我用本地DeepSeek+Python打造写作AI,十分钟生成一本专业书籍 - 今日头条
一、前言:
为什么AI写作将成为每个人的“超级助手”?
你有没有想过,有一天,写书、创作内容甚至完成复杂的工作任务,都可以交给一个由你自己打造的AI助手来完成?听起来像是科幻电影里的情节,对吧?但今天,这一切已经成为现实。
在过去的几年里,人工智能技术飞速发展,尤其是像DeepSeek这样的大语言模型的出现,彻底改变了我们与信息交互的方式。然而,仅仅依赖现成的工具是远远不够的——如果你想真正掌控AI的力量,就需要学会如何构建属于自己的AIAgent(人工智能代理) 。
本文将带你走进一个全新的世界:通过Python+LangChain ,从零开始搭建一个属于你的智能写作助手。无论你是想写小说、出书、制作教程,还是生成专业报告,这个AI助手都能为你提供强大的支持。

二、环境准备
1. 创建虚拟环境(使用Anaconda)
conda create --name ds_py310 python=3.10.12 activate ds_py310
2. 安装相关包
pip install langchain==0.3.13 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install langchain-community==0.3.13 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install openai==1.58.1 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install dashscope==1.20.14 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install ollama==0.4.7 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install tqdm==4.67.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 安装ollama,下载模型
ollama run deepseek-r1:8b ollama run bge-m3:latest
三、Python+本地deepseek写作AI源码
由于大型语言模型在生成内容时存在 token 数量的限制,直接生成一整本书不仅难以实现,而且生成的内容质量可能无法保证。
为了解决这一问题,我们通过 Python 代码巧妙地规避了 token 限制,分步骤、分章节地生成书籍内容,从而确保生成的质量和连贯性。
下面以生成一本名为《机器学习从入门到精通》的书籍为例,展示如何利用 Deepseek 模型完成这一任务,并测试其效果。
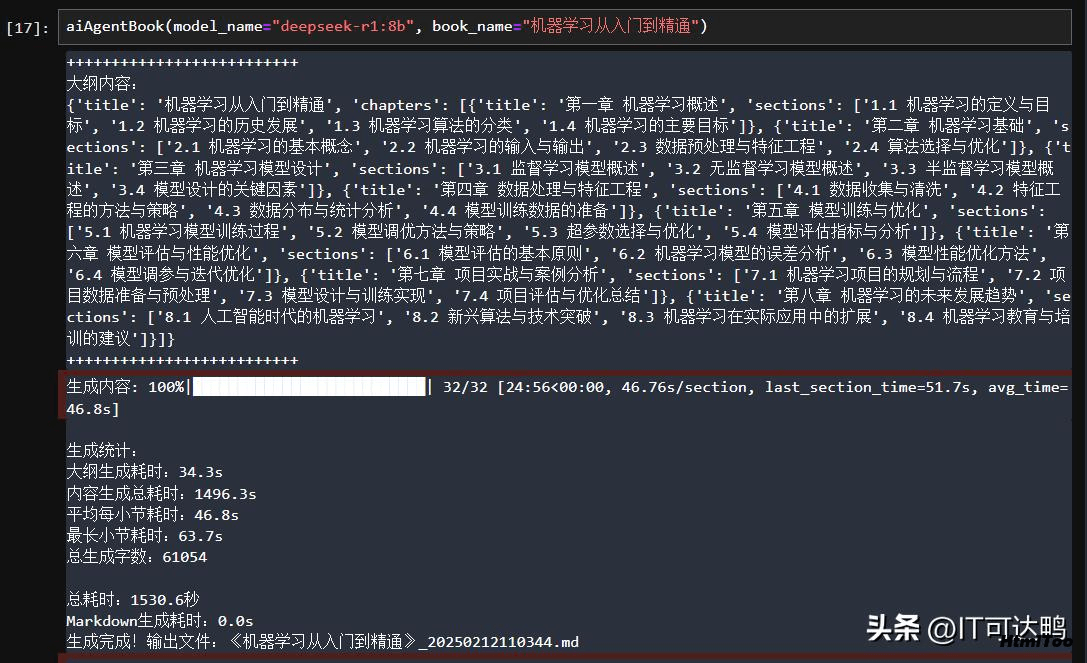
后台显示

AI生成的专业书
下面给出源码:
1. 导入相关包
import json import time import re import functools from datetime import datetime from typing import Dict, List, Optional from langchain_core.prompts import PromptTemplate from langchain_core.output_parsers import JsonOutputParser from langchain_core.language_models import BaseLLM from langchain.llms import Ollama from tqdm import tqdm
2. 定制pompt,用于生成书籍目录、根据章节小节标题生成循环小节内容
prompt_book_catalog = """
你是一本专业书籍的作者,请为《{topic}》生成书籍大纲,要求:
1. 包含至少8章
2. 每章包含2-5个小节
3. 使用JSON格式返回,包含title字段和chapters数组
4. chapters数组中每个元素包含title和sections数组
5. 章节名称前加上第几章
6. 小节前面加上小节的序号
示例格式:
{{
"title": "书籍标题",
"chapters": [
{{
"title": "章标题",
"sections": ["小节1", "小节2"],
}}
]
}}
请开始为《{topic}》生成大纲:
"""
# 3. 展示思考链(如:本节将首先探讨...接着分析...最后总结...)
# 4. 字数不少于500字
# 5. 如果有代码示例,请使用pytorch
prompt_chapter = """
你正在编写《{book_title}》的{chapter}章节,请撰写'{section}'小节的内容。
要求:
1. 包含详细的专业知识点
2. 使用Markdown格式
当前章节:{chapter}
当前小节:{section}
开始撰写:
"""3. 写作AI类
class BookGenerator:
def __init__(self, llm: BaseLLM):
self.llm = llm
self.json_parser = JsonOutputParser()
self.timings = {} # 存储各阶段耗时数据
self.section_timings = []
self.current_title = ""
self.contents = []
def timing_decorator(func):
"""耗时统计装饰器"""
@functools.wraps(func)
def wrapper(self, *args, **kwargs):
start_time = time.time()
result = func(self, *args, **kwargs)
elapsed = time.time() - start_time
self.timings[func.__name__] = elapsed
return result
return wrapper
def replace_think(self, content):
"""过滤掉思维链"""
return re.sub(r"<think>.*?</think>", "", content, flags=re.DOTALL)
@timing_decorator
def generate_outline(self, topic: str) -> Dict:
# 步骤1:生成书籍大纲
outline_prompt = PromptTemplate.from_template(prompt_book_catalog)
chain = outline_prompt | self.llm | self.replace_think | self.json_parser
max_retries = 3
for _ in range(max_retries):
try:
result = chain.invoke({"topic": topic})
# 验证必要字段
assert "title" in result
assert "chapters" in result and len(result["chapters"]) > 0
return result
except (json.JSONDecodeError, AssertionError) as e:
print(f"大纲生成错误,重试中... ({_+1}/{max_retries})")
continue
raise ValueError("大纲生成失败,请检查模型输出")
def generate_content(self, outline: Dict) -> List[Dict]:
self.current_title = outline["title"]
all_contents = []
total_sections = self._count_total_sections(outline)
with tqdm(total=total_sections, desc="生成内容", unit="section") as self.progress_bar:
chapter_counters = {0: 0} # 主章节计数器初始化
for chapter in outline["chapters"]:
# 为每个主章节维护独立的计数器
all_contents += self._process_chapter(chapter, level=0, counters=chapter_counters.copy())
chapter_counters[0] += 1 # 主章节计数器递增
return all_contents
def generate_markdown(self, contents: List[Dict]) -> str:
md = [f"# {self.current_title}\n\n"]
for item in contents:
if item["type"] == "chapter":
# 章节标题使用 level+1 的#数量
heading_level = item['level'] + 1
md.append(f"{'#' * heading_level} {item['title']}\n")
for section in item["sections"]:
# 小节标题使用 level+2 的#数量
section_level = item['level'] + 2
md.append(f"{'#' * section_level} {section['title']}\n")
md.append(section["content"] + "\n\n")
return "\n".join(md)
def _count_total_sections(self, outline: Dict) -> int:
"""递归计算总小节数"""
count = 0
for chapter in outline["chapters"]:
count += len(chapter.get("sections", []))
for sub in chapter.get("subchapters", []):
count += self._count_total_sections({"chapters": [sub]})
return count
def _process_chapter(self, chapter: Dict, level: int = 0,
counters: dict = None) -> List[Dict]:
if counters is None:
counters = {0: 0}
# 更新当前层级计数器
current_level = level
counters[current_level] = counters.get(current_level, 0) + 1
# 生成章节编号
number_parts = []
for l in range(current_level + 1):
number_parts.append(str(counters[l]))
chapter_number = ".".join(number_parts)
title = chapter['title']
# 处理小节编号
sections = []
for section_title in chapter.get("sections", []):
sections.append({
"title": section_title,
"content": self._generate_section_content(title, section_title, level)
})
self.progress_bar.update(1)
return [{
"type": "chapter",
"title": title,
"level": level,
"sections": sections
}]
def _generate_section_content(self, chapter_title: str, section_title: str, level: int) -> str:
# 生成单个小节内容,并统计时长
start_time = time.time()
prompt = PromptTemplate.from_template(prompt_chapter)
try:
# 过滤掉思维链
chain = prompt | self.llm | self.replace_think
content = chain.invoke({
"book_title": self.current_title,
"chapter": chapter_title,
"section": section_title,
"level": level
})
# 记录生成时间
elapsed = time.time() - start_time
self.section_timings.append(elapsed)
self.progress_bar.set_postfix({
"last_section_time": f"{elapsed:.1f}s",
"avg_time": f"{sum(self.section_timings)/len(self.section_timings):.1f}s"
})
return content
except Exception as e:
print(f"生成失败:{str(e)}")
return ""
def print_statistics(self):
"""打印统计信息"""
print("\n生成统计:")
print(f"大纲生成耗时:{self.timings.get('generate_outline', 0):.1f}s")
print(f"内容生成总耗时:{sum(self.section_timings):.1f}s")
print(f"平均每小节耗时:{sum(self.section_timings)/len(self.section_timings):.1f}s")
print(f"最长小节耗时:{max(self.section_timings):.1f}s")
print(f"总生成字数:{sum(len(c['content']) for item in self.contents for c in item['sections'])}")4. 生成大纲,生成内容,生成markdow文件
def aiAgentBook(model_name="deepseek-r1:8b", book_name="Python后端开发入门到精通"):
# 初始化本地模型
llm = Ollama(model=model_name)
generator = BookGenerator(llm)
current_time = datetime.now().strftime("%Y%m%d%H%M%S")
file_name = "《" + book_name + "》_" + current_time + ".md"
try:
# 总计时
total_start = time.time()
# 生成大纲
outline = generator.generate_outline(book_name)
print("++++++++++++++++++++++++++")
print("大纲内容:")
print(outline)
print("++++++++++++++++++++++++++")
# 生成内容
start_content = time.time()
contents = generator.generate_content(outline)
generator.contents = contents # 保存内容用于统计
# 生成Markdown
start_md = time.time()
md = generator.generate_markdown(contents)
# 总耗时
total_time = time.time() - total_start
# 保存文件
current_time = datetime.now().strftime("%Y%m%d%H%M%S")
with open(file_name, "w", encoding="utf-8") as f:
f.write(md)
# 打印统计
generator.print_statistics()
print(f"\n总耗时:{total_time:.1f}秒")
print(f"Markdown生成耗时:{time.time()-start_md:.1f}s")
print("生成完成!输出文件:" + file_name)
except Exception as e:
print(f"生成失败:{str(e)}")5. 调用函数
aiAgentBook(model_name="deepseek-r1:8b", book_name="pytorch从入门到精通")

十多分钟就生成一本专业书籍了。
四、结语
技术的世界从来不怕“小白”,只怕停下学习的脚步。今天的你已经迈出了关键一步,未来还有更多有趣的技术等待你去解锁。如果你觉得这篇文章对你有帮助,不妨点个赞、收藏或分享给更多志同道合的朋友,让更多人一起加入AI开发的行列!


上篇:
10分钟用deepseek写30万字小说详细指令,不会的请看过来
下篇:
AI制作小说短视频 全链路操作指南
1 扣子(Coze)工作流实战:篇篇10W+的小林漫画,用Coze实现了爆款流水线生... 2 用AI自动生成爆款文案的完整流程 3 开拍推出口播视频Agent,通过“AI口播助手”助力商家降本增效 4 提示词太水了?AI 制作的太假?怎么看起来更高级。 5 书单模板制作方法!醒图教你如何制作育儿书单 6 即梦智能多帧长达45s视频!连续创作 7 豆包新功能4.0来了!全免费,案例实测 8 DeepSeek如何颠覆短视频创作?三步生成内容,人人都是导演 9 用豆包搞定连贯分镜头视频,超简单 10 不想上班,居家可以做的10份工作(附上方法) 11 AI推理: 引导尺度, 采样步数, 采样偏移 12 15个作品涨粉26万!手把手教你用AI制作爆款睡前历史故事!