简介: 本次内容将会介绍使用Flink和Hologres,实现可扩展的、高效的、云原生实时数仓。
Hologres是一款兼容PostgreSQL 11协议的一站式实时数仓,与大数据生态无缝打通,支持PB级数据高并发、低延时的分析处理,可以轻松而经济地使用现有BI工具对数据进行多维分析透视和业务探索。
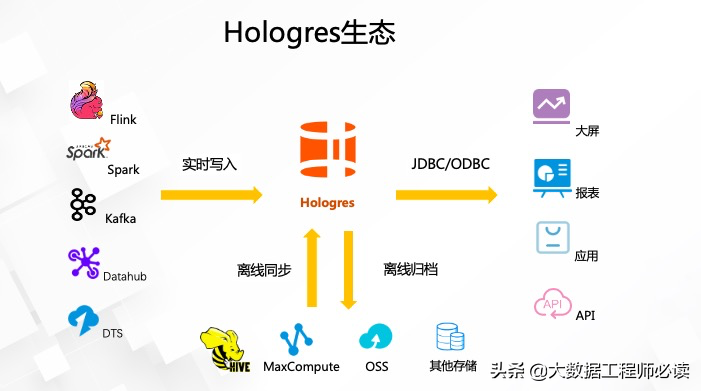
一、Hologres生态
从前面几篇的内容,相信大家已经了解到Hologres是一款兼容PostgreSQL协议的实时交互式分析产品。在生态的兼容性上,Hologres有着非常庞大的生态家族,如下图所示,
对于开源大数据领域,Hologres支持当下最流行的大数据开源组件,其中包括
对于埋点类数据,支持Blink/Flink/Spark/数据集成等大数据工具进行高性能的实时导入和批量导入
对于数据库类的数据,通过和Dataworks数据集成(DataX和StreamX)共建实现方便高效的数据库整库实时镜像到Hologres中,并满足金融企业对可管理性、监控、网络等的需求
无论是实时数据,还是离线数据接入Hologres之后,接下来就能使用Hologres对数据进行分析。最常见的就是使用JDBC或者ODBC对数据进行查询、分析、监控,然后承接上游的业务,比如说大屏、报表、应用等各种场景。
同时再为大家介绍一下DataWorks,它是阿里云的一个数据开发平台,提供了数据集成、数据地图、数据服务等功能。数据集成主要功能可以将数据库的数据导入Hologres,其中同步的方式包括离线同步和实时同步,离线同步支持几十种异构数据源同步至Hologres,而实时同步当前主要支持以下几种:
Mysql Binlog:通过订阅Biblog的方式将mysql数据实时写入Hologres
Oracle CDC:全称是Change Data Capture,也是一个类似Mysql Binlog的用来获取Oracle表change log的方式
Datahub:是阿里巴巴自研的一个分布式高性能消息队列,值得一提的是,Datahub自身也提供了直接将数据实时导入至Hologres的功能,无需经过Dataworks
PolarDB:是阿里巴巴自主研发的关系型分布式云原生数据库

二、Hologres实时导入接口介绍
接下来为大家介绍一下Hologres提供的一个实时导入的接口,以及接口的技术原理。
1)实时导入接口
Hologres实时导入接口的具备以下特性:
行存&列存都支持
支持根据主键去重 (Exactly once)
支持整行数据局部更新
导入即可见,毫秒级延迟
单Core 2W+ RPS (TPCH PartSupp表)
性能随资源线性扩展
支持分区表写入
2)实时导入原理
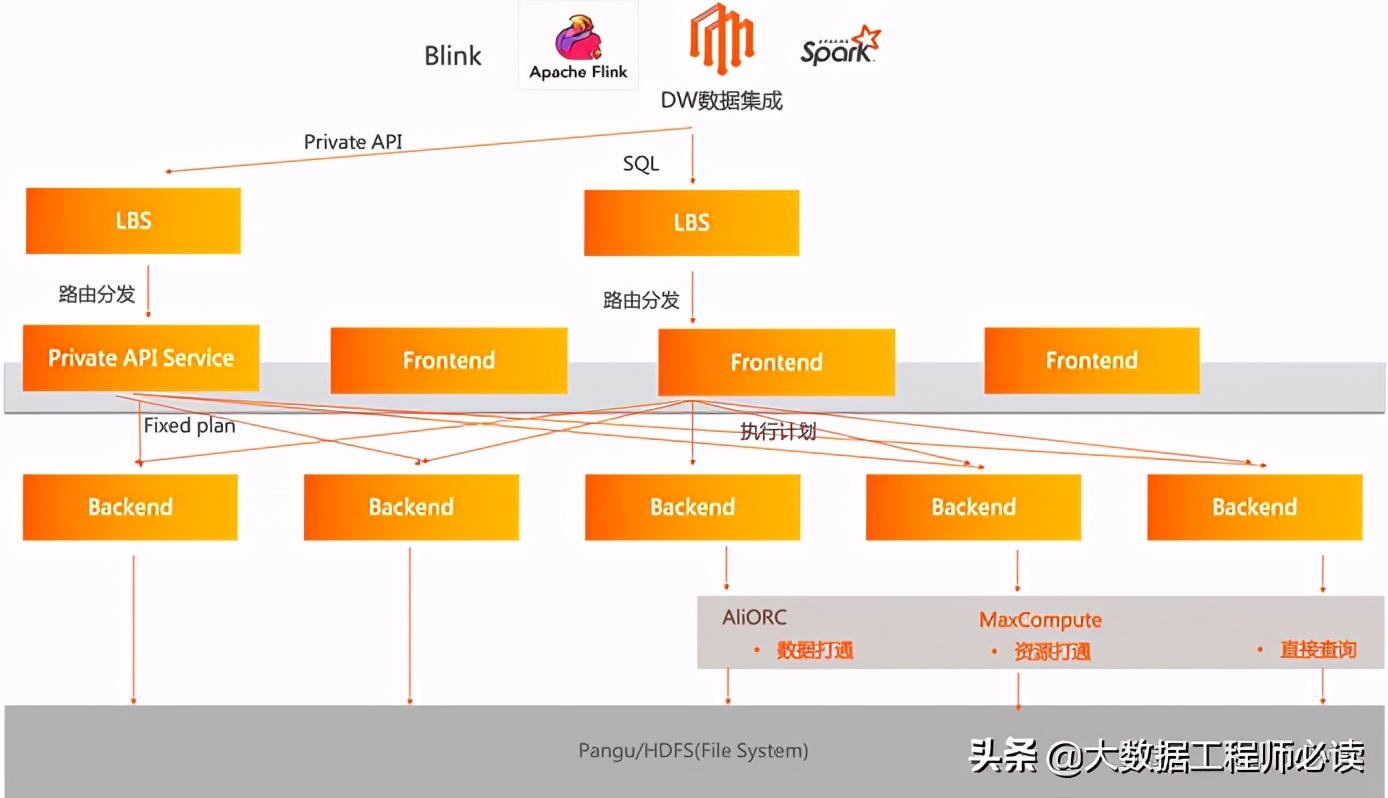
实时导入的原理如下图所示,首先我们看一下该图的最上面的几个节点,代表了数据的上游,也就是业务层。如何将数据导入Hologres,主要有两种场景:
使用SQL进行数据的导入(最常见)
例如使用JDBC执行insert语句,该insert语句会经过一个负载均衡服务器路由分发至我们的Frontend节点,对该insert语句进行SQL的解析优化,然后生成一个优化后的执行计划,并将该执行计划分发至后端的worker节点。worker节点收到该执行计划之后,就会将该数据完成写入。
Connector写入
另外一条链路为左边的Private API链路,也就是当前Apache Flink或者Apache Spark Connector所使用的Hologres的实时导入接口。该Private API提供的数据接口和普通sql请求不一样,而是我们称之为Fixed Plan的请求接口,这些请求被分发至负载均衡服务器之后,负载均衡服务器会将数据路由分发至一个叫做Private API Service的节点。该节点将数据写入请求分发至worker节点,也就是后端的节点。当worker节点收到,无论是Fixed Plan,还是执行计划之后,会对数据进行持久化,最终数据完成写入。
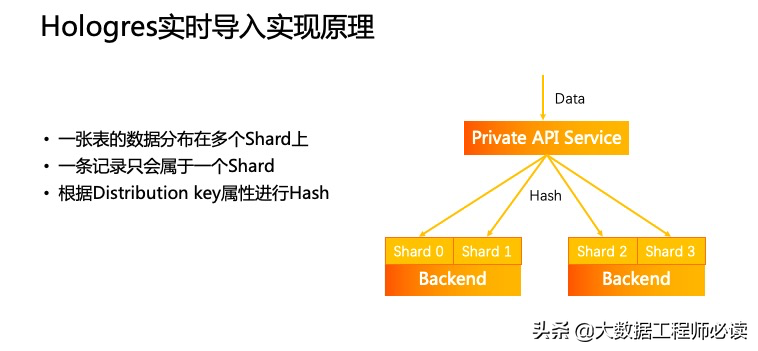
接着来更进一步理解Private API Service的一个数据分发功能。如下图所示,一张表的数据分布在多个Shard上,一条记录只会属于一个Shard,根据Distribution key属性进行Hash。
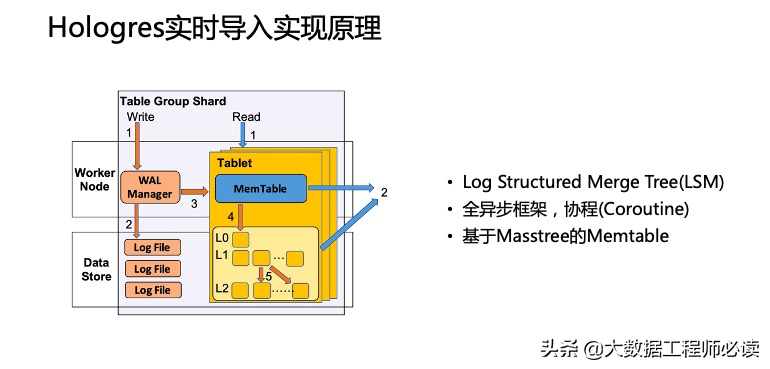
当实时写入的数据请求到达后端的worker节点之后,worker节点是怎么处理的。如下图所示,这一块有如下特点:
Log Structured Merge Tree(LSM)
全异步框架,协程(Coroutine)
基于Masstree的Memtable
同时上面也提到通过SQL来进行数据的写入是最常见的场景,Hologres也在后端优化了整个SQL的写入链路。例如对于Insert into values,Insert into on conflict do update,Select from where pk = xxx等场景简单的SQL,Hologres会进行优化,减少SQL的解析和优化过程,提升整个数据写入和查询的性能。
三、Hologres实时读写场景
前面介绍了Hologres通过connector写的原理,下面将会介绍Flink+Hologres最常见的写入场景。
1)实时写入场景
最常见的第一种就是实时写入场景。实时写入分为几种。
第一种,Hologres的结果表没有设置主键,这样Flink实时接入就是一种Append Only的模式进行写入。当上游数据发生重复,或者Flink任务作业失败,上游数据会需要进行回溯,这时候下游数据录入到Hologres中就会产生重复的数据。这种情形对于日志型数据是比较合理的,因为用户并不需要关心数据是否需要进行去重
第二种,Hologres的结果表设置了主键。Flink或者其它实时写入就会按照行的主键进行更新。主键更新的意思就是说对于相同主键的两行数据,后到的数据会完全覆盖掉之前已经到达的数据。
第三种,是按照主键去重。就是说后到的数据会被忽略掉,只保留最早到的一条记录。这种场景用户并不关心主键的更新情况,只需要保证主键的去重。
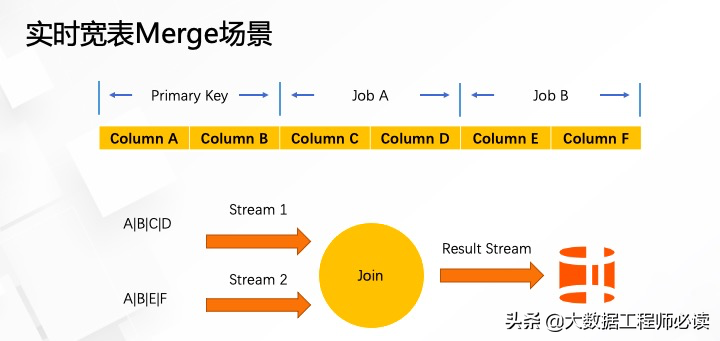
2)宽表Merge场景
例如一个用户的结果表有非常多的字段,会有上百列,而该表的许多字段可能同时分布在不同的数据上游,例如,Column C和D分布在一个kafka的topic A上面,Column E和F分布在kafka的topic B上面,用户希望消费两个kafka topic,并将数据merge成Hologres的一张结构表。最常见的解决办法是,进行流场景的一个双流Join。这种实现对于开发人员来说相对比较复杂,需要实现一个双流Join,而且理论上来说会对计算资源要求非常大,也加剧了运维人员的负担。
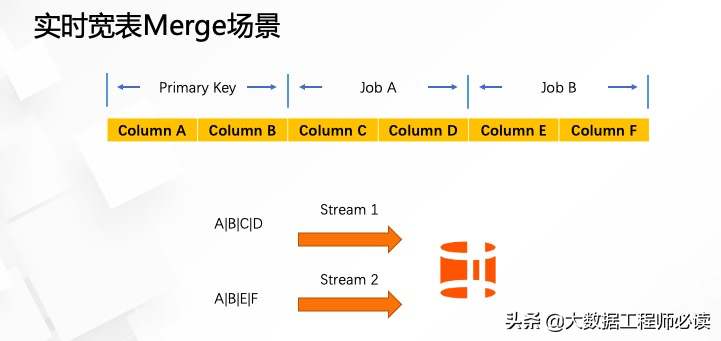
而Hologres针对这种场景是如何实现的呢?
Hologres支持局部更新的功能。如下图所示,按照这种实现方式,只需要两个流各自写入Hologres结果表。第一个流消费ABCD四个字段,将数据写入到最终的结果表中。第二个流消费ABEF四个字段,最终将数据写入到结果表,并不需要进行双流的Join,最终Hologres会自己进行一个数据的组装。第一个流写入ABCD的时候并不会去更新已经存在的EF字段,同样,第二个流写入ABEF字段的时候,C和D字段已经存在,不会被更新,最终达到完整的一个数据Merge的功能。使用这种功能,可以大大提升流作业的开发效率,以及减少流作业所需要的资源消耗,也能够更容易的维护各个流作业。
3)实时维表Join场景
除了写场景,Hologres也支持读场景,最常见的是使用Hologres的行存表来进行点查。如下图所示,是一个实时维表的Join场景。主要逻辑是生成一个数据源,会不停的生成一个数据流,和Hologres的维表进行Join,打宽数据流,最终将数据写入到一个结果表中。在实际业务中,这种使用场景通常会用来替换HBase,以达到更好的性能和更低的成本。

4)Hologres Binlog场景
如下图所示,以消息队列方式读取Hologres数据的Change log。 其中:
Binlog系统字段,表示Binlog序号,Shard内部单调递增不保证连续,不同Shard之间不保证唯一和有序
Binlog系统字段,表示当前 Record 所表示的修改类型
UPDATE操作会产生两条Binlog记录,一条更新前,一条更新后的。订阅Binlog功能会保证这两条记录是连续的且更新前的Binlog记录在前,更新后的Binlog记录在后



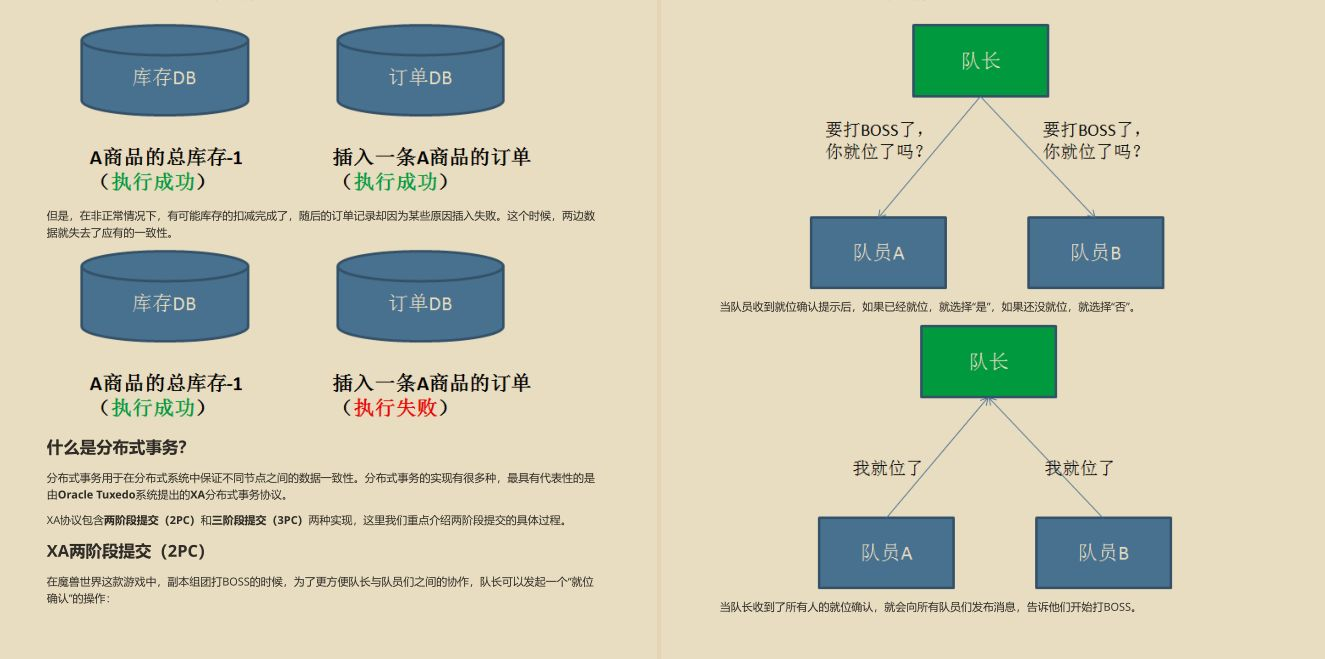
上篇:
大数据领域全景解析
下篇:
Hologres+MaxCompute数据仓库服务化详解
1 电商必懂的数据公式 2 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 3 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 4 用AI自动生成爆款文案的完整流程 5 地理空间AI应用:YOLO vs. SAM 6 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 7 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 8 5分钟一键生成软著申请材料,coze工作流全教程,含提示词 9 Vaex :十亿行每秒的 Python 大数据神器,探索与可视化的新标杆 10 大数据安全架构设计方案 11 一天做出短剧App:我的MCP极速流 12 Deepsek和AI组合打法让你的养生视频条条爆款