笔者所在的技术团队负责了数十个项目的开发和维护工作,每个项目都至少有dev、qa、hidden、product四个环境,数百台机器,在各个系统之间疲于奔命,解决各种琐碎的问题,如何从这些琐碎的事情中解放出来?devops成了我们不二的选择。
文章是基于目前的环境和团队规模做的devops实践总结,方案简单易懂,容易落地且效果显著。
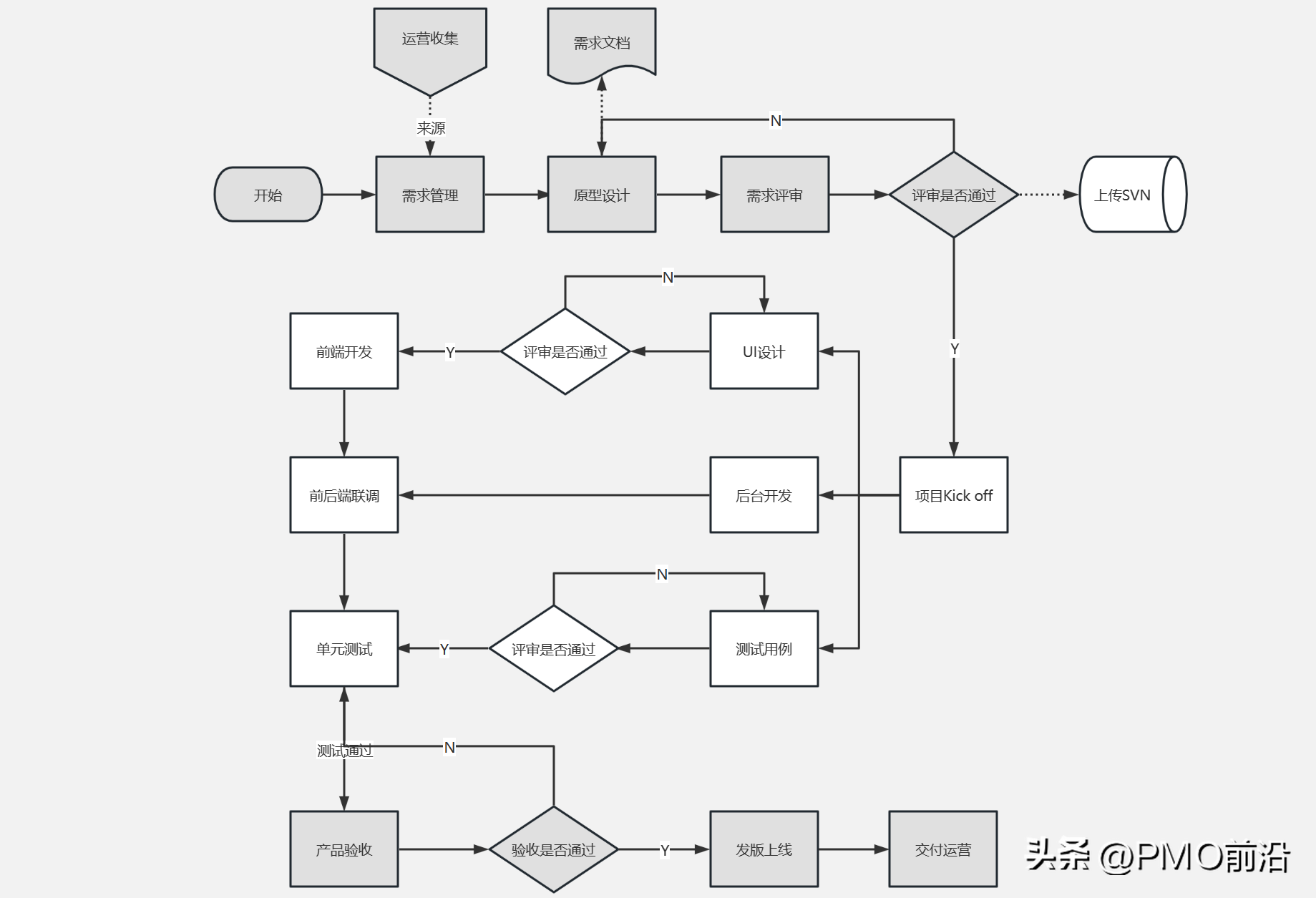
实现方法
先来看下流程图:
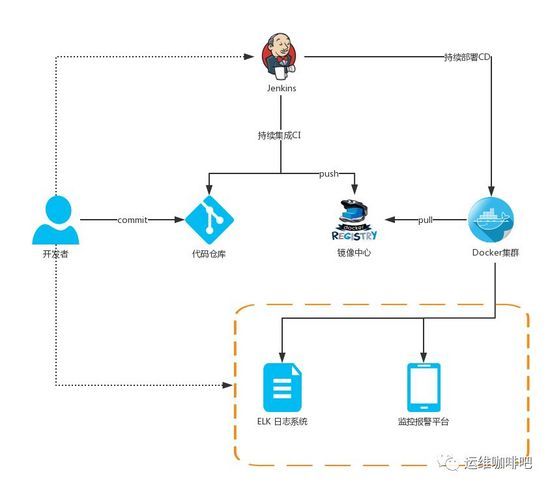
工程师本地开发,开发完成后提交代码到代码仓库,[自动]触发jenkins进行持续集成与部署,部署完成会收到结果邮件。项目运行过程中可通过日志系统查看程序日志,有异常会触发监控系统发送报警。从编码到上线后结果反馈都可以工程师自主完成,形成完整闭环,运维则负责提供完整流程的工具链及协助异常情况的处理,工作量减少了,效率却高了。
自动触发jenkins部署通过svn和git的hooks来实现,是否自动触发根据项目内部沟通决定,我们目前没有自动触发,原因是QA在测试的过程中不希望被自动触发的部署打断,不过也可以方便的在jenkins上手动触发执行
jenkins从svn拉代码 --> 编译 --> JS/CSS合并压缩 --> 其他初始化操作 --> 生成最终线上运行的代码包,通过Dockerfile打包成镜像上传到docker hub,然后触发kubernetes滚动更新
镜像包含了基础镜像+项目代码,基础镜像就是根据项目运营环境打包的一个最小化的运行环境(不包含项目代码),根据项目依赖的技术栈不同我们打包了很多不通类型的基础镜像,例如包含nginx服务的基础镜像,包含jdk+tomcat的基础镜像
如果发现程序上线出错或有bug短时间内无法解决,可通过jenkins快速回滚到上一镜像版本,十分方便
如果发现流量突然增高,可以通过kubernetes快速调整容器副本数量
软件和工具
代码管理:svn,git
持续集成:jenkins,shell,python
Docker化:docker,harbor,kubernetes
监控报警:zabbix,prometheus
日志系统:filebeat,kafka,logstash,elasticsearch,kibana
代码管理
大部分项目还是通过svn来管理的,这里以svn为例说明,每个项目有3条代码线,dev、trunk、releases
dev: 本地开发,开发好一个功能或task就可以提交到dev分支,同时可部署到dev环境进行自测
trunk:当一个大的功能开发完成计划上线前合并代码到trunk分支,QA部署到trunk环境进行详细测试
releases:QA测试通过,项目即将上线,则将代码合并到releases分支,部署hidden环境(仿真环境,所有配置、代码等与线上保持一致)再次回归,回归通过,则上线product正式环境
有些项目是基于版本发布的,那么在代码合并到releases之后会通过branch/tag打个tag部署到hidden测试
持续集成
这一步主要工作是按照需求把源代码打包为最终线上跑的项目工程,大部分工作都有shell、python编写的脚本来完成,例如去svn拉代码、编译源代码、对静态资源文件合并压缩等等操作。利用jenkins将我们这么多分散的步骤串成一个完整的流程,运维对这一部分应该很熟悉了,不过多介绍
Docker化
Docker是我们整个方案中很重要的一块,可以方便的进行部署,所有环境使用同一Docker镜像也保证了环境的统一,大大减少了开发环境运行正常,线上运行报错的情况出现,同时可根据项目负载情况实时调整资源占用,节约成本。
Dockerfile:通过编写dockerfile来打包镜像
harbor:充当docker hub镜像仓库的作用,有web界面和api接口,方便集成
kubernetes:kubernetes(k8s)将一个一个的Docker实例给整合成了集群,方便镜像下发、升级、回滚、增加或删除副本数量,同时也提供了ingress外网访问方式,这一块比较重,不过我们也没有用到太高级的功能,只是上边提到的一些基础功能,无需对k8s进行二次开发或定制,只是部署好了使用,对运维来说技术难度不大。
监控报警
监控报警在整个运维过程中非常重要,能未雨绸缪,减少故障的发生,加快故障的解决。这一块也是运维的基础不过多介绍了
zabbix:宿主机统一通过zabbix进行监控报警
prometheus:Docker容器的运行情况通过prometheus进行监控报警(目前还未完成)
日志系统
elk日志系统真是运维的福音,用了都说好,从此再也不用听开发给你说“xx,帮我拉下线上的日志”。我们使用的架构为filebeat/rsyslog --> kafka --> logstash --> elasticsearch --> kibana
filebeat/rsyslog:client端通过filebeat或者rsyslog来收集日志,filebeat是一个go开发的程序,部署起来非常方便,跟Docker简直绝配,我们Docker基础镜像里都默认起了一个filebeat服务初始化了配置文件,后边整合项目代码的时候不需要额外配置;使用rsyslog的好处是大部分系统自带了rsyslog服务,不需要额外安装一个程序来收集日志,但是rsyslog要传数据到kafka需要用到omkafka模块,omkafka对rsyslog版本有要求,大部分系统需要升级rsyslog版本很麻烦,就放弃了
kafka:kafka就是为处理日志类数据而生,我们采用3台机器做kafka集群,同时1个topic对应多个group,避免单点
logstash:作为为从kafka取数据,过滤之后写入elasticsearch。还在想为啥介绍kafka的时候说明1个topic对应多个group?主要是为了一个group对应一个logstash index,解决掉logstash这里的单点
elasticsearch:存储过滤之后的数据,同样采用了3个节点的集群,避免单点
kibana:可视化工具,方便的来搜索想要的数据,同事也做各种报表,一目了然
总结
支持:要获得各方的支持,项目已经成功了一半,没有啥事一顿烧烤解决不了的,如果有就两顿
规范:众多的项目,庞大的系统,必须要有规范,规范是自动化的基础
文档:实施的详细过程、如何使用、怎么维护要保留有详细文档
培训:对于jenkins、elk非运维使用的工具要对使用者有相应的培训分享,当然运维内部也要分享项目的种种细节


上篇:
基于Docker搭建Percona XtraDB Cluster数据库集群
下篇:
Docker镜像仓库Harbor之搭建及配置
1 2026 年 AI 创业全景指南:给渴望借 AI 逐梦的人! 2 扣子(Coze)工作流实战:篇篇10W+的小林漫画,用Coze实现了爆款流水线生... 3 剖析Mini-SGLang,打开LLM推理引擎的黑盒世界 4 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 5 快到2026啦 必须掌握的AI智能体全栈技术! 6 根据工作岗位要求, 写一份现场面试者工作自我介绍简述, 要求800字 7 5分钟一键生成软著申请材料,coze工作流全教程,含提示词 8 Qwen3-Coder 实战!历史人物短视频一键生成,多分镜人物不崩 9 不想上班,居家可以做的10份工作(附上方法) 10 10个真正赚钱的AI利基市场 11 运维必备:掌握这3个存储技术 12 win11 连接共享打印机报错:0x00000040 或者 .709或者 .11...