摘要
Redis 是在开发过程中经常用到的缓存中间件,在生产环境中为了考虑稳定性和高可用一般为集群模式的部署。 常规部署在虚拟机上的方式配置繁琐并且需要手动重启节点,而使用 K8s 进行 Redis 集群的部署有以下优点:
安装便捷:使用镜像或者 yaml 配置文件即可一件安装
自动调度:容器挂掉后会自动调度重启和资源分配
缩扩容方便:在 扩容、缩容 方面的优点无需多说,一键伸缩
稳定高效:K8s 在整个集群上进行调度,只要整个集群不挂掉总会调度到合适节点重启容器服务
一、配置 redis.conf 字典
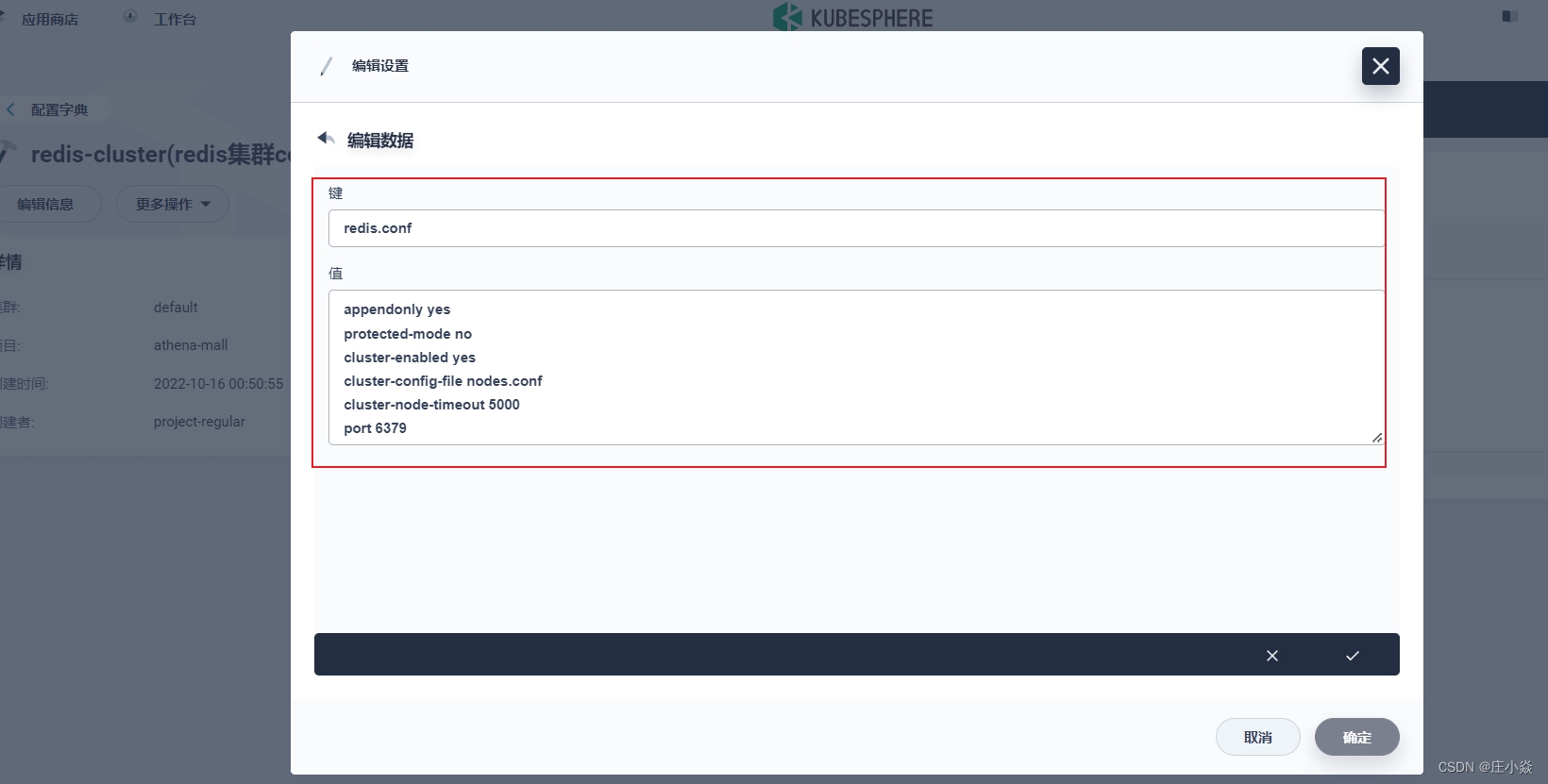
在项目空间的 配置配置字典中创建进行配置字典的创建。
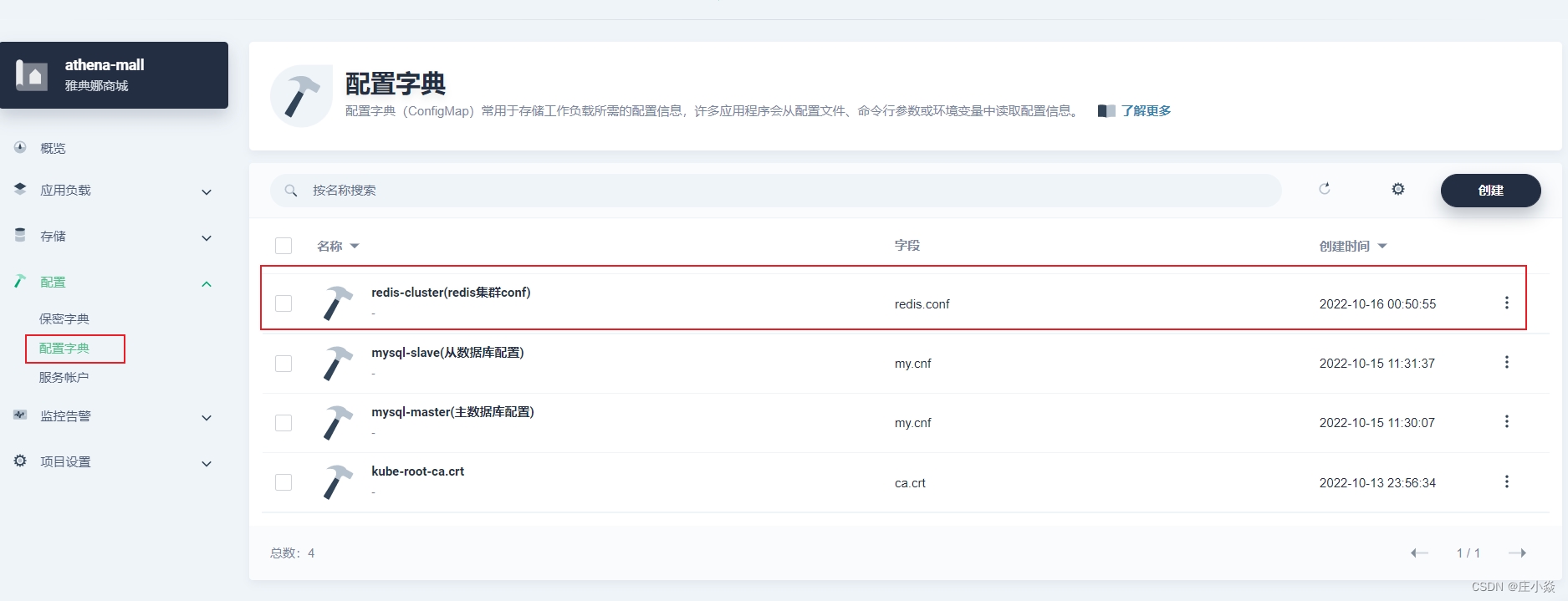
key 值的内容为 redis.conf,value 值为:
cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 cluster-require-full-coverage no cluster-migration-barrier 1 appendonly yes
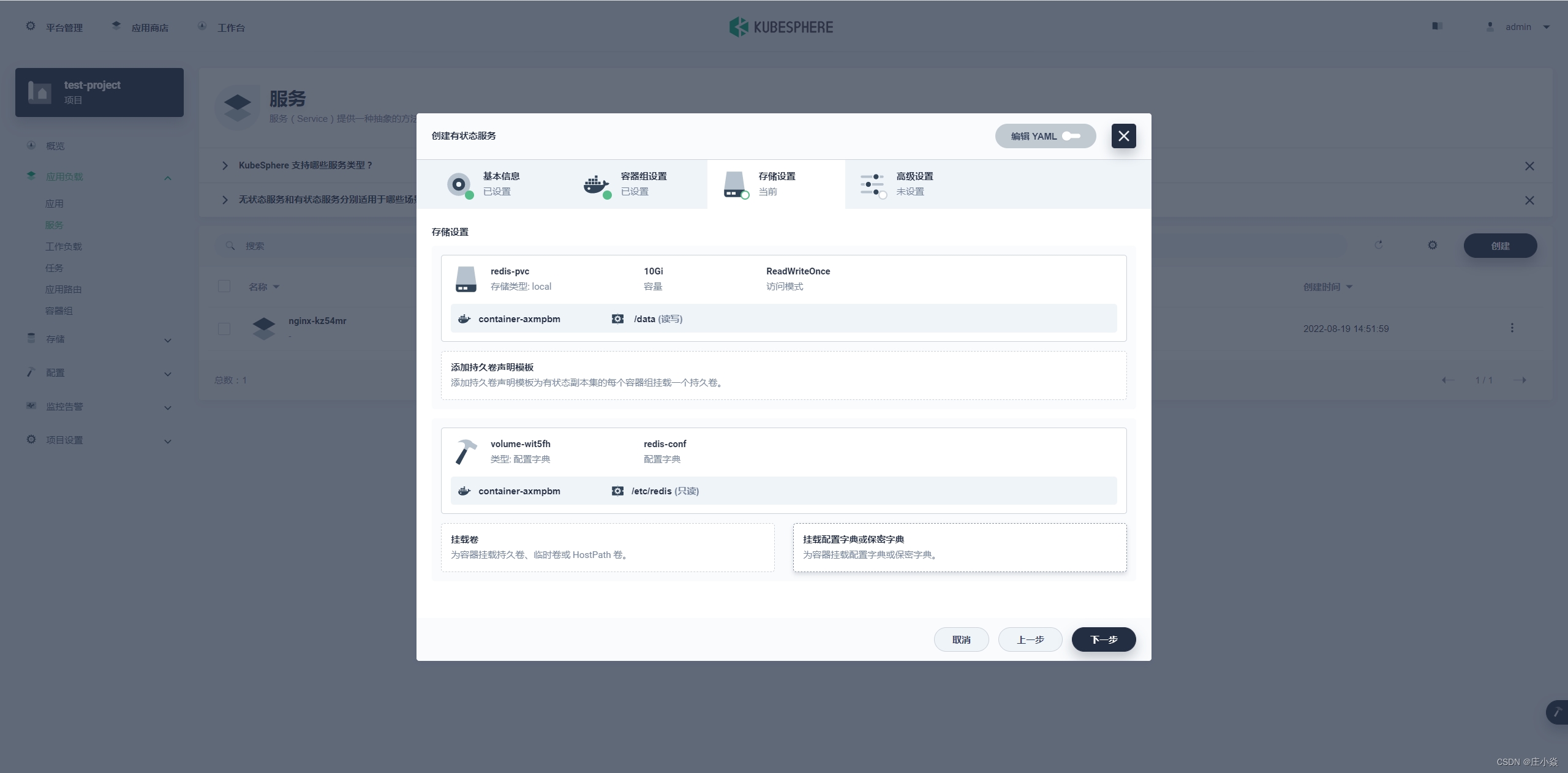
二、redis-cluster-pvc设置
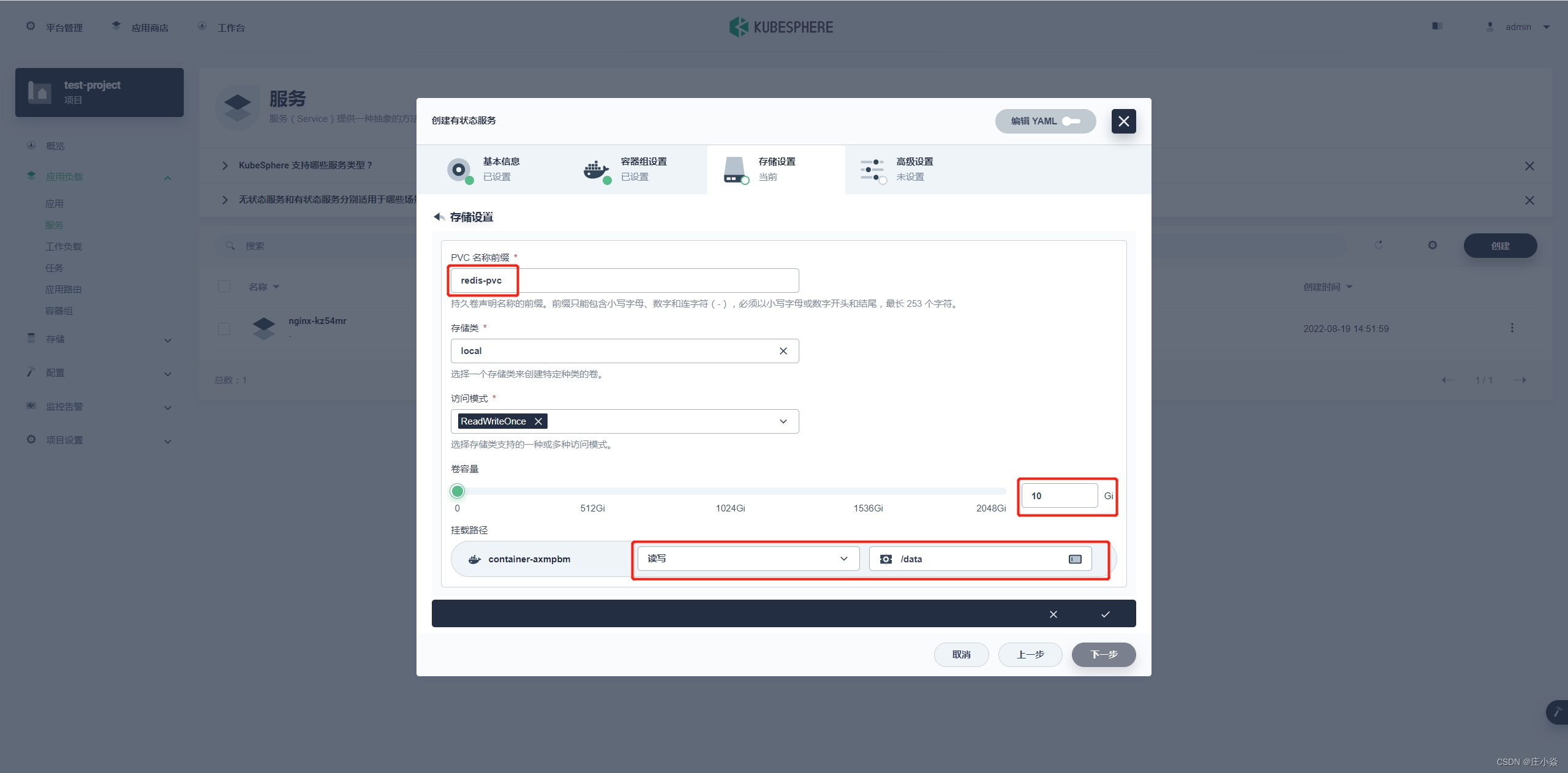
redis-cluster-pvc存储卷设置
PVC 名称前缀:redis-pvc 容量:10G
权限:读写
挂载路径:/data
三、创建 redis-cluster服务
在项目空间的 应用负载 :服务中创建进行Redis集群服务的创建
基本设置里名称就叫redis-cluster然后进行重头戏,下一步的容器组配置
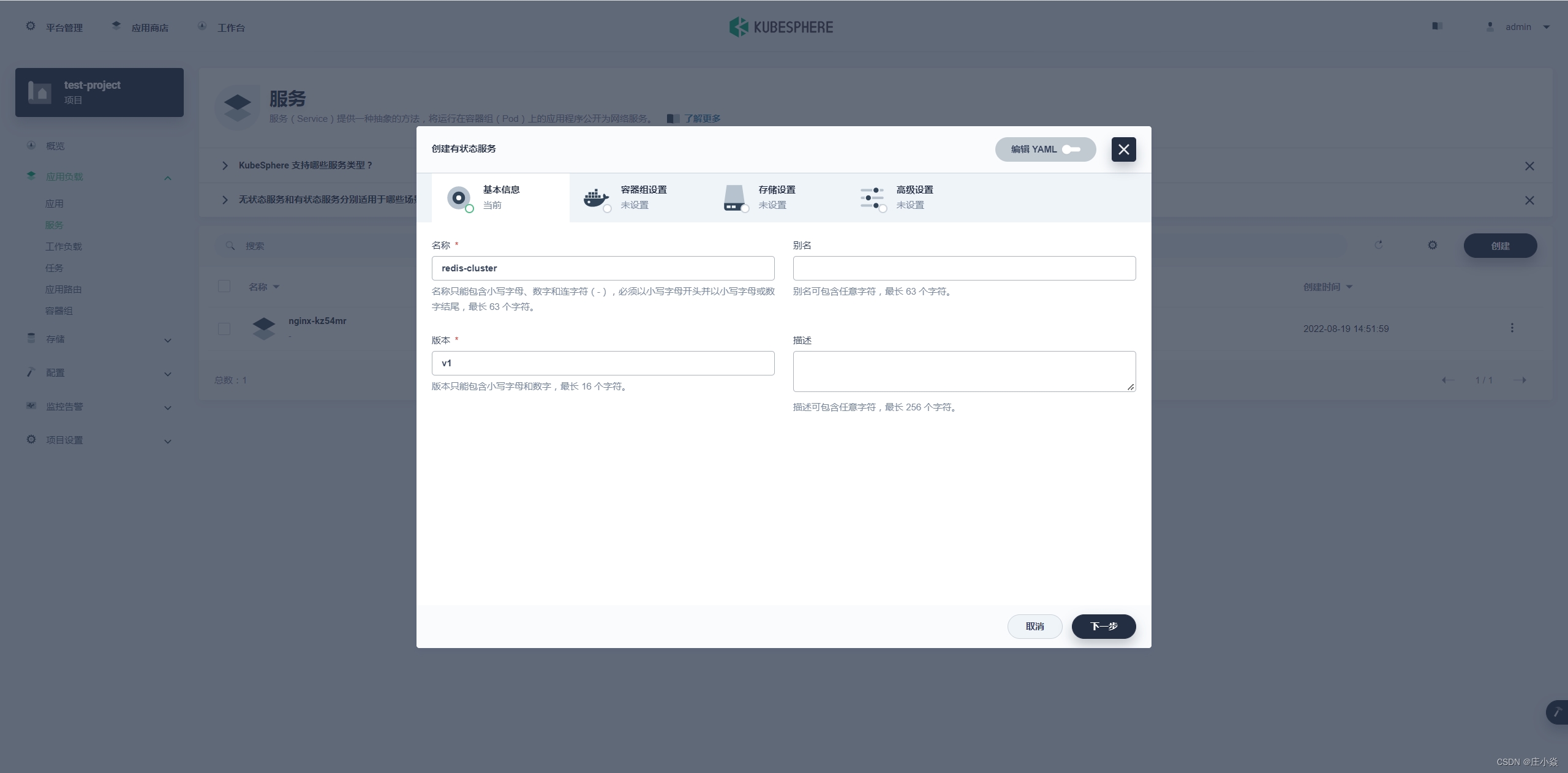
注意: 如果集群构建失败后需要重新删除原有的pvc 重新构建新的pvc。
四、容器组配置
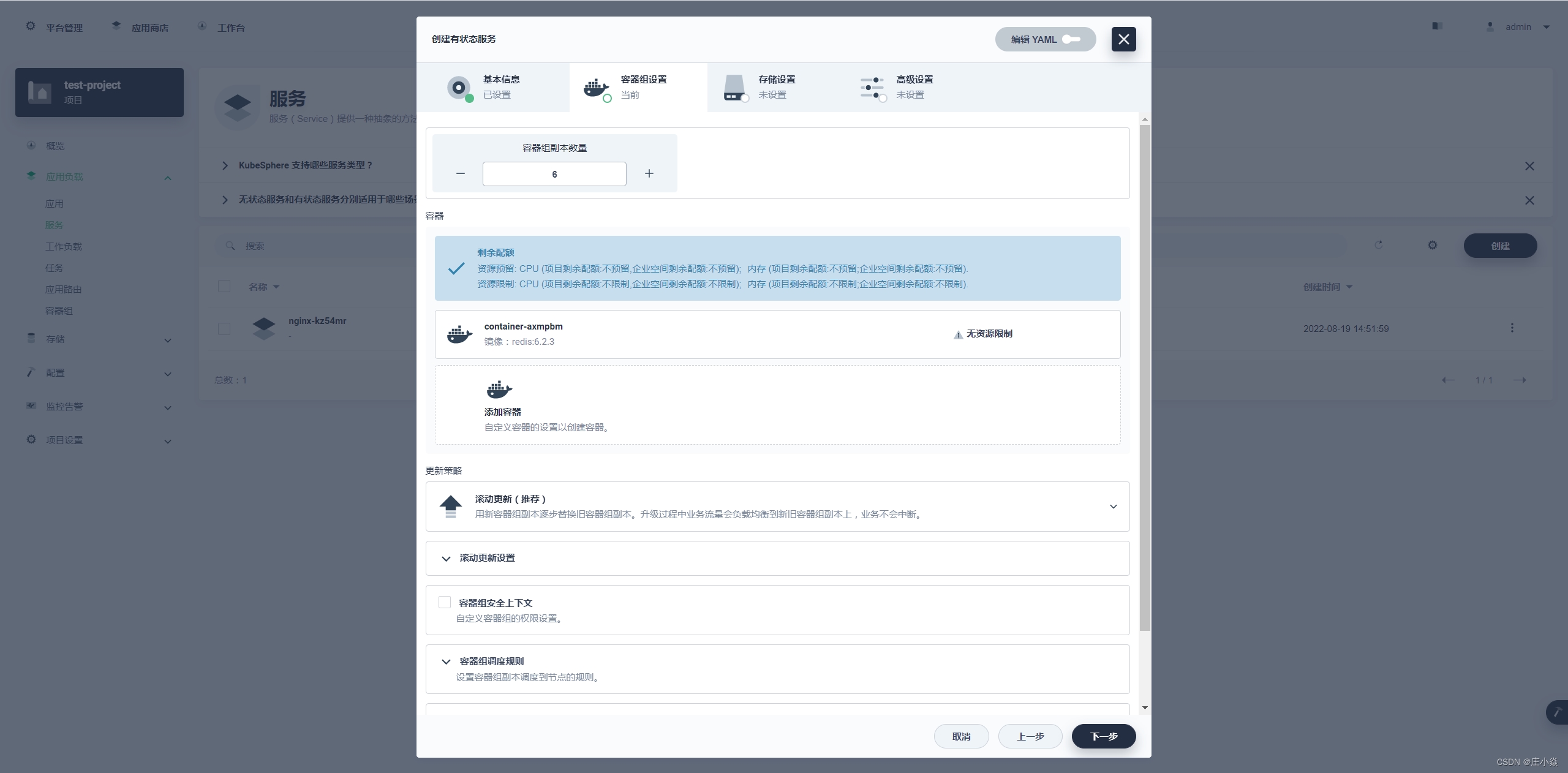
这一步的核心就是配置 Redis 的容器,集群数量就选择常规的三主三从,那容器的副本数量就是 6 个。
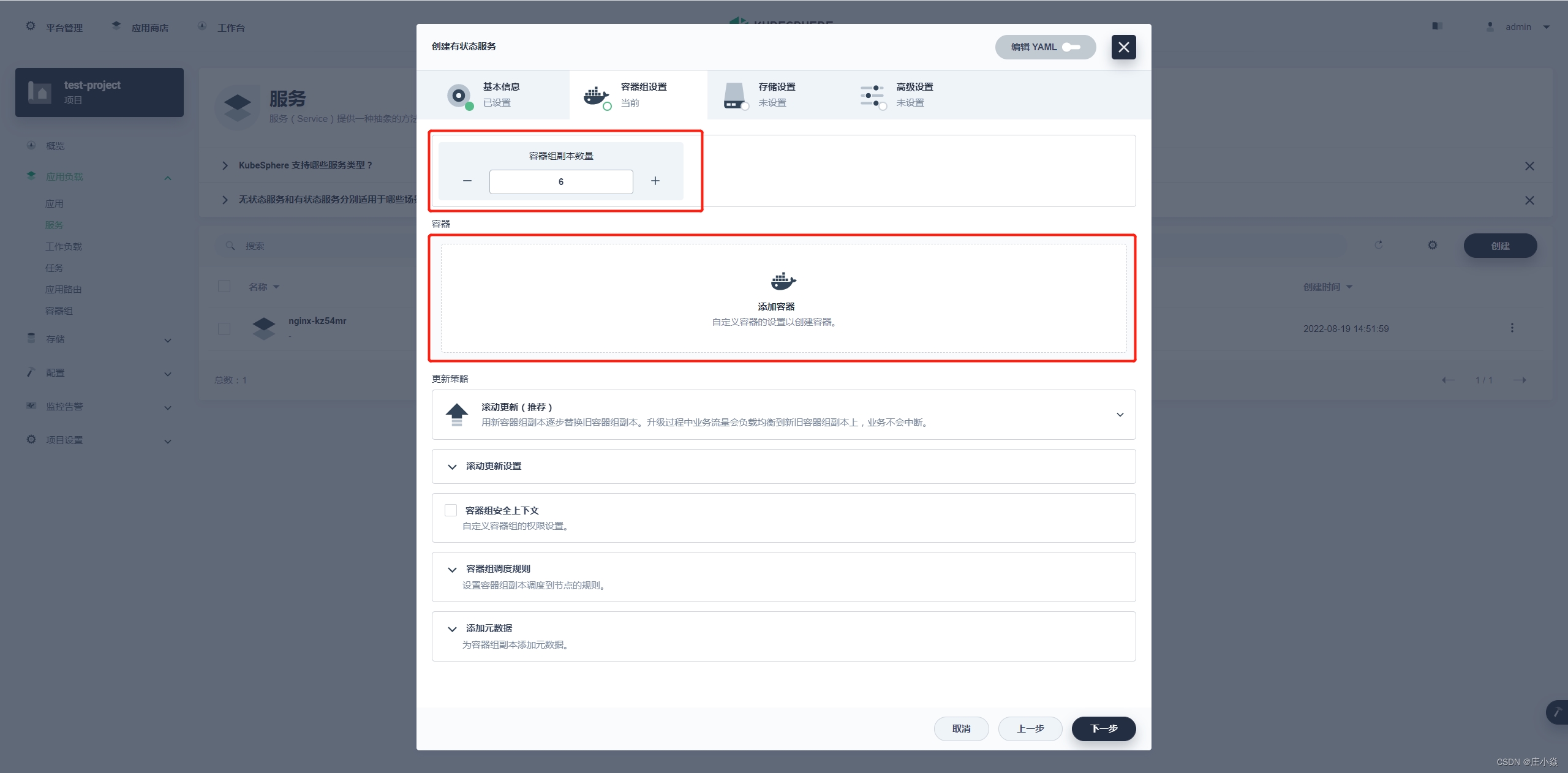
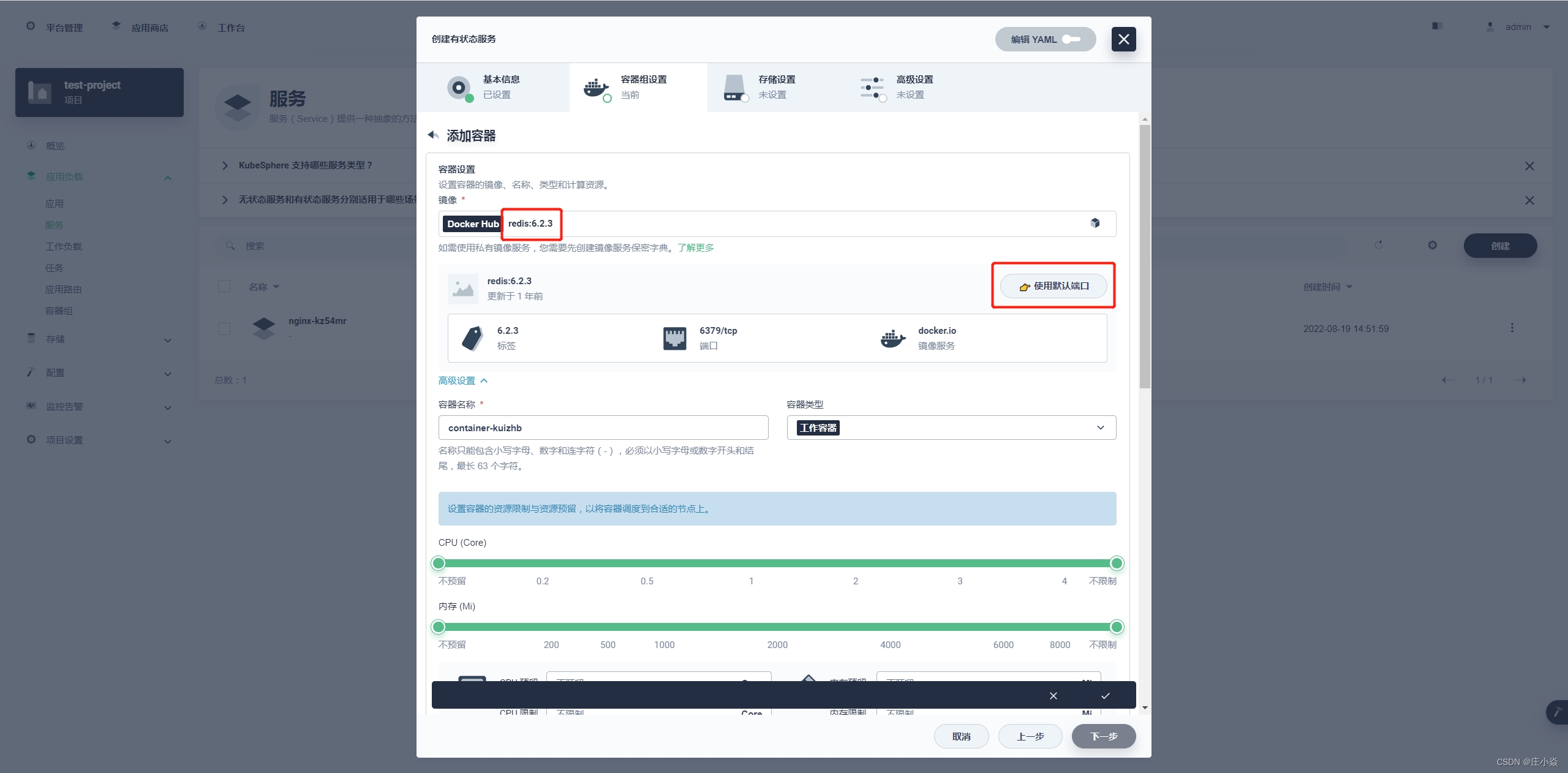
镜像选择 docker hub(可以选择私有仓库) 中 redis 的 5.0.7版本,并选择使用默认端口,CPU 和内存可以选择性预留, 如果不预留就是调度公共资源(最好是选择合适的,这样方便统计资源)。 选择使用默认端口的话下面的端口设置就是如上图一样都会使用 6379,还有就是配置启动命令。
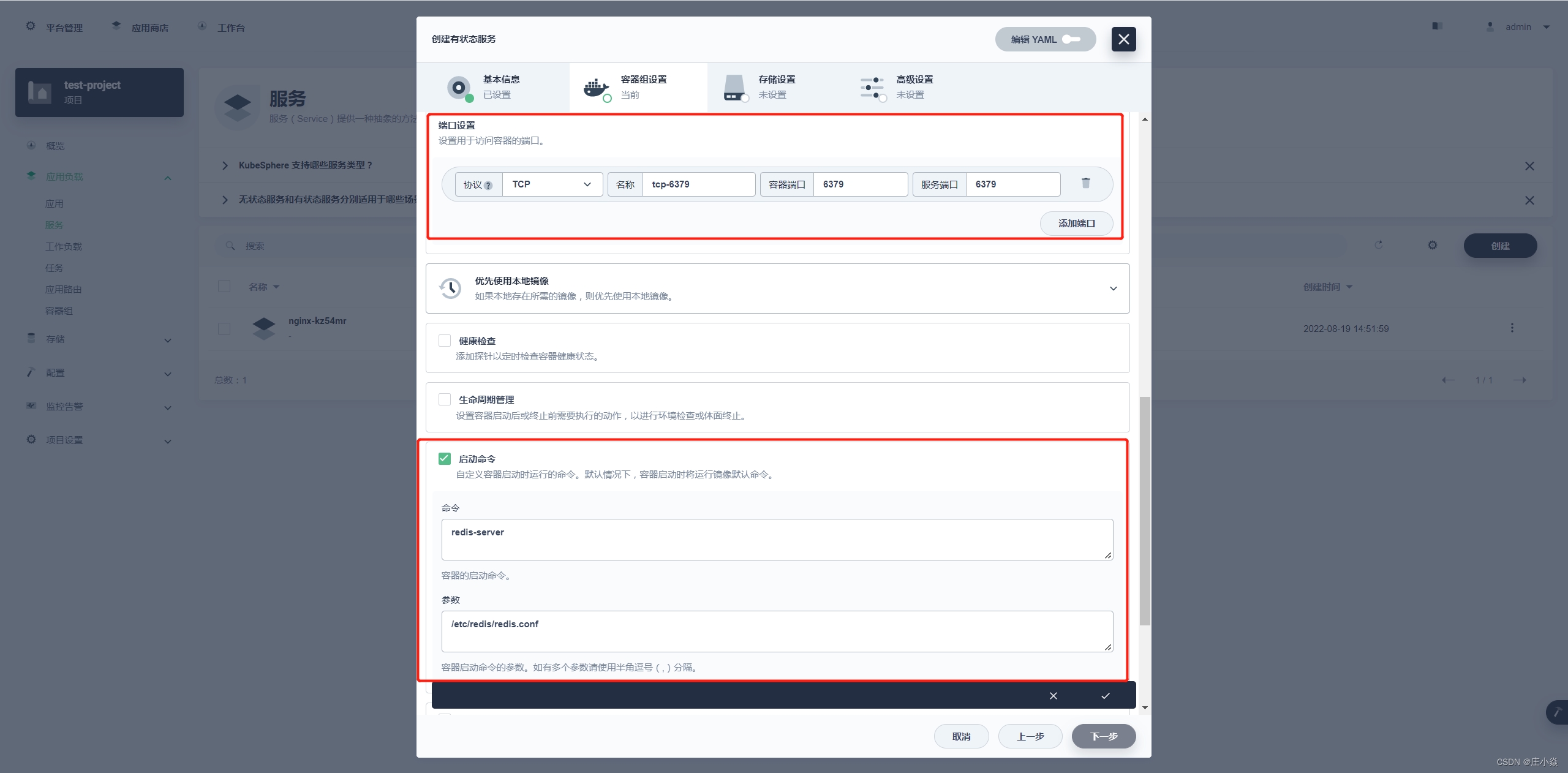
如上图配置:
命令:redis-server
参数:/etc/redis/redis.conf 参数指向的就是之前字典配置的内容,但是需要下一步存储设置里进行配置字典才能使用。
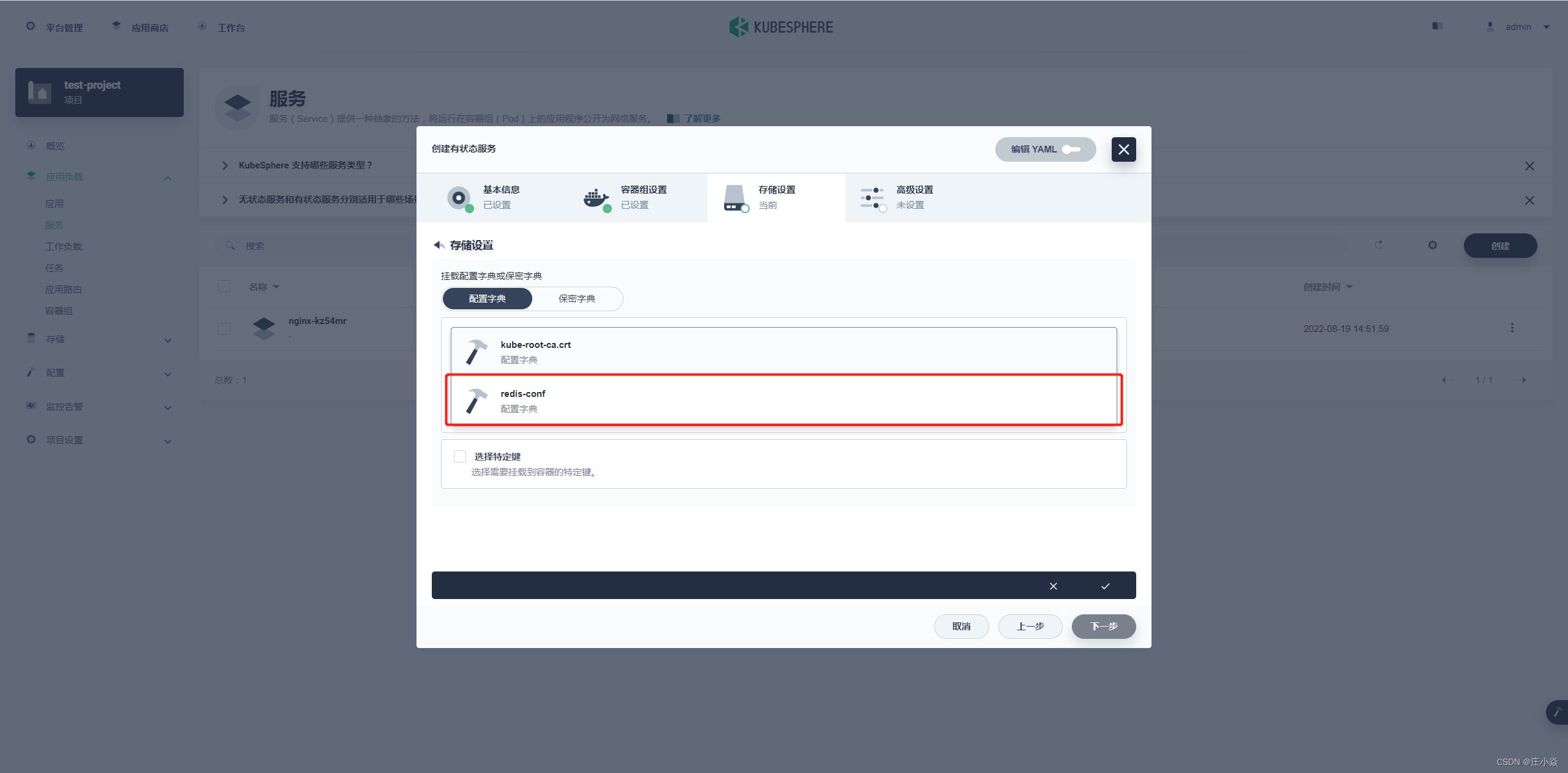
高级设置里是一些额外配置,可以根据自己场景选择调整配置,调成完成后点击创建 进行 Redis 集群容器的创建。
五、初始化 Redis 集群
5.1 IP 地址初始化集群
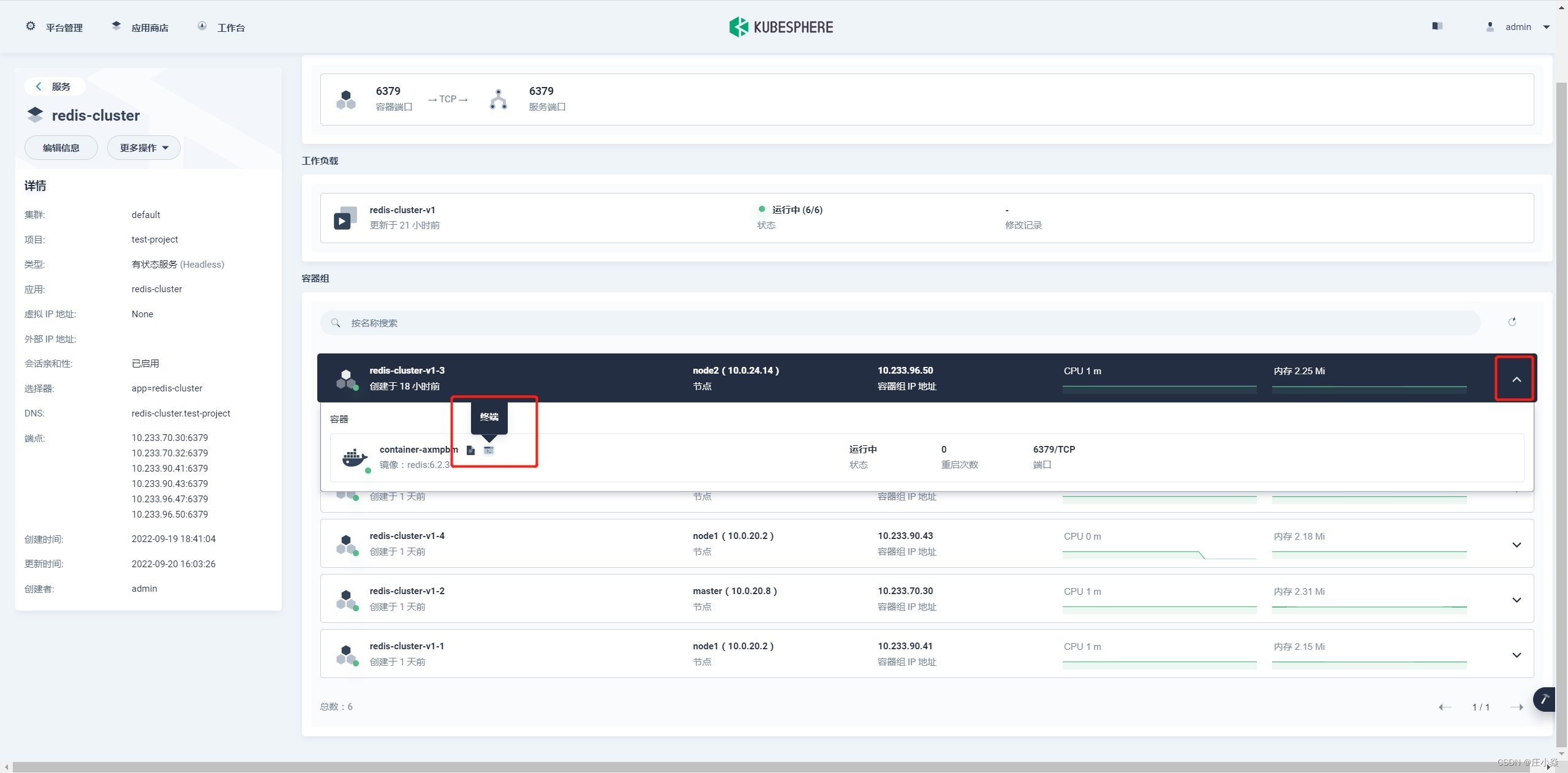
创建完 Redis 服务后点击 redis 的服务名称进入 redis 服务详情,详情如下图
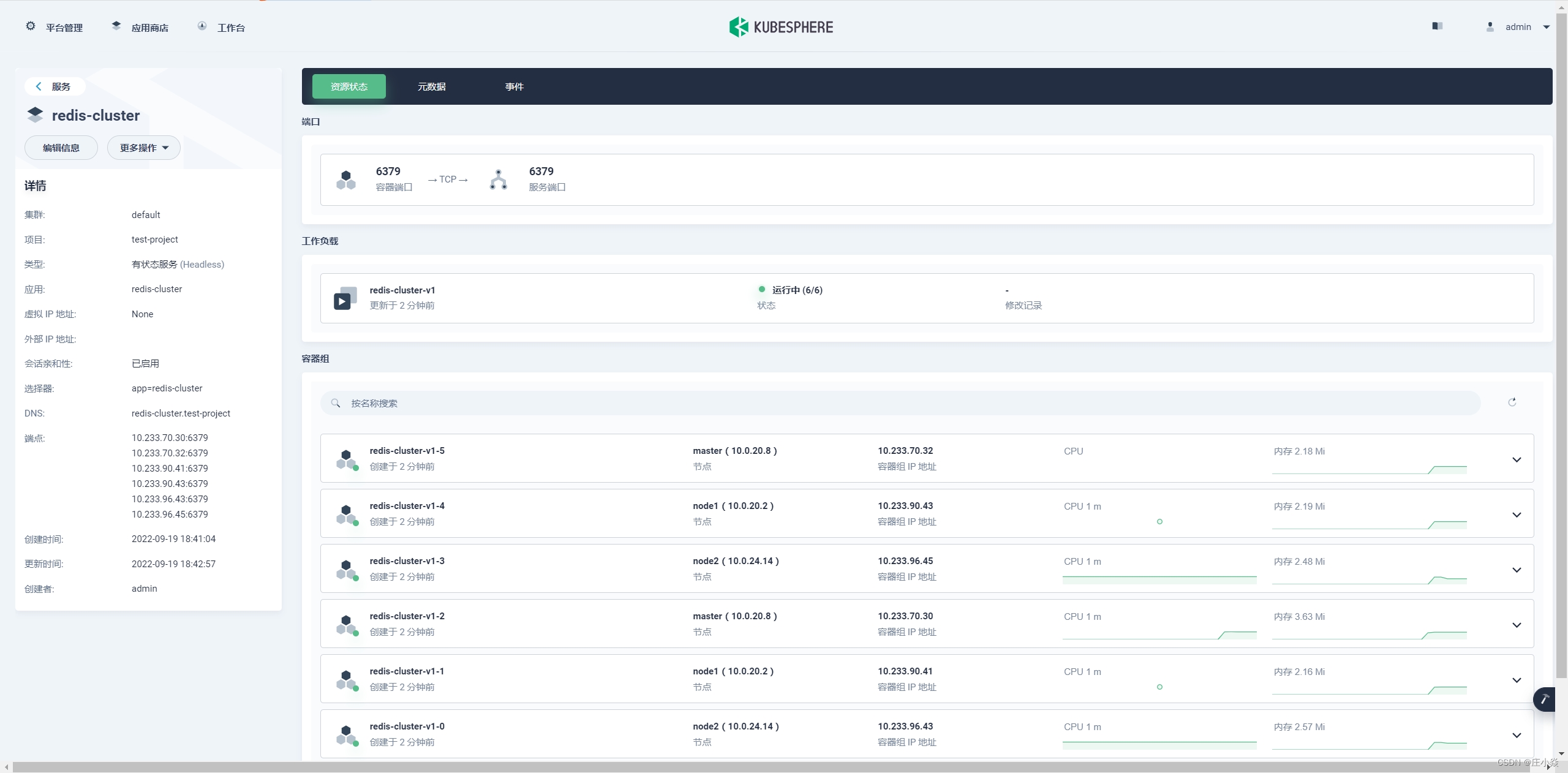
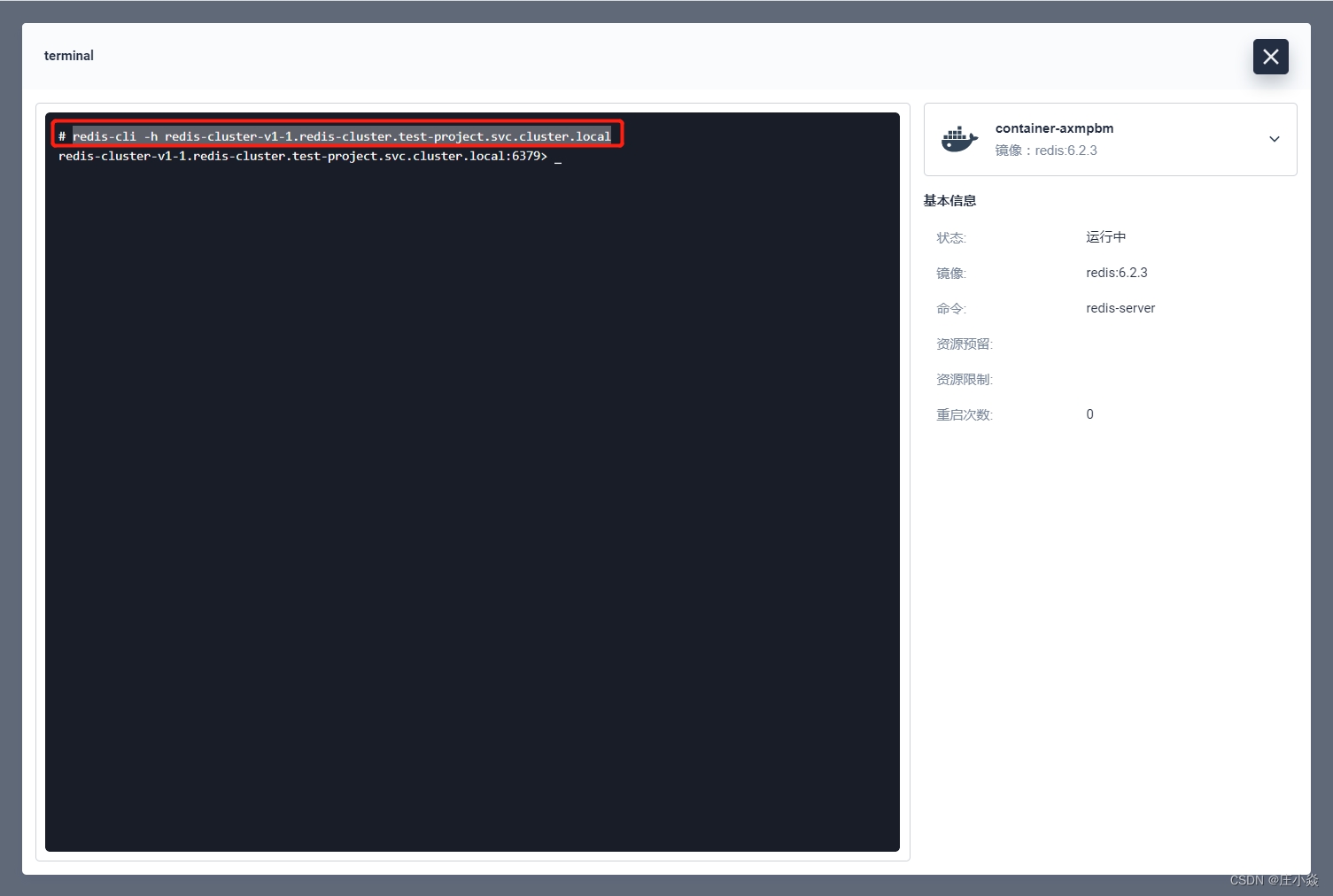
6 个 redis 的容器组都启动成功了,接下来就是初始化集群;因为我们配置的 redis 的服务是有状态服务 (Headless) 所以访问模式可以通过内部 DNS, 访问格式是:(容器名称).( 容器 DNS).svc.cluster.local。随意执行下面的命令:
redis-cli -h redis-cluster-v1-5.redis-cluster.athena-mall.svc.cluster.local redis-cli -h redis-cluster-v1-4.redis-cluster.athena-mall.svc.cluster.local redis-cli -h redis-cluster-v1-3.redis-cluster.athena-mall.svc.cluster.local redis-cli -h redis-cluster-v1-2.redis-cluster.athena-mall.svc.cluster.local redis-cli -h redis-cluster-v1-1.redis-cluster.athena-mall.svc.cluster.local redis-cli -h redis-cluster-v1-0.redis-cluster.athena-mall.svc.cluster.local
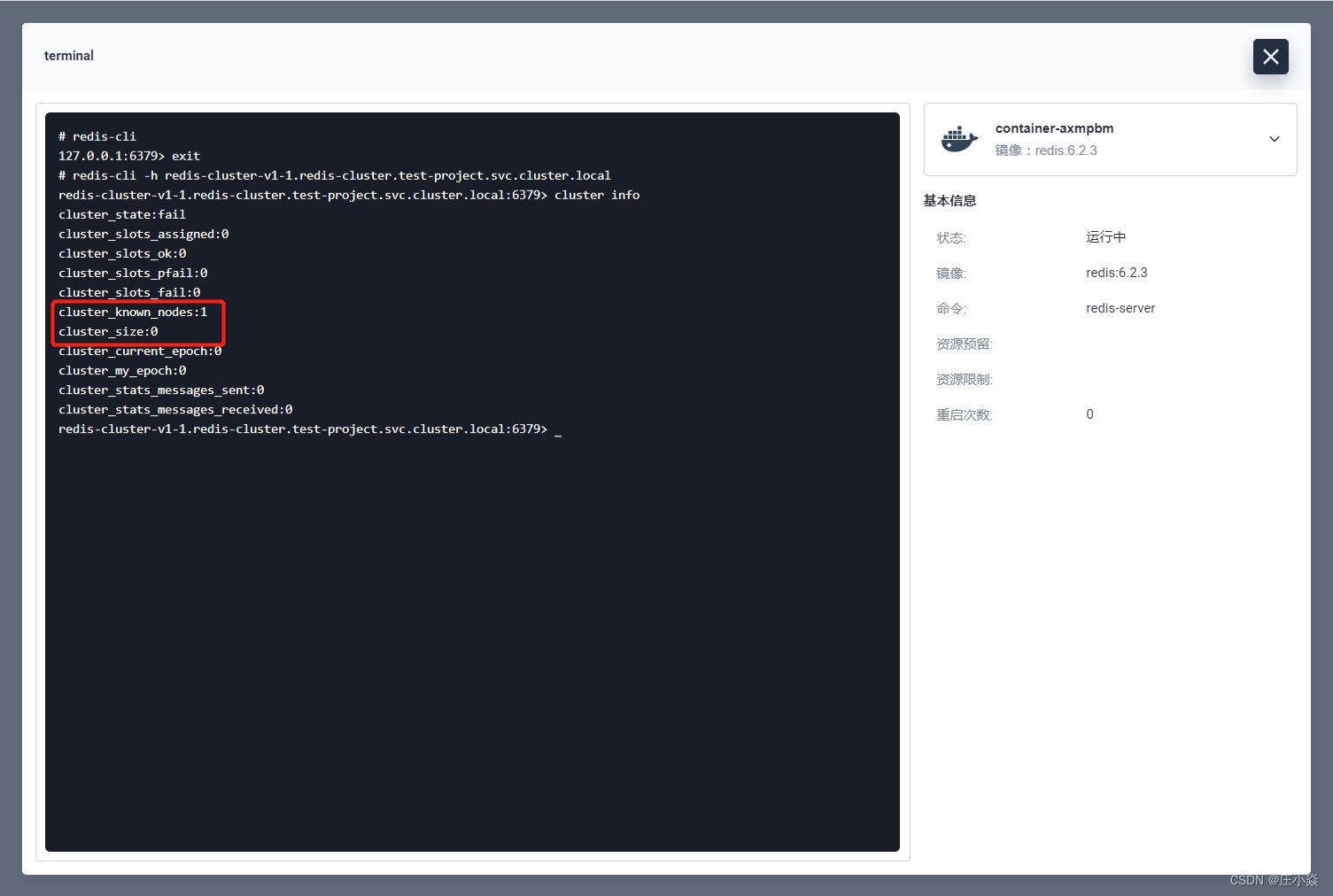
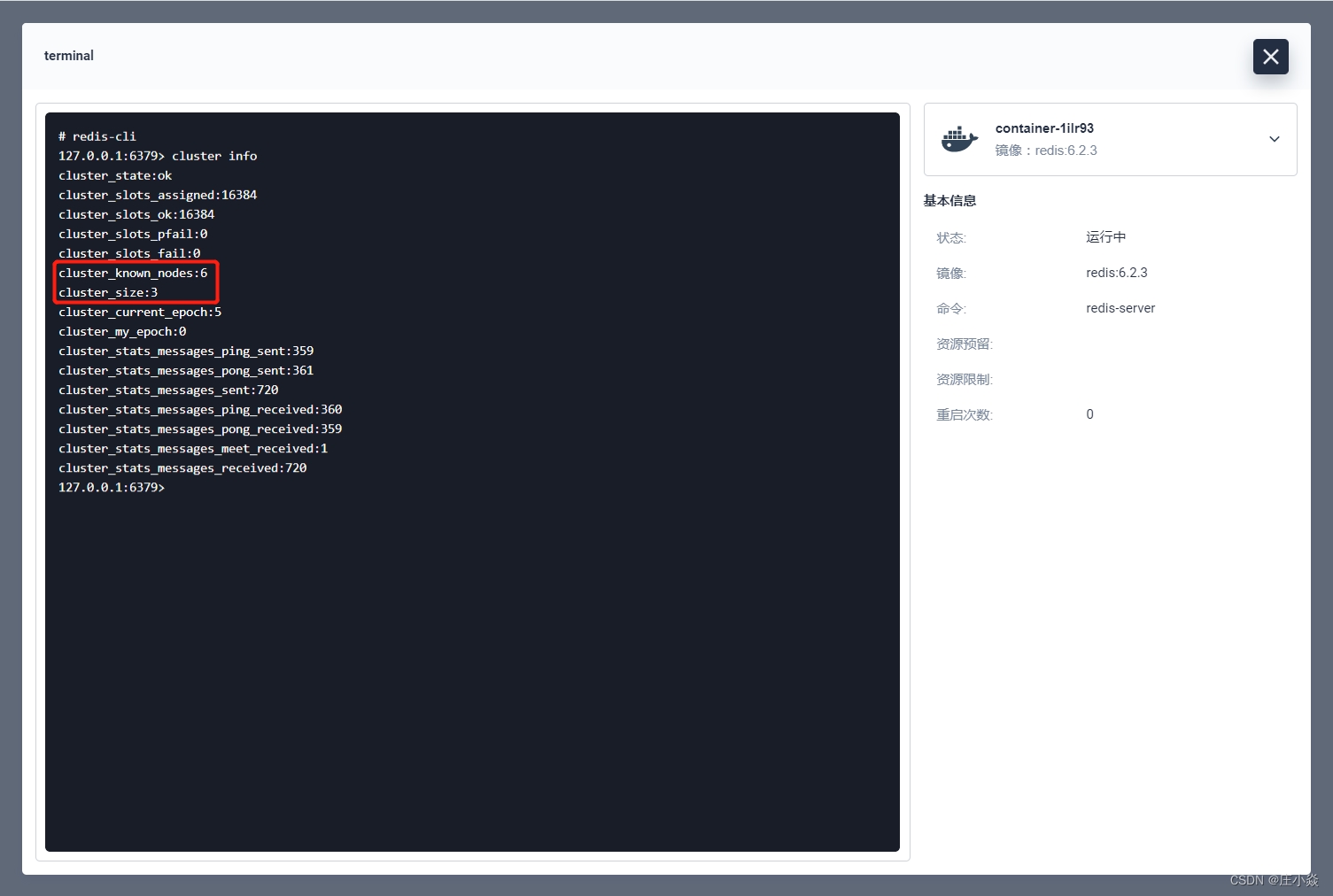
主要看上图的这两个参数,nodes 为 1 表明当前节点只有 1 个,cluster_size 表明当前没有 master 节点,所以目前还不是集群结构,info 属性的详解在此列出:
cluster_state:ok 状态表示集群可以正常接受查询请求。fail 状态表示,至少有一个哈希槽没有被绑定(说明有哈希槽没有被绑定到任意一个节点),或者在错误的状态(节点可以提供服务但是带有 FAIL 标记),或者该节点无法联系到多数 master 节点。
cluster_slots_assigned:已分配到集群节点的哈希槽数量(不是没有被绑定的数量)。16384 个哈希槽全部被分配到集群节点是集群正常运行的必要条件。
cluster_slots_ok:哈希槽状态不是 FAIL 和 PFAIL 的数量。
cluster_slots_pfail:哈希槽状态是 PFAIL 的数量。只要哈希槽状态没有被升级到 FAIL 状态,这些哈希槽仍然可以被正常处理。PFAIL 状态表示我们当前不能和节点进行交互,但这种状态只是临时的错误状态。
cluster_slots_fail: 哈希槽状态是 FAIL 的数量。如果值不是 0,那么集群节点将无法提供查询服务,除非 cluster-require-full-coverage 被设置为 no。
cluster_known_nodes:集群中节点数量,包括处于握手状态还没有成为集群正式成员的节点。
cluster_size:至少包含一个哈希槽且能够提供服务的 master 节点数量。
cluster_current_epoch:集群本地 Current Epoch 变量的值。这个值在节点故障转移过程时有用,它总是递增和唯一的。
cluster_my_epoch:当前正在使用的节点的 Config Epoch 值。这个是关联在本节点的版本值。
cluster_stats_messages_sent:通过 node-to-node 二进制总线发送的消息数量。
cluster_stats_messages_received:通过 node-to-node 二进制总线接收的消息数量。
先尝试使用 ip + port 的方式初始化集群,但是在 K8s 中启动服务 ip 都会变化,所以最终的结果还是要用 DNS 方式进行集群初始化。 执行本步后再想修改为 DNS 地址初始化需要从来一遍,如果不想麻烦的同学可以直接跳过。
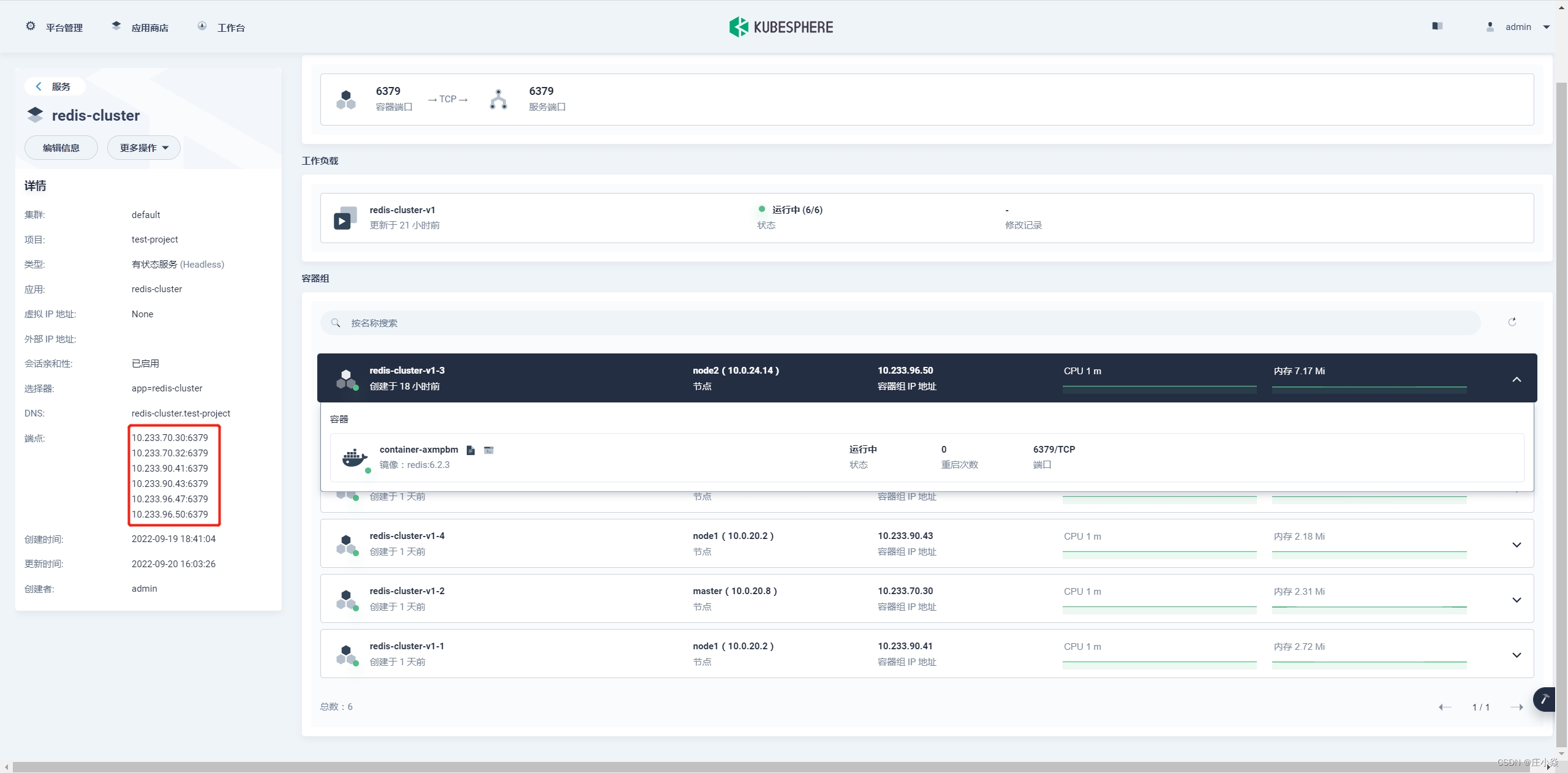
记录 redis 集群的所有 ip+port,初始化命令如下:
redis-cli --cluster create 10.233.70.30:6379 10.233.70.32:6379 10.233.90.41:6379 10.233.90.43:6379 10.233.96.47:6379 10.233.96.50:6379 --cluster-replicas 1
进入 redis 集群随意一个节点的终端执行上面的命令。
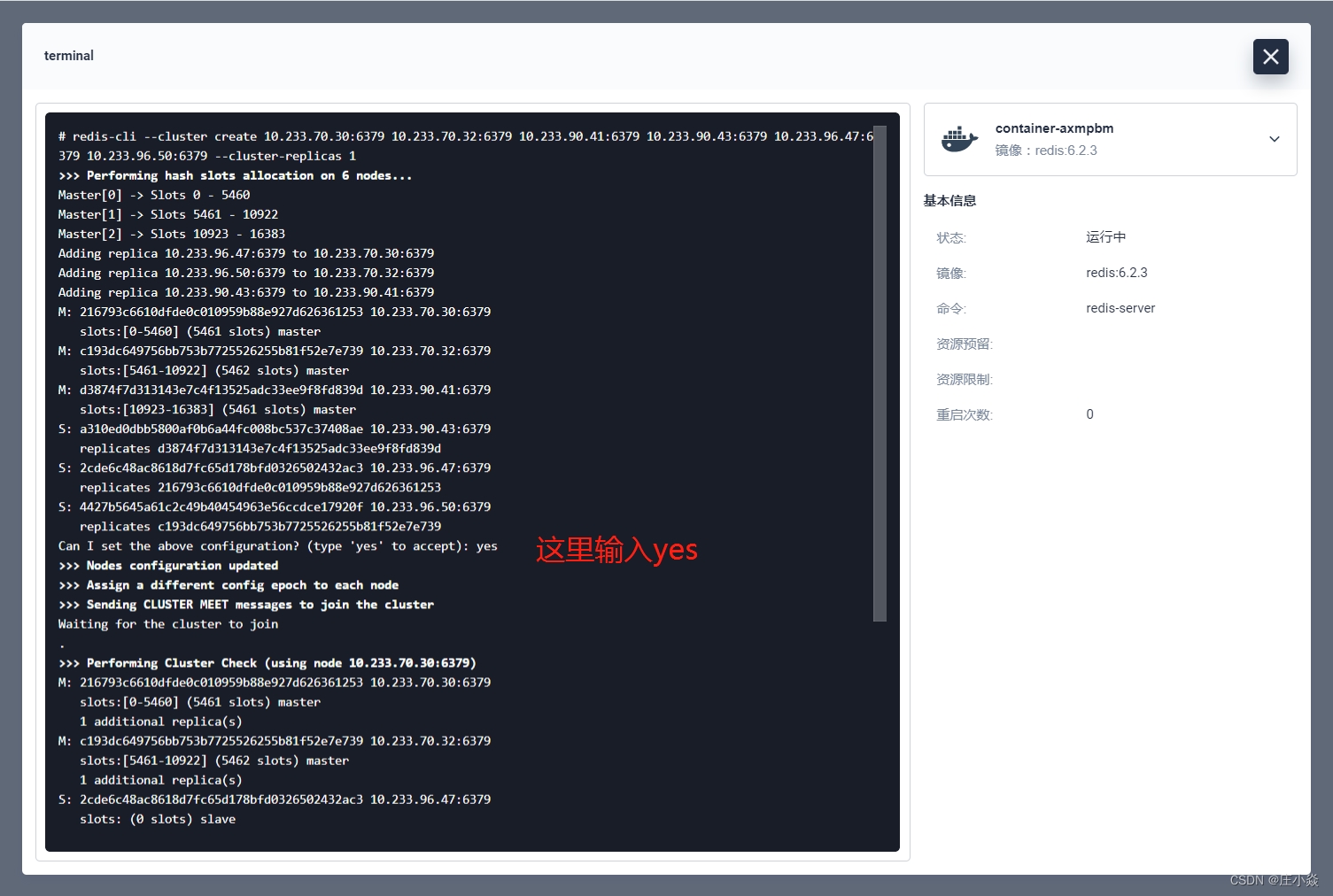
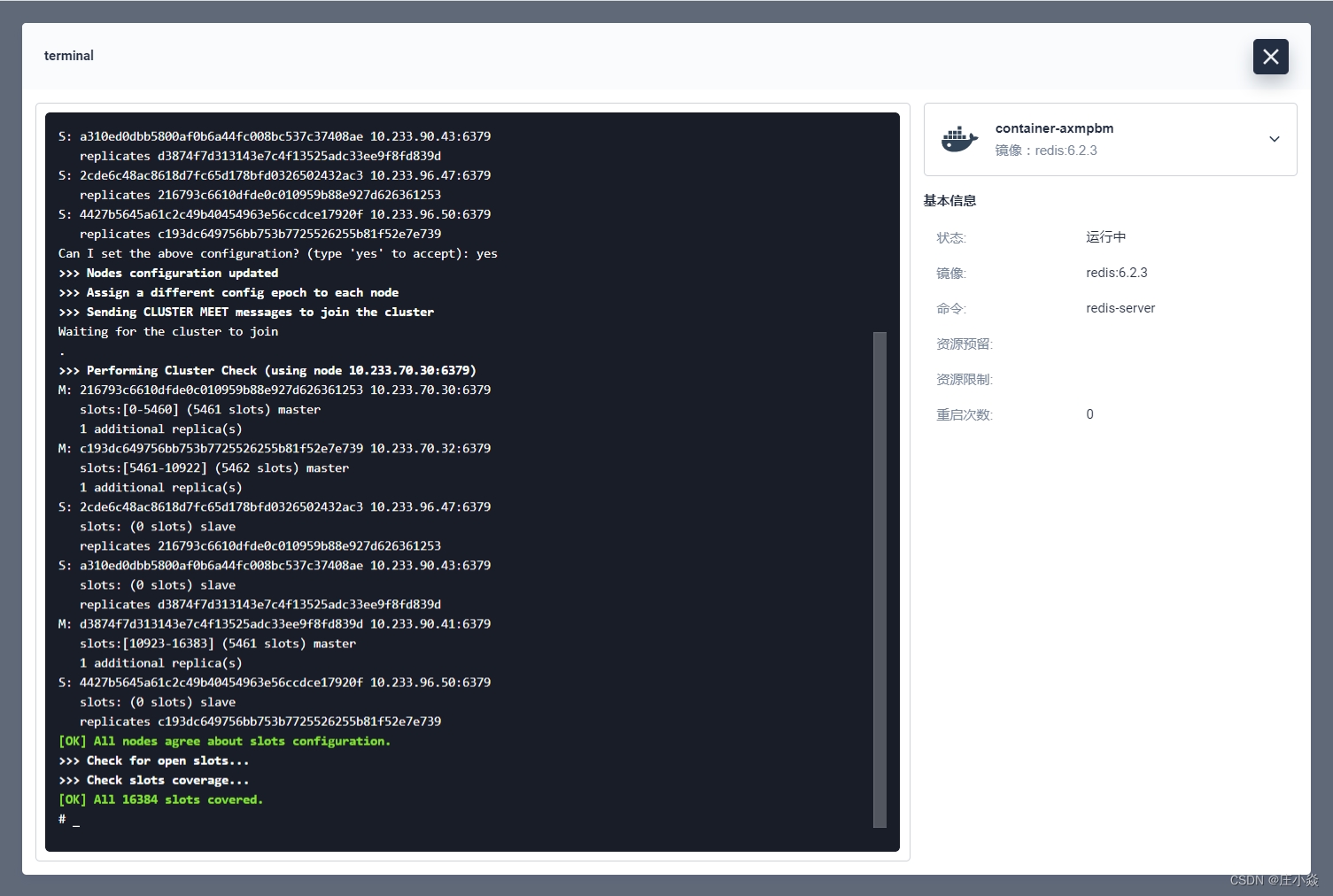
如上图集群初始化就完成了,再输入命令 redis-cli 进入命令端,再执行 cluster info 查看集群信息。
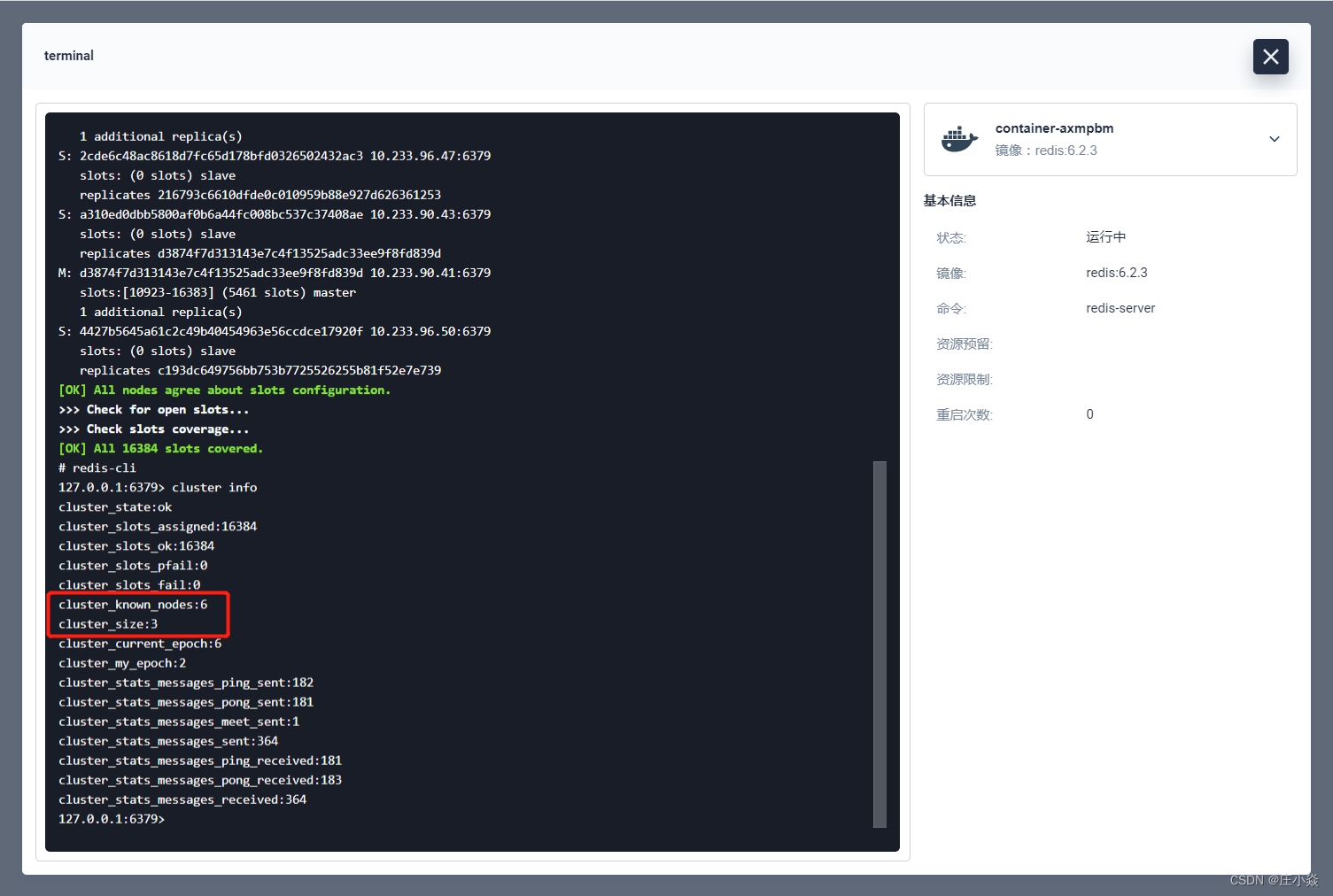
现在我们的集群节点有了 6 个,master 节点也有了三个,集群建立完成,后面的操作选择 master 节点进行操作。
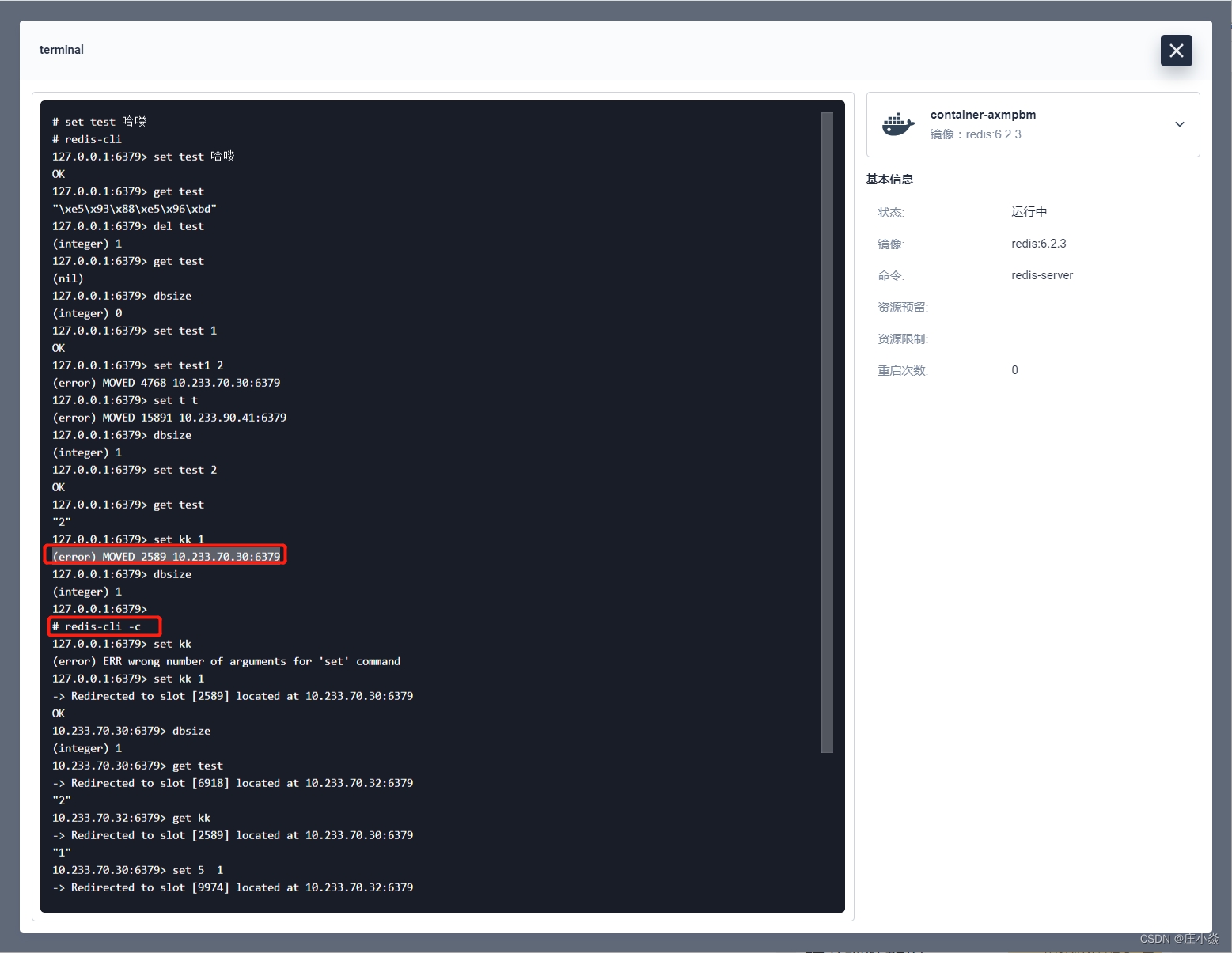
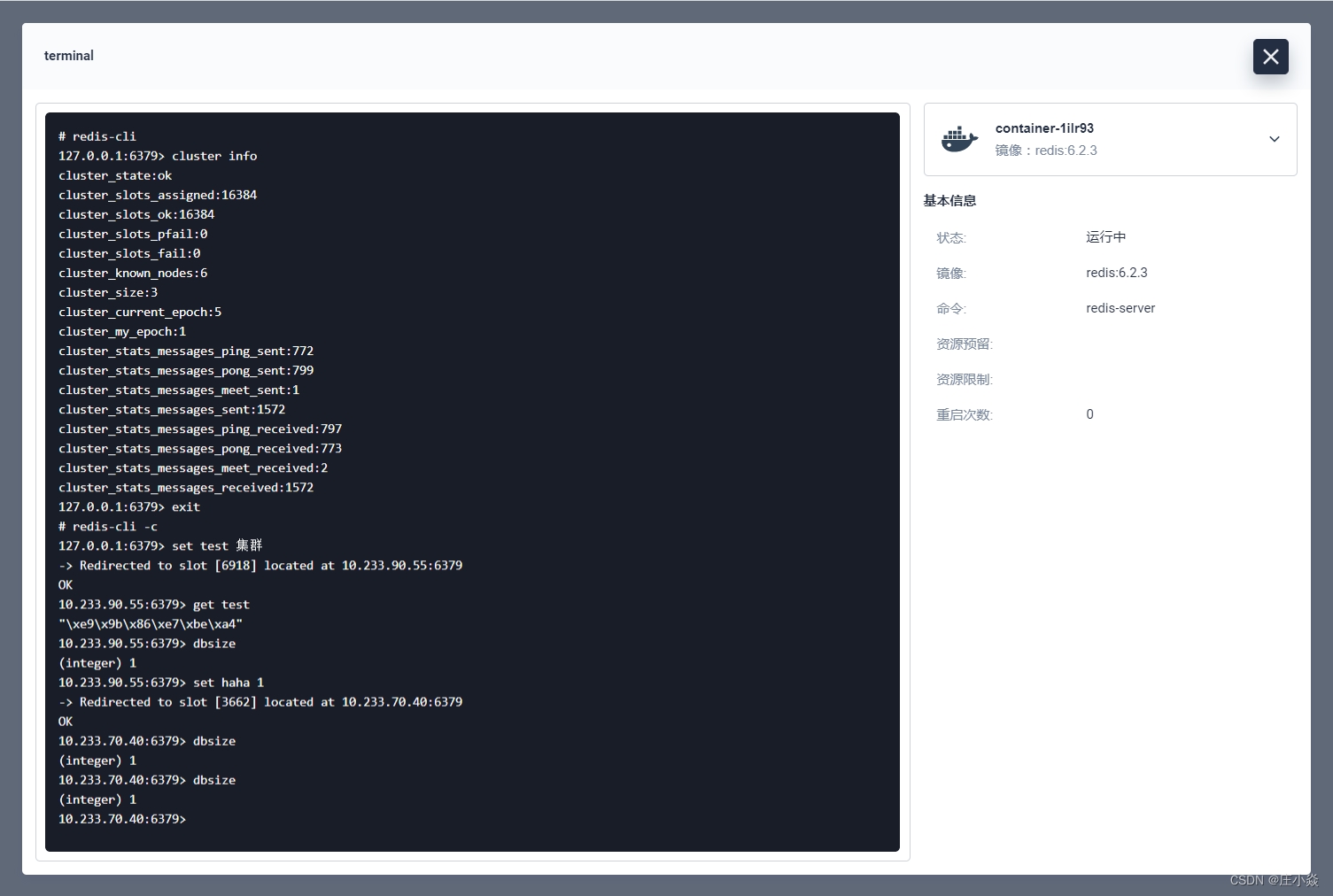
在对集群节点进行验证的时候如果遇到上图的错误 (error) MOVED 2589 10.233.70.30:6379 是因为 redis-cli 没有开启集群模式,将命令修改为 redis-cli -c 就切换为集群模式了。
5.2 使用内部 DNS 初始化
使用 ip 地址的方式在每次 K8s 调度 redis 后 ip 都会发生变化,所以在 K8s 集群中使用 ip 方式初始化集群并不太合适, 但是如果使用内部 DNS 直接跟上面一样初始化集群会出现错误,因为 redis 对域名的支持并不太好,所以这时候可以用 Redis-tribe。
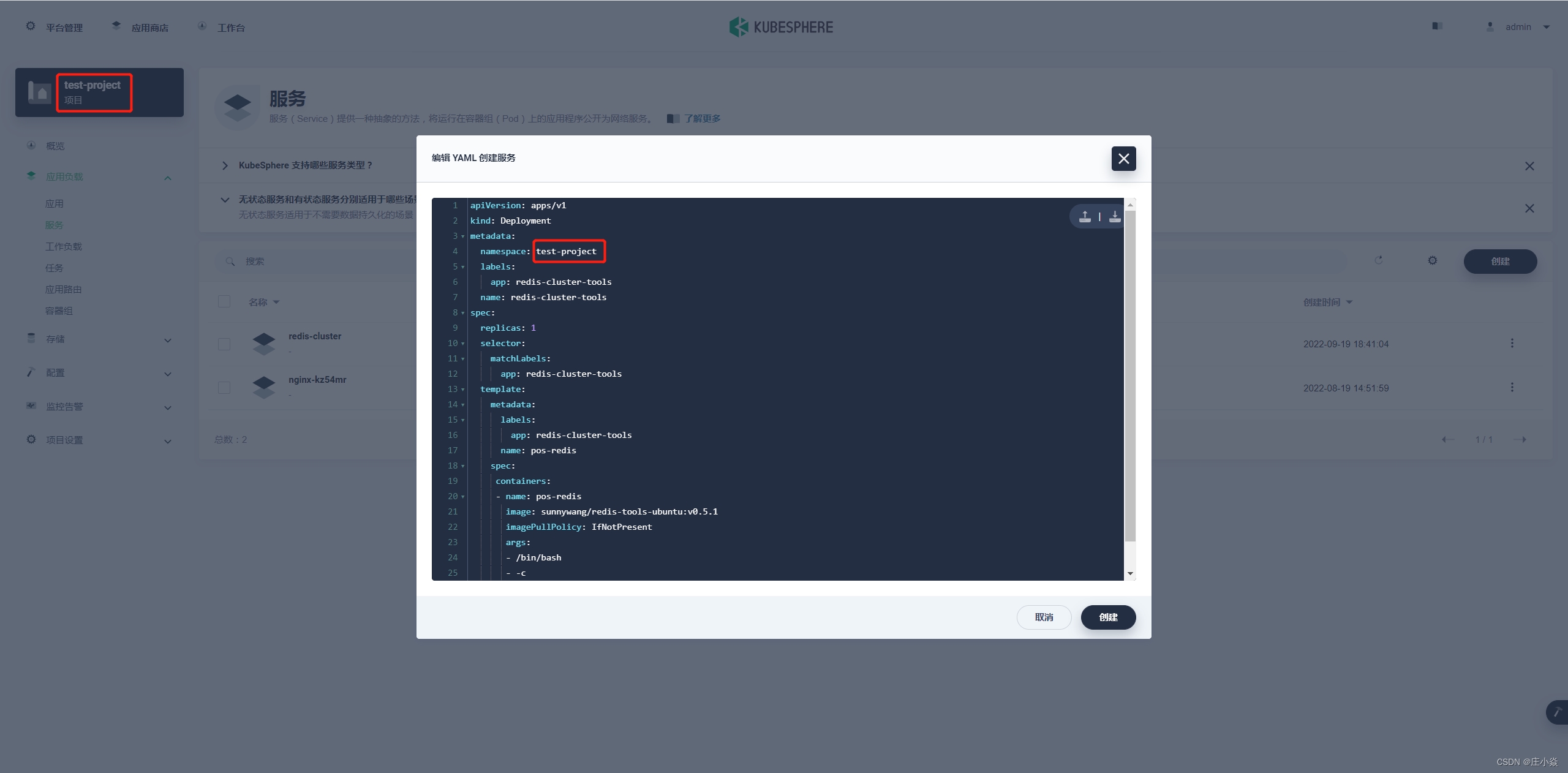
apiVersion: apps/v1 kind: Deployment metadata: namespace: test-project labels: app: redis-cluster-tools name: redis-cluster-tools spec: replicas: 1 selector: matchLabels: app: redis-cluster-tools template: metadata: labels: app: redis-cluster-tools name: pos-redis spec: containers: - name: pos-redis image: sunnywang/redis-tools-ubuntu:v0.5.1 imagePullPolicy: IfNotPresent args: - /bin/bash - -c - sleep 3600
创建好后在容器组内找到 redis-cluster-tools。
点击容器名称进入容器详情再进入到终端里。先执行以下命令初始化 master 节点,这时候之前的内部DNS的域名就有用了。
redis-trib.py create `dig +short redis-cluster-v1-0.redis-cluster.test-project.svc.cluster.local`:6379 `dig +short redis-cluster-v1-1.redis-cluster.test-project.svc.cluster.local`:6379 `dig +short redis-cluster-v1-2.redis-cluster.test-project.svc.cluster.local`:6379
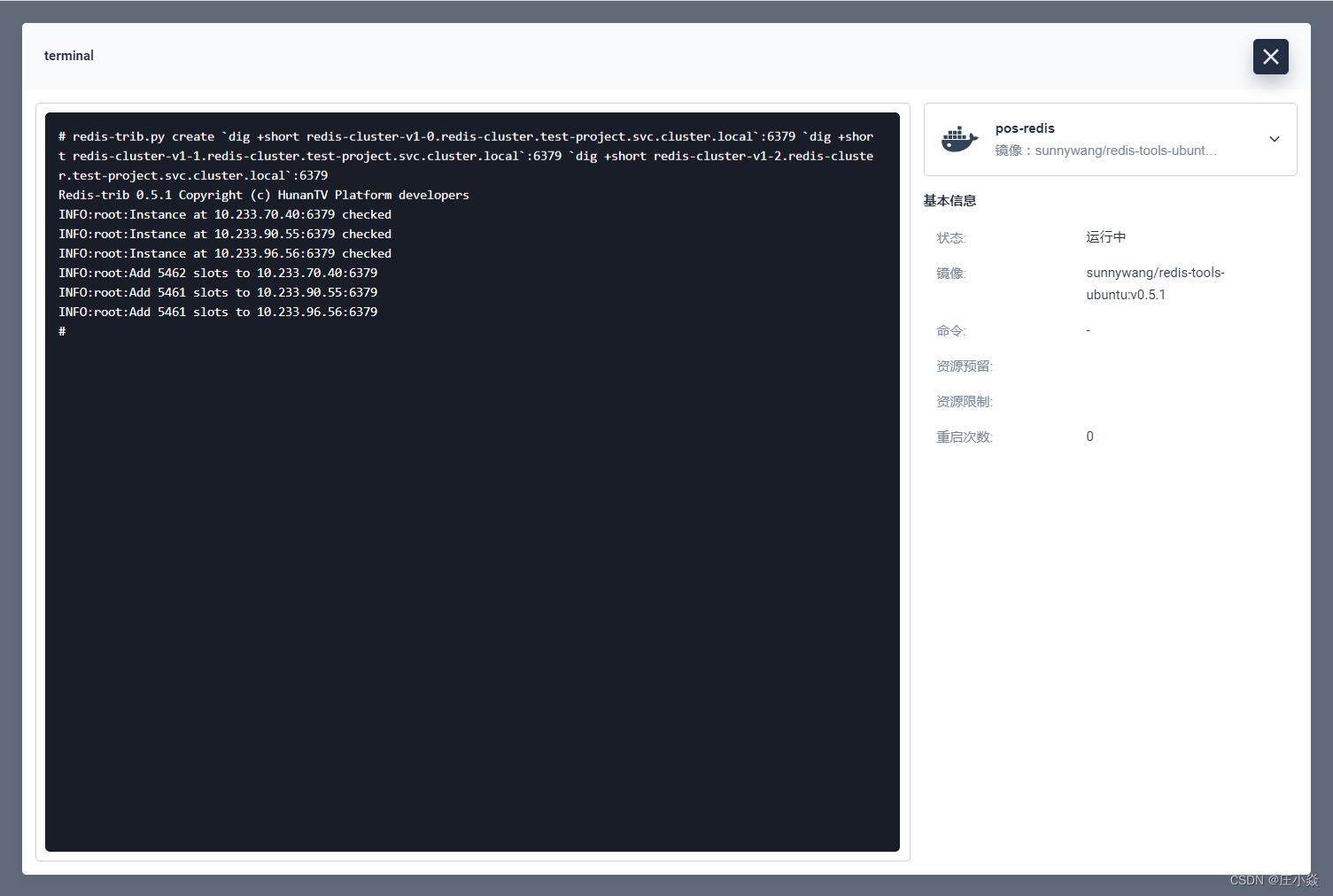
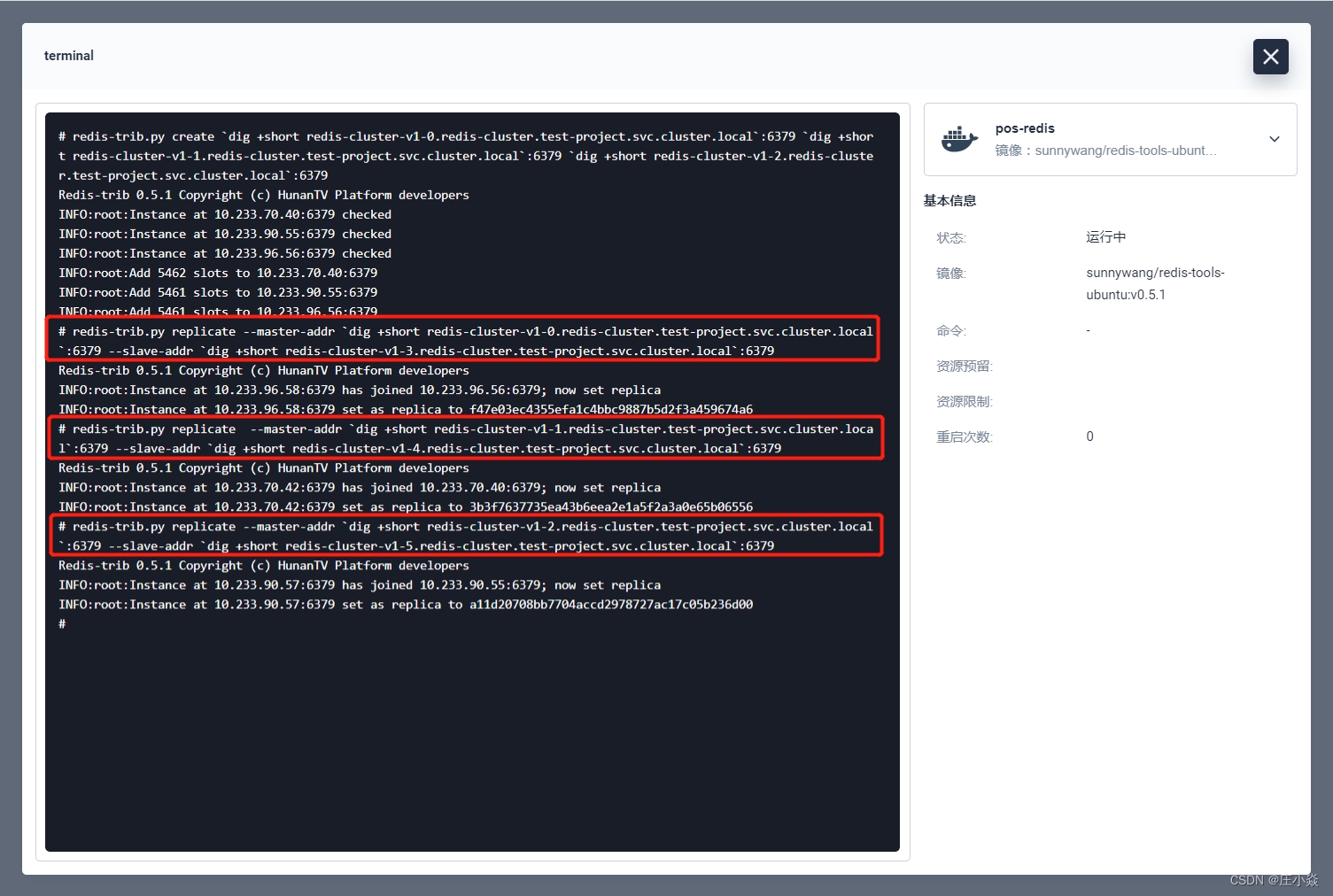
接下来给每个master节点绑定对应的副本节点,总共三个:
0 节点->3 节点: redis-trib.py replicate --master-addr `dig +short redis-cluster-v1-0.redis-cluster.test-project.svc.cluster.local`:6379 --slave-addr `dig +short redis-cluster-v1-3.redis-cluster.test-project.svc.cluster.local`:6379
1 节点->4 节点: redis-trib.py replicate --master-addr `dig +short redis-cluster-v1-1.redis-cluster.test-project.svc.cluster.local`:6379 --slave-addr `dig +short redis-cluster-v1-4.redis-cluster.test-project.svc.cluster.local`:6379
2 节点->5 节点: redis-trib.py replicate --master-addr `dig +short redis-cluster-v1-2.redis-cluster.test-project.svc.cluster.local`:6379 --slave-addr `dig +short redis-cluster-v1-5.redis-cluster.test-project.svc.cluster.local`:6379
随便进入一个集群节点的终端,还是执行 cluster info 命令,查看集群信息。
使用基础命令进行验证,验证集群模式的 redis-cli 需要加-c
六、集群压测
为了满足redis的集群需要,需要我们对构建的集群完成相关压测,同时调整相关资源,保证redis能够满足生产需要。
Redis 自带了一个叫 redis-benchmark 的工具来模拟 N 个客户端同时发出 M 个请求。(类似于 Apache ab 程序)。 你可以使用 redis-benchmark -h 来查看基准参数。redis 性能测试工具可选参数如下所示:
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | --csv | 以 CSV 格式输出 | |
| 12 | -l (L 的小写字母) | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表 | |
| 14 | -I (i 的大写字母) | Idle 模式。仅打开 N 个 idle 连接并等待。 |
压测示例;压测需要一段时间,因为它需要依次压测多个命令的结果,如:get、set、incr、lpush等等, 所以我们需要耐心等待,如果只需要压测某个命令,如:set,那么可以在以上的命令后加一个参数-t:
redis-benchmark -h 127.0.0.1 -p 6379 -n 100000 -c 50 -t set
# redis-benchmark -h 10.233.111.125 -p 6379 -n 100000 -c 50 -t set ====== SET ====== 100000 requests completed in 6.05 seconds 50 parallel clients 3 bytes payload keep alive: 1 93.28% <= 1 milliseconds 97.62% <= 2 milliseconds 98.18% <= 3 milliseconds 98.26% <= 4 milliseconds 98.27% <= 24 milliseconds 98.30% <= 72 milliseconds 98.32% <= 77 milliseconds 98.42% <= 78 milliseconds 98.68% <= 79 milliseconds 98.91% <= 80 milliseconds 99.42% <= 81 milliseconds 99.80% <= 82 milliseconds 99.91% <= 83 milliseconds 99.94% <= 84 milliseconds 99.96% <= 85 milliseconds 100.00% <= 86 milliseconds 100.00% <= 86 milliseconds 16528.93 requests per second
使用 pipelining
默认情况下,每个客户端都是在一个请求完成之后才发送下一个请求 (benchmark 会模拟 50 个客户端除非使用 -c 指定特别的数量), 这意味着服务器几乎是按顺序读取每个客户端的命令。Also RTT is payed as well. 真实世界会更复杂,Redis 支持 /topics/pipelining,使得可以一次性执行多条命令成为可能。 Redis pipelining 可以提高服务器的 TPS。
# redis-benchmark -h 10.233.111.125 -p 6379 -n 100000 -c 50 -t set,get -P 16 -q SET: 195694.72 requests per second GET: 83472.46 requests per second


上篇:
KubeSphere部署worldpress应用
下篇:
KubeSphere租户管理与常见应用部署实战
1 AI智能体后端落地:场景+原理+实战,告别Demo式应用 2 扣子(Coze)工作流实战:篇篇10W+的小林漫画,用Coze实现了爆款流水线生... 3 Qwen3-Coder 实战!历史人物短视频一键生成,多分镜人物不崩 4 大模型无非就这点东西 5 一天做出短剧App:我的MCP极速流 6 我用ai员工自动运营Google,登顶并收8k美金 7 网络故障秒排指南:10 个实战命令从入门到精通 8 使用MCP+Neo4j零代码构建自己的知识图谱 9 K8S常用命令手册 10 AI绘画指令编写实战指南(绘画师专用版) 11 从 0 到 1:使用 Loki + Promtail + Grafana 搭建日... 12 ImagePrompt:一款 AI 图片提示词工具,使用图片