MYSQL SQL优化总结
MySQL日常维护中,性能瓶颈是每个运维人员都头疼的问题之一,那么该如何有效解决这个问题呢?慢SQL问题则是重中之重。因此本文重点讲解的是从慢日志的抓取、执行计划的解读、优化的原则到各种类型的案例解析等方面来全方位的讲解慢SQL优化。
一.慢SQL获取
1、开启慢查询
实时获取有性能问题的SQL,数据库参数设定如下:
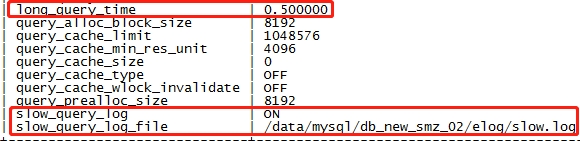
2、慢日志解析
(需提前安装PT工具):
pt-query-digest slow.log --since '2020-06-09 10:43:00' --until'2020-06-09 10:45:00'> tmp/slow.log
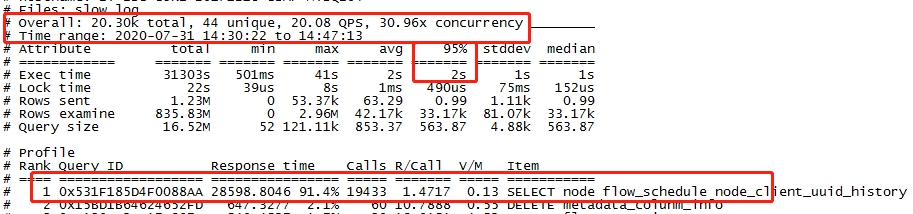
处理原则:优先优化高并发SQL,频率低的大SQL次之。
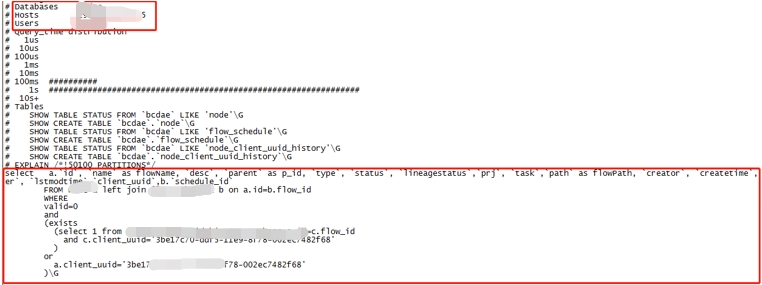
3、慢SQL详细信息
此处可以看到的信息有SQL查询的数据库,用户,具体的SQL内容等。
二.执行计划
1、EXPLAIN语法
EXPLAIN与DESCRIBE、DESC是同义词,具有相同的作用。


Type访问类型是SQL优化的一个重要指标,结果值从好到坏顺序:
system> const > eq_ref > ref > fulltext > ref_or_null >index_merge > unique_subquery > index_subquery > range >index > ALL
2、EXPLAINFORMAT=json解读
有时候使用explain解析出来的执行计划不太详细,而不知道该如何去优化时,可以使用explainformat=json +sql来获取更详细的执行计划信息。
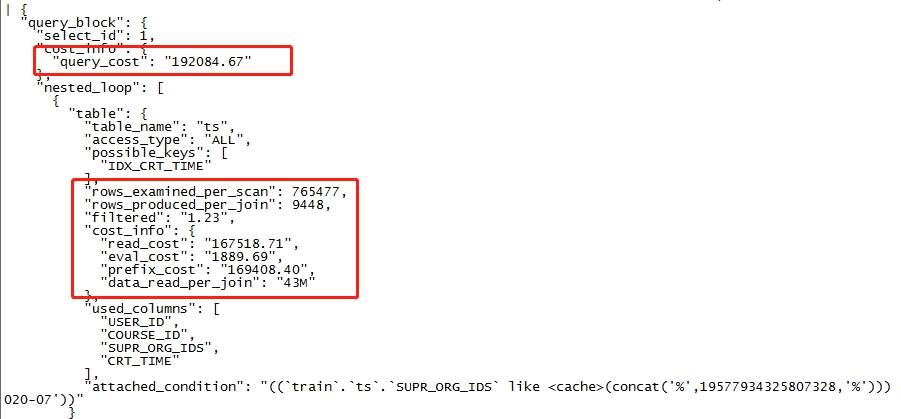
查看执行计划附加信息,show warnings\G;

3、MYSQL8.0新功能
EXPLAIN FORMAT = TREE --显示查询计划和成本估算
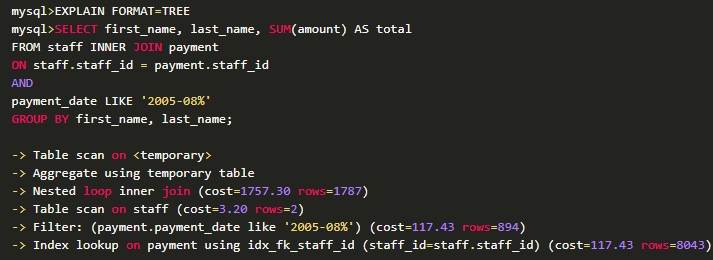
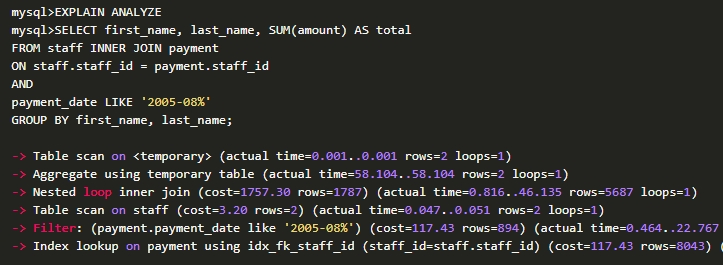
EXPLAINANALYZE—显示实际执行时间及成本
三.优化十大原则
1 、严禁使用SELECT*方式查询语句,必须明确查询字段,INSERT语句必须明确要插入的字段。
2、严禁单条SQL关联表超过3张,关联字段必须有索引且数据类型一致。
3、严禁单条SQL子查询超过2层。
4、严禁在SQL中进行计算或嵌套判断逻辑。
5、严禁查询条件中字段无索引,表的索引数量不要超过6个。
6、严禁在where条件中字段使用函数或者表达式(例如wherecol/3>=100)。
7、严禁负向查询条件(!=、<>、not...)、单表行数大于5万的禁止左模糊、全模糊查询(例如:colA like ‘%服务’)。
8、严禁传入变量类型与查询条件中字段类型不匹配。
9、严禁表无主键或使用复合索引作为主键,严禁使用无序数据作为主键内容。
10、严禁使用外键、视图、触发器、存储过程、自定义函数和分区表。
四.优化案例解析
1、隐式转换
原则:禁止隐式转换,保持变量类型与字段类型一致
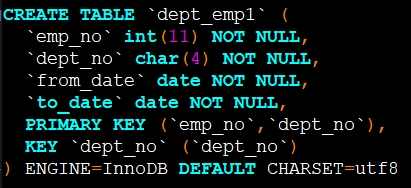
SQL1(正确):selectemp_no,from_date from dept_emp1 where dept_no='404838';

SQL2(错误):selectemp_no,from_date from dept_emp1 where dept_no=404838;

2、WHERE子查询
优化子查询原则:使用连接代替子查询,效率更佳
A.使用连接方式改写子查询,案例如下
例1: SELECTDISTINCT column1 FROM t1 WHERE t1.column1 IN ( SELECT column1 FROMt2);
改写: SELECTDISTINCT t1.column1 FROM t1, t2
WHEREt1.column1 = t2.column1;
或:SELECTDISTINCT t1.column1 FROM t1 JOIN ON t1.column1 = t2.column1;
例2: SELECT *FROM t1 WHERE id NOT IN (SELECT id FROM t2);
改写: SELECT* FROM t1 WHERE NOT EXISTS (SELECT id FROM t2 WHERE t1.id=t2.id);
或LEFT JOIN:
SELECT table1.* FROM table1 LEFT JOIN table2
ONtable1.id=table2.id WHERE table2.id IS NULL;
B.对于只返回一行的无关联子查询用‘=’代替‘in’
例: SELECT *FROM t1 WHERE t1.col_name IN (SELECT a FROM t2 WHERE b = some_const);
改写: SELECT* FROM t1 WHERE t1.col_name= (SELECT a FROM t2 WHERE b = some_const);
总结:对于数据库来说,在绝大部分情况下, 连接会比子查询更快。使用连接的方式,MySQL优化器一般可以生成更佳的执行计划,更高效地处理查询。而子查询往往需要运行重复的查询,子查询生成的临时表上也没有索引, 因此效率会更低。
3、OR语句
原则:有关or的优化,A.建立相关索引,B.将or转化为in或union
A.or子句全部相同,则改为in
示例:select* from t1 where a=1 or a=3;
改为:select* from t1 where a in(1,3);
B.or子句具有公共子序列前缀的,请在or公共部分建立索引
示例:(如下需要在a列上创建索引)
select * from t1 where (a=1 and b=2) or (a=3 and c=4);
C.若无公共,则建议改为unionall,并为每部分建立索引
示例 select* from t1 where a=1 or b=2;
可以使用 Indexmerge
或者转换(效率更高): select * from t1 where a=1
union all
select * from t1 where b=2;
4、GROUP/ORDER BY
4.1、orderby子句,尽量使用Index方式排序,在索引列上遵循索引的最佳左前缀原则。如下:
Key(a,b,c),Orderby 能使用索引情况
--order by a
--order by a, b
--order by a, b,c
--order by a desc ,b desc ,c desc
4.2、如果where使用索引的最左前缀定义为常量,则orderby能使用索引
--wherea=const order by b,c
--wherea=const and b=const order by c
--wherea=const and b>const order by b,c
总结:分组统计可以禁止排序,默认情况下,有分组必排序,如果想避免排序结果的消耗,可以指定orderby null禁止排序。
5、LIMIT偏移量过大
禁止分页查询偏移量过大,如limit100000,10
优化方法一:
A.limit查询转换成某个位置的查询,即把limitm,n转换成limitn;
B.利用自增主键,避免offset使用;
C. 限制用户翻页。
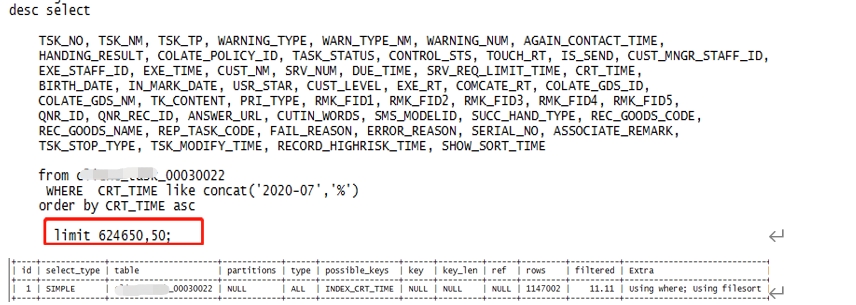
调整LIMIT1000

优化方法二:分页查询尽可能地使用索引覆盖扫描,而不是所有的列,然后再做一次关联操作再返回所需的列。
#优化前
select film_id,description from film order by title limit 50,5
#优化后
select a.film_id, a.description from film a inner join (selectfilm_id from film order by title limit 50,5) b on a.film_id =b.film_id
6、模糊查询
全模糊或左模糊不使用索引
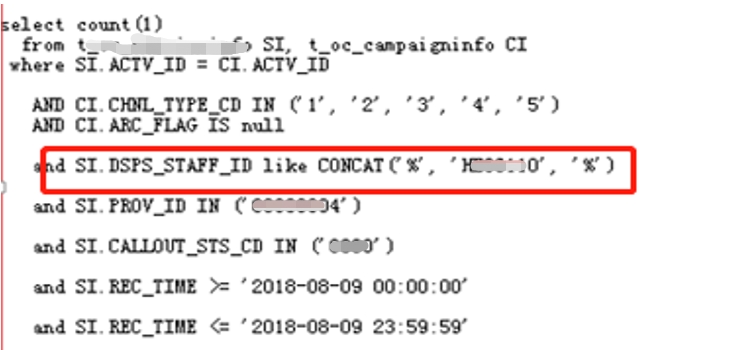

优化建议:全模糊查询改为dsps_staff_id like ’HE12065%’,优化后效率提升百倍。

7、覆盖索引
包含所有满足查询需要的数据的索引成为覆盖索引,也就是平时所说的不需要回表操作,对于一个索引覆盖查询,显示为usingindex。


这里最主要看Extra,它的值为Usingindex,它在这句查询中含义就是直接访问film_id这个索引就足已获取到所需要的数据,不需要再通过索引回表查询了。
使用覆盖索引的前提条件是,查询返回的字段数足够少,select* 类不可以。
8、表/字段 别名


问题点:
A:原sql基表是t5,大量使用临时表、排序,效率低下
B:order bycrttime 使用别名,导致索引失效
建议:orderby crt_time 使用字段名代替别名

9、字符集不同
关联字段的字符集不一致,导致索引不可用。
例如:knowledge_rel的字符集及校验规则,与关联表knowledge不一致,数据关联时,影响SQL执行效率。
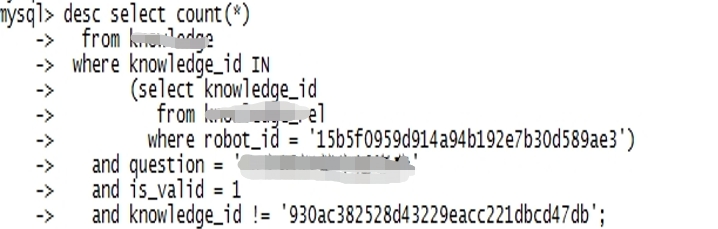
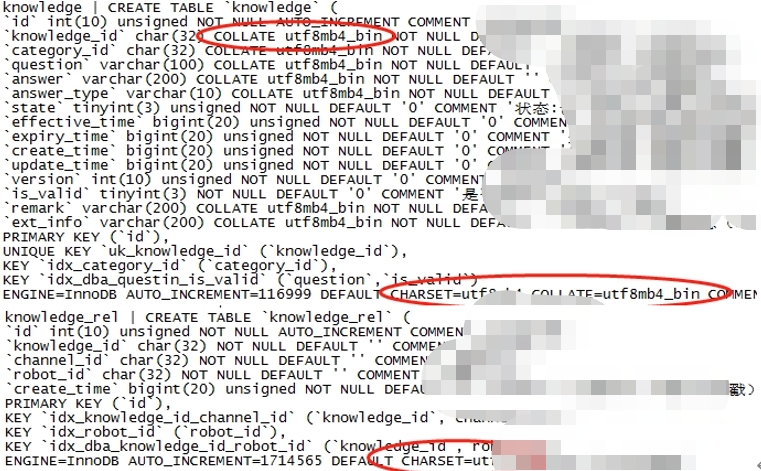
注:utf8mb4_bin比较方法就是直接将所有字符看作二进制串,然后从最高位往最低位比对,所以它是区分大小写的。
10、left join
使用leftjoin一定要注意:
A:条件中尽量有强过滤,将驱动表为小
B:右表的条件列一定要加上索引(主键、唯一索引、前缀索引等),最好能够使type达到range及以上(ref,eq_ref,const,system)
C:无视以上两点,一般不要用leftjoin~~!
原SQL:存在强过滤,但是在所有数据join后的结果集上过滤,差!
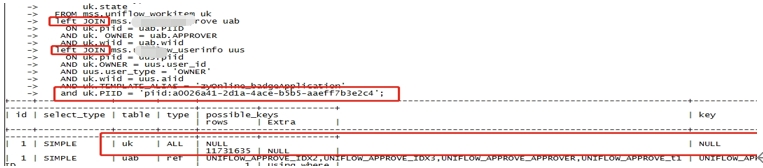
优化后:调整在where后,将驱动表实行强过滤后变小,再与其它表leftjoin,提高效率。



上篇:
详解MySQL---DDL语句、DML语句与DCL语句
下篇:
Oracle双活两地三中心容灾架构
1 微软架构师:用FastAPI+Redis构建高并发服务,性能提升2000%! 2 全网最详细的OSPF原理总结 3 Oracle SQL Developer - Oracle优化教程 4 流量杀手 —— EasyDDOS高性能DDOS工具 5 使用OBD白屏部署OceanBase数据库 6 OceanBase 集群高可用部署方案简介 7 php 增加 拓展 oci8 - 支持oracle数据库 8 Docker安装MS SQL Server并使用Navicat远程连接- 9 Oracle双活两地三中心容灾架构 10 周报就这么写,让领导知道你干了很多活! 11 会议记录工作总结这样写,领导果然夸我了 12 KubeSphere构建mysql集群



