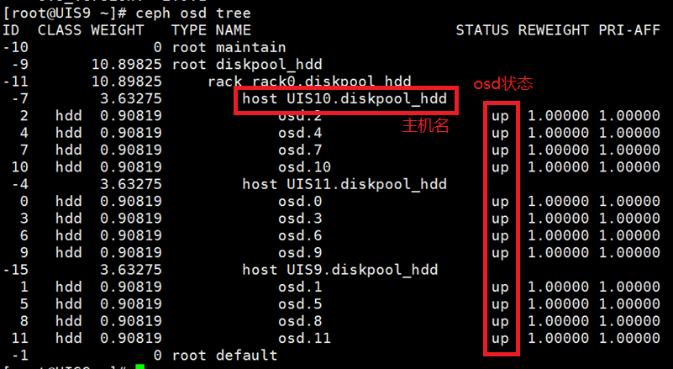
如果发现有osd未恢复为up,在osd未up的节点,执行ceph-disk activate-all命令将osd拉起。然后再次执行ceph osd tree命令,检查osd是否变为up。
(3) 关闭主机维护模式。确认所有osd都恢复为up之后,选择顶部“主机”页签,选择目标主机,进入主机概要信息页面,单击<退出维护模式>按钮。
2. E0709及之后版本
(1) 关闭主机维护模式。选择顶部“主机”页签,选择目标主机,进入主机概要信息页面,单击<退出维护模式>按钮。
(2) 执行ceph osd tree命令,查看当前节点的osd状态是否全部变为up状态。
如果发现有osd未恢复为up,在osd未up的节点,执行ceph-disk activate-all命令将osd拉起。然后再次执行ceph osd tree命令,检查osd是否变为up。
登录管理界面,持续观察集群健康度,直到集群健康度恢复100%且所有告警消除。
3.2.12 启动共享存储池,恢复业务(1) 选择顶部“主机”页签,进入主机管理信息页面。若系统中有多个集群,还需在左侧导航树选择目标主机所在的集群,进入主机集群管理页面。
(2) 选择故障主机,进入主机的概要信息页面。选择“存储”页签,进入主机的存储池列表页面。
(3) 在存储池列表中选择类型为的存储池“共享文件系统”的存储池,依次单击对应操作列的
 图标,启动存储池。
图标,启动存储池。
(4) 将之前迁到其他主机的虚拟机以迁移主机的方式迁移回本主机。
若故障节点已因硬件故障导致关机,则参考本章节操作。
拔掉故障节点的管理网、存储网及业务网网线。
注意记住网线、网口的顺序及安装位置,以便部件更换完毕后恢复网络。
因为故障主机已经关机,无法开启主机维护模式,此时仅开启存储维护模式即可。
(1) 开启存储维护模式。ssh登录集群中任意正常节点的后台,执行ceph osd set noout和ceph osd set noup命令。
(2) 执行完毕后,执行ceph –s命令,检查状态;状态变为Health_WARN,且提示noout,noup flags set,即表示配置完成,如下图所示。
3.3.3 更换硬件
(1) 将故障节点下电,正常更换硬件。
(2) 更换完毕后,将服务器上电开机。检查HDM页面是否有硬件报错,并通过HDM页面登录远程控制台,查看开机自检过程中是否有报错。
(3) 若无报错,可继续进行下一步;若有报错,请排除故障后再继续。
(1) 系统正常启动后,通过HDM远程控制台登录到操作系统命令行界面,使用date命令查看当前节点时间与集群内其他节点是否一致。
(2) 若不一致,则执行date –s命令手动设置时间,保证与其他节点的时间偏差在7s以内。然后执行hwclock –w命令将时钟同步到硬件。
(3) 执行ifconfig –a命令,查看更换硬件后的物理网卡名称是否改变。
¡ 若网卡名称未改变,则连上管理网网线,然后测试故障节点的管理网能否ping通。若能ping通,则继续下一步。若无法ping通,则排查网口状态及链路。
¡ 若网卡名称改变,需要按照以下方法处理。
2. UIS 6.0版本
(1) 查看/etc/udev/rules.d/70-persistent-net.rules文件,更换网卡后操作系统会自动更新网卡配置文件(70-persistent-net.rules)。如下图所示,系统将新增网卡标记为eth2和eth3,而eth0和eth1是已经被替换掉的旧网卡。
(2) 查看之前备份的/etc/udev/rules.d/70-persistent-net.rules.bak文件。
(3) 找到更换后新网卡与要替换的旧网卡的对应关系。例如,如果要用新网卡eth3替换eth0,用eth2替换eth1,则修改/etc/udev/rules.d/70-persistent-net.rules文件,将eth0对应的ATTR{address}字段替换为eth3的mac地址,将eth1对应的ATTR{address}字段替换为eth2的mac地址。

(4) 确认配置正确后,保存,退出,然后执行reboot重启服务器。重启后,再次检查网卡名称是否恢复到更换之前的名称。
3. UIS 6.5及之后版本
(1) 更换完硬件后,发现原有的网卡不存在,新增了两个网卡,例如新增了eth8、eth9。

(2) 此时需要将原有的网口和网络的绑定关系重新设置。
¡ 针对单网口情况:
例如由之前的eth0换成eth1。
ovs-vsctl del-port
ovs-vsctl add-port
¡ 针对多网口聚合情况。例如更换vswitch0上的聚合口vswitch0_bond,之前的网卡名为eth1+eth2,现在变成eth2+eth3,聚合组模式为静态基本。
ovs-vsctl del-port vswitch0 vswitch0_bond//删除之前ovs上的聚合口
/opt/bin/ovs_bridge.sh mod vswitch0 vswitch0_bond --iface=eth2 --iface=eth3 --lacp=off --bond_mode=balance-slb//将新网卡名加入ovs聚合
(3) 将此前拔掉的网线按原有顺序插好,使用ifup 物理网口名手动启动物理网口,然后执行ip addr查看各物理网口状态是否为UP。例如:
ifup ethB03-0//ethB03-0为物理网口名
(4) 检查该节点的存储网和业务网能否与集群中其他节点互相ping通;检查该节点业务网能否ping通客户端。建议持续ping一分钟,若无丢包则为正常。若无法ping通或有丢包,先排除网络故障后再继续下一步。
3.3.5 关闭维护模式
(1) 关闭存储维护模式。ssh登录集群中任意正常节点的后台,执行ceph osd unset noout和ceph osd unset noup命令
(2) 执行ceph osd tree命令,查看当前节点的osd状态是否全部变为up状态。
如果发现有osd未恢复为up,在osd未up的节点,执行ceph-disk activate-all命令将osd拉起。然后再次执行ceph osd tree命令,检查osd是否变为up。
(3) 重新连接故障主机。确认所有osd都恢复为up之后,选择顶部“主机”页签,选择目标主机,进入主机概要信息页面,查看故障主机状态是否正常。若显示为红叉状态,单击<更多操作>按钮,选择[连接主机]菜单项,连接主机。
登录管理界面,持续观察集群健康度,直到集群健康度恢复100%且所有告警消除。
(1) 选择顶部“主机”页签,进入主机管理信息页面。若系统中有多个集群,还需在左侧导航树选择目标主机所在的集群,进入主机集群管理页面。
(2) 选择故障主机,进入主机的概要信息页面。选择“存储”页签,进入主机的存储池列表页面。
(3) 在存储池列表中选择类型为的存储池“共享文件系统”的存储池,依次单击对应操作列的
 图标,启动存储池。
图标,启动存储池。
(4) 将之前迁到其他主机的虚拟机以迁移主机的方式迁移回本主机。
更换完毕后,在UIS管理界面执行一键巡检,若无报错表示更换成功。若有报错,可通过报错提示判断报错原因。若无法确认,请联系400确认。
3.5 授权变更
若更换硬件的主机为管理节点,更换操作可能导致UIS授权失效,需要提交授权变更,更改授权绑定的硬件。


上篇:
SDN系列-基于VxLAN构建Overlay + VxLAN实验
下篇:
如何实现存储设备监控
1 新手必看!华为交换机VLAN配置全流程指南 2 ospf 动态路由,怎么设置, OSPF 实现网段互通 3 VLAN基础+划分详细教程 4 【TL-FW6300】防火墙配置指南——三层路由网关实例设置 5 模拟一个三层办公大楼,实现所有部门、楼层的互通,以及都可以访问公网;出口网关配置... 6 【防火墙】PPTP VPN PC到站点配置方法 7 【防火墙】PPTP 站点到站点VPN配置指南 8 【防火墙】IPSec VPN配置指南 9 ER3、5、6系列路由器搭配AP实现多SSID网段上网的配置实例 10 如何将VMware虚拟机迁移到另一个vCenter服务器 11 pve8.0(kernel6.2)安装vgpu显卡驱动【+vgpu_unlock... 12 黑群晖最新安装方式