长文预警!这是一篇数据体系介绍文章,并不涉及开发实践。
|0x00 什么是数据
数据是一种对客观事物的逻辑归纳,是事实或观察的结果 。随着科学技术的发展,数据的概念内涵越来越广泛包括数值,文本,声音,图像,视频。常见的数据有三种分类,分别是结构属性分类、连续性特征分类与测量尺度分类。
根据数据存储形式的不同,数据可以分为结构化数据与分结构化数据两种,它们不仅存储形式不同,在数据处理和数据分析的方法上也大相径庭。
结构化数据 :成熟数据库所存储的数据类型,如企业ERP数据、企业财务系统数据、政府市民卡数据等,能够存储在数据库中的数据能够很方便的进行检索、分析和展示使用;
非结构化数据 :相对于结构化数据而言,非结构化数据没有统一的规则,涉及到了音视频、图片、文本等形式,例如爬虫抓取的新闻数据、SDK采集的日志数据等,需要通过一定的方法,将这都些数据量化为结构化数据,才能够进行有效的分析。
根据数据连续的属性不同,数据又可以分为连续型数据与离散型数据。连续型数据与离散型数据的区别,可以 用线、点来区分 理解。
连续型数据 :数据的取值从理论上讲是不间断的,在任意区间内都可以无限取值。例如商品的价格、水果的重量等。
离散型数据 :离散型数据也被成为不连续数据,取值是中立的,例如AA制聚餐,3个人花费100元,那么人均就是33.333……元,无法做到绝对平均。
数据的测量尺度分类,可以理解为一种测量工具,像尺子那样刻画数据的精细度。
定类数据 :特征数据仅能标记事物的类别,无法描述大小、高度、重量等信息,例如工业产品分类中的零食、日化等区分;
定序数据 :能够对事物进行分类,比较事物之间的大小差异,但不能做四则运算,例如考试成绩的排名;
定距数据 :由定距尺度计量形成的,表现为数值,可以进行加减运算,是对事物进行精确描述的数据,但不能做乘除运算,例如高考的总分,是分科得分的加和;
定比数据 :数据的最高级,既有测量单位,也有绝对零点(可以取值为0),可以做乘除运算,如商品的销售额。
|0x01 数据统计的要素
数据的统计过程,主要是为了更好的 体现数据的流转过程 ,而数据统计的要素,就在于如何清晰的描述这个过程。
第一个要素是: 统计主体 ,统计的业务属性。统计主体指数据需要描述或分析的对象,以及该对象所涉及到的所有过程的集合。例如在电商系统中,需要描述交易的整个过程,包括商品、下单、支付、退换货等过程,那么订单就可以作为这个过程中的统计主体,串联起整个过程。需要注意的是,统计主体可以是人,也可以是物、甚至可以是任何抽象出来的概念。
第二个要素是: 统计维度 ,统计的空间属性。维度是维度建模最重要的建设项目,是描述平台表及业务过程的重要表述方式。在大数据领域,统计维度通常来自于业务概念的抽象,比如商品类目、属性等信息。对于一张汇总层的表来说,除了统计指标,其余所有的信息,都可以看作是统计维度。
第三个要素是: 统计周期 ,统计的时间属性。包括时间粒度、生命周期等过程,可以是实时发生的事实,也可以是按时间进行累计的事实。通常统计周期有小时、日、周、季度、年的区分。
第四个要素是: 统计指标 ,统计的行为度量。一般由指标名称和指标数值两部分组成,在维度建模中提倡的方式是:指标=原子指标+派生指标+业务限定+统计周期+维度。
|0x02 大数据的应用方向
架构方向
大数据领域的架构方向偏重于Hadoop、Spark、Flink等主流框架的实现、调优、部署等工作,同时配合Hive、HBase、ClickHouse等查询工具, 实现软硬件资源利用率的最大化 ,并提供稳定可靠的数据服务。
这个领域的关键词如下:
架构理论 :分布式、高并发、高可用、并行计算等;
架构框架 :Hadoop、Spark、Flink、Kafka等;
架构应用 :Hive、HBase、Cassandra、Presto、ClickHouse等。
数仓方向
数仓方向遵循的是维度建模理论, 注重数据统计流程的构建、洞察数据与业务的价值联系 等。这个方向会将数据架构、数据库开发、可视化呈现、数据产品与运营串联起来。
这个领域的关键词如下:
数据建模 :维度建模、范式建模等;
数据ETL :Flume、Kafka、RDBMS、NoSQL、Hive等;
数据可视化 :HightCharts、ECharts、Tableau等。
分析方向
数据分析更多的偏向 数据指标体系的建立 ,通过统计学原理、深度挖掘和机器学习等方法,探索数据与数据之间的联系,洞察对未来事物的预测和预判。
这个领域的关键词如下:
数据统计 :指标体系、推断分析、回归分析等;
数据洞察 :数据挖掘、机器学习、协同过滤等;
数据加工 :Python、SQL、ETL等。
|0x03 大数据的计算过程
阶段一: 数据采集
数据采集特指从外部系统采集数据,并导入到数据存储系统的过程,主要分为 Web端日志采集、客户端日志采集、数据库同步 三个方向。
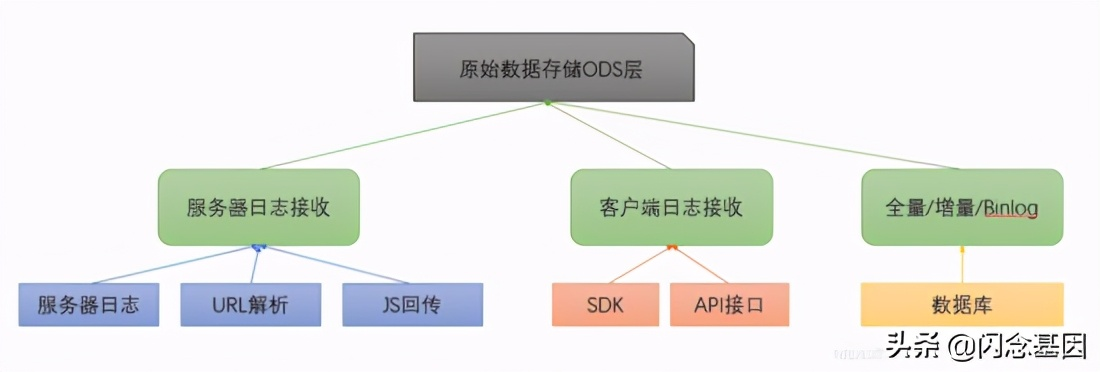
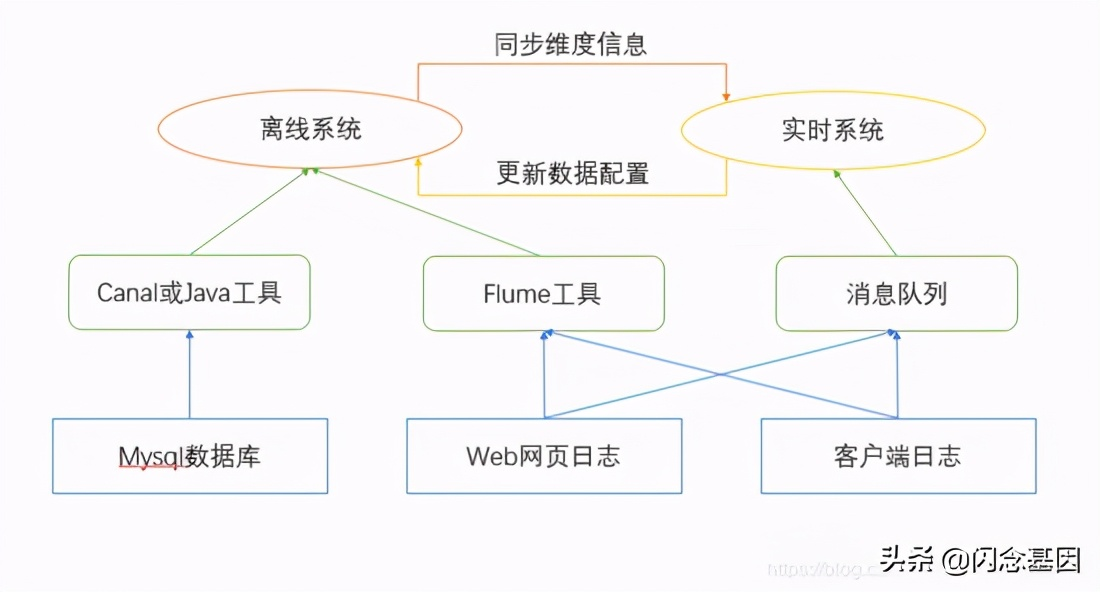
阶段二: 数据存储
数据存储的选择很多,比如传统的 关系型数据库 :Oracle、MySQL;新兴的 NoSQL :HBase、Cassandra、Redis; 全文检索框架 :ES、Solr等。但更广泛的应用,还是Hadoop生态下的 HDFS ,近年来也逐渐发展出了面向对象存储的OSS、面向表格的存储TableStore等。
阶段三: 数据计算
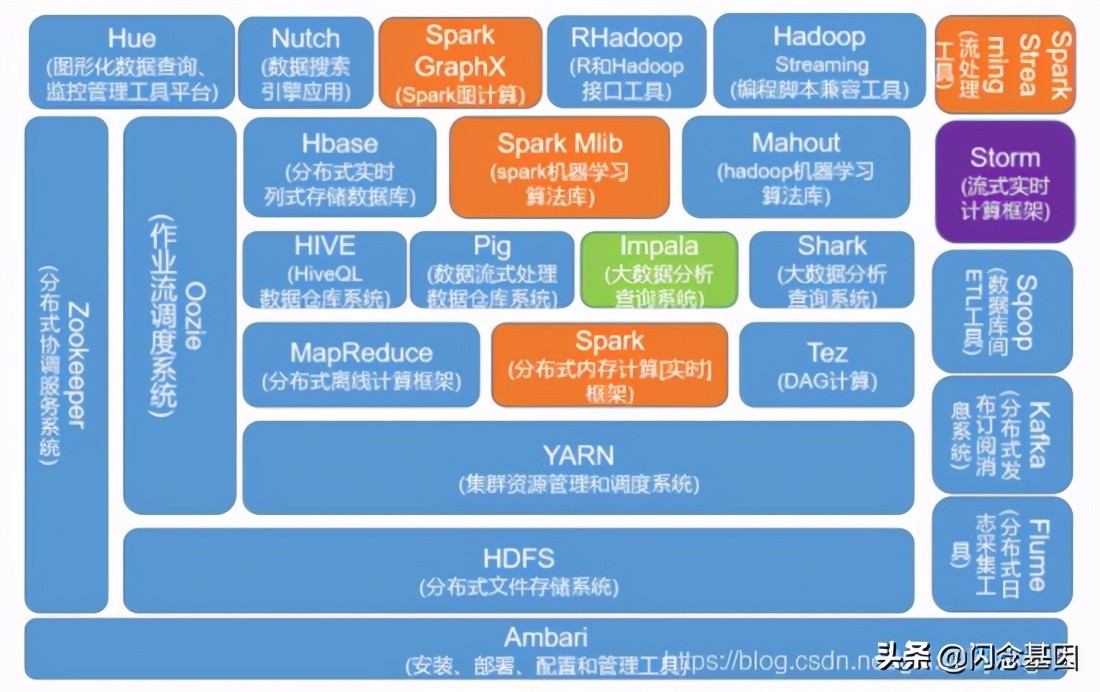
数据计算主要分为 批处理框架、流处理框架、交互式分析框架 三种。批处理框架以Hadoop为代表,MapReduce、Spark-RDD为主要开发工具;流处理框架以Flink、Storm为代表;交互式分析框架的选择比较多,主要有Google开发的Dremel和PowerDrill,Facebook开发的Presto, Cloudera开发的Impala,以及Apache项目Hive、Drill、Tajo、Kylin、MRQL等。
阶段四:数据建模
数据建模是以人为主导的开发环节,与数据采集、存储、计算等所使用的工具方法论不尽相同。数据仓库的概念是建立在大数据的基础知识上,而大数据拥有良好的性能、廉价的成本、极高的效率及可控的质量四大优势,但同时大数据又存在业务关联广泛、计算流程复杂、管理难度较大等问题,因而十分需要通过建模方法论来更好的组织和存储相关数据。
数据建模目前常用的主要有 E-R模型、维度建模、DataVault建模 三种。为了将模型阐述清楚,我们通常会使用UML作为统一建模语言,是用来针对建模方法论而使用的工具,并非建模方法论本身。
阶段五:数据分析
数据分析是大数据计算的最后一步,也是最重要的环节。“分析”两个字的含义可以包含两个方面的内容:一个是 在数据之间尝试寻求因果关系或影响的逻辑 ;另一个是 对数据的呈现做适当的解读 。数据分析的目的性极强,区别于数据挖掘的找关联、分类、聚类,数据分析更倾向于解决现实中的问题。例如:我想解决什么问题、通过这次的分析能让我产生什么决策等等。数据分析主要是把采集到的数据通过建立数据模型,在分布式计算框架下进行计算加工、汇总分析等。
|0x04 大数据的分析方法
大数据的分析方法论,通常以 营销、管理 等理论为指导,结合实际业务情况,搭建分析框架,这样才能尽量确保数据分析维度的完整性,结果的有效性及正确性。
营销方面的理论模型有:4P、用户使用行为、STP理论、SWOT等。
管理方面的理论模型有:PEST、5W2H、时间管理、生命周期、逻辑树、金字塔、SMART原则等。
PEST:PEST即政治(Political)、经济(Economic)、社会(Social)和技术(Technological)四个领域的首字母缩写,2010年后更被扩展为 STEEPLE 与 STEEPLED,增加了教育(Education)与人口统计(Demographics),主要用于主要用于行业分析,通过分析与外部总体环境的因素互相结合就可归纳出SWOT分析中的机会与威胁,可以作为企业与环境分析的基础工具。
5W2H:应用相对广泛,可用于用户行为分析、业务问题专题分析、营销活动等5W2H,即何因(Why)、何事(What)、何人(Who)、何时(When)、何地(Where)、如何做(How)、何价(How much)该方法广泛应用于企业营销、管理活动,对于决策和执行性的活动措施非常有帮助,也有助于弥补考虑问题的疏漏。
逻辑树:又称问题树、演绎树或分解树等。它是将问题的所有子问题分层罗列,从最高层开始,并逐步向下扩展。逻辑树的作用主要是帮我们理清自己的思路,避免进行重复和无关的思考。
|0x05 数据分析的价值
简单地来说,分析可被划分为4种关键方法。
描述型分析:发生了什么?
数据分析领域最常见的方法,就是描述业务正在发生什么,例如在用于增长领域,分析师就可以根据每个月营收和支出的账单,与用户标签数据结合起来,分析每个用户的获客成本,并利用可视化的工具来制作响应的报表。
诊断型分析:为什么会发生?
描述性数据通常只能反映业务现状,但如果需要了解为什么,就需要不断的将数据进行下钻,通过诊断分析工具、BI报表工具等支持,数据可以直接钻取到最细粒度,能够深入分析问题发生的原因。
预测型分析:可能发生什么?
预测型分析主要用于进行预测事件未来发生的可能性,给预测事件一个可量化的值,或者是预估事情发生的时间点,这些都可以通过预测模型来完成。预测模型通常会使用各种可变数据来实现预测。数据的多样化与预测结果密切相关。在充满不确定性的环境下,预测能够帮助做出更好的决定,这也是很多领域正在使用的重要方法。
指令型分析:需要做什么?
指令模型基于对“发生了什么”、“为什么会发生”和“可能发生什么”的分析,来帮助用户决定应该采取什么措施。通常情况下,指令型分析不是单独使用的方法,而是前面的所有方法都完成之后,最后需要完成的分析方法。
|0x06 数据的指标体系
指标,顾名思义,就是指定的标准。词典里的解释是“ 衡量目标的单位或方法 ”。指标就是为了描述一些对象的状态而制定出来的标准,在日常生产生活中有着非常广泛的应用。指标体系,就是将统计指标系统性的组织起来,由指标、体系两部分组成,主要包括:用户数、次数、人均次数、时长、点击率、转换率、渗透率、留存率、成功率等。
如果没有指标对业务进行系统衡量,我们就无法把控业务发展,无法对业务质量进行衡量,尤其现在很多企业多项业务并行,单一数据指标衡量很可能片面化。因此,搭建系统的指标体系,才能全面衡量业务发展情况,促进业务有序增长。
随着数据量的增大,数据指标也会越来越多,即使是同样的命名,但定义口径却不一致。这对于各部门理解难度大,同时也造成了重复计算存储的资源浪费。阿里 OneData指标规范 ,以维度建模作为理论基础,构建总线矩阵,定义业务域、数据域、业务过程、度量/原子指标、维度、维度属性、修饰词、修饰类型、时间周期、派生指标等,帮助我们形成统一数据标准。
|0x07 数据的建模思路
建模,顾名思义,就是建立模型的意思,为了针对理解产品、业务、应用逻辑之间的相互关系而做的抽象,用于避免理解歧义。 建模通常用文字配合模型的方式,将复杂的事物描述清楚,便于自己及他人的理解。如果把数据比作是图书馆里的书,那么建模就相当于合理规划图书馆的布局,能够让读者迅速而合理的找出目标书籍。
E-R模型
ER模型,全称为实体联系模型、实体关系模型或实体联系模式图,由美籍华裔计算机科学家陈品山发明,是概念数据模型的高层描述所使用的数据模型或模式图。E-R模型的构成成分是实体集、属性和联系集,其表示方法有如下三种:
实体集用矩形框表示,矩形框内写上实体名;
实体的属性用椭圆框表示,框内写上属性名,并用无向边与其实体集相连;
实体间的联系用菱形框表示,联系以适当的含义命名,名字写在菱形框中,用无向连线将参加联系的实体矩形框分别与菱形框相连,并在连线上标明联系的类型,即1—1、1—N或M—N。
维度建模
维度建模是数据仓库建设中的一种数据建模方法,将数据结构化的逻辑设计方法,它将客观世界划分为度量和上下文,Kimball最先提出这一概念。维度建模其最简单的描述就是,按照事实表,维度表的方式来构建数据仓库。维度是度量的环境,用来反映业务的一类属性;事实表是维度模型的基本表,每个数据仓库都包含一个或者多个事实数据表。维度建模最被人广泛知晓的一种方式就是星型模式。阿里巴巴电商系对于维度建模有一些非常好的扩展补充,例如维度表可以分为快照维表、缓慢变化维表等,事实表可以分为事务事实表、周期快照事实表和累计快照事实表,这些概念解释起来非常的复杂,应用场景也比较极限,因而会用独立的文章来分别阐述。
DataVault模型
DataVault是E-R模型的衍生版本,针对复杂笨重的E-R模型,强调有基础数据层的扩展性和灵活性,同时强调历史性、可追溯性和原子性,不要求对数据进行过度的一致性处理。DataVault模型是一种中心辐射式模型,其设计重点围绕着业务键的集成模式,业务键是存储在多个系统中的、针对各种信息的键,用于定位和唯一标识记录或数据。DataVault有三种基本结构:中心表(Hub):唯一业务键的列表,唯一标识企业实际业务,企业的业务主体集合;链接表(Link):表示中心表之间的关系,通过链接表串联整个企业的业务关联关系;卫星表(Satellite):历史的描述性数据,数仓中数据的真正载体。
|0x08 数据化运营
用户转化漏斗
用户转化漏斗思路的核心,是 如何引导用户主键的接受和使用产品 。例如在广告领域,它是展示—>点击—>转化;在游戏领域,它是下载—>激活—>留存—>付费;等等。
无论上面哪种业务,都可以分解为一系列的阶段,经过每个阶段,用户都只有一部分留存下来。对漏斗的每一个环节准确地记录数据,以便分析和优化各个环节的通过比率,是数据运营的基础设施。
多维度数据报表
数据运营中的常见痛点,是明知道转化漏斗上某个环节的通过率较低,却找不到提高的途径。常用的解决思路,就是 把数据进行不断多维度的下钻,在很细的粒度上观察数据,并发现产品或系统上可能存在的问题 。比如说,你发现广告的点击率低,进而查到是Chrome浏览器上的点击率拉低了整体统计,那么就要在Chrome浏览器上深究原因,结果很可能是你的Flash广告素材直接被Chrome给屏蔽了。如果多个维度能够灵活组合观察数据,就成了一个数据魔方(Data Cube)。
A/B测试
A/B测试是常见的验证手段,当制定了制定多个产品可能的改进方向,不清楚应该如何选择时,我们可以将不同的版本放到线上, 让实际数据来决定谁上谁下 。这种A/B测试的方法,往往是大家理想中躺着就可以优化出好产品的魔法,也是“数定胜人”理论的基础之一。
|0xFF 数据的中台建设
从上至下分为五个层次:
方法论、机制、标准:指标体系、建模体系、分析体系;
原子能力:数据采集、数据存储、数据计算、数据平台;
通用基础:数据建模、元数据、任务调度、血缘追踪;
业务支撑:数据开发、数据服务、数据运营;
前台:业务A、B、C。


上篇:
腾讯大牛教你ClickHouse实时同步MySQL数据
下篇:
Hologres+Flink实时数仓详解
1 详情页生成器在线制作,一键自动生成商品详情,电商人告别熬夜做 2 用codex做电商图,顺手做了一条电商工作流 3 Remotion 最强竞品!用 HTML 写视频,AI 自动成片 4 电商必懂的数据公式 5 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 6 2026年人工智能领域,这些岗位急需大量人才 7 一个人全流程搞定AI漫剧:文生图+配音+剪辑的全链路解析 8 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 9 2026 年 AI 创业全景指南:给渴望借 AI 逐梦的人! 10 用AI自动生成爆款文案的完整流程 11 地理空间AI应用:YOLO vs. SAM 12 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼”