今天教大家如何搭建一套数据分析平台。
它可能是最简单的搭建教程,有一点Python基础都能完成。比起动辄研发数月的成熟系统,借助开源工具,整个时间能压缩在一小时内完成。
优秀的数据分析平台,首先要满足数据查询、统计、多维分析、数据报表等功能。可惜很多分析师,工作的第一年,都是埋葬在SQL语句中,以SQL+Excel的形式完成工作,却用不上高效率的工具。
说Excel也很好用的同学,请先回避一下。
另外一方面,以互联网为代表的公司越来越重视数据,数据获取不再是难点,难点是怎样敏捷分析获得洞察。
市面上已经有不少公司推出企业级的分析平台和BI,可惜它们都是收费的。我相信不少读者听说过,但一直没有机会体验,或者老板们囊中羞涩。现在,完完全全能免费建立一套BI系统,即可以单机版用以分析,也能私有化部署到服务器,成为自家公司的分析工具。
这一切,只需要一小时。
Superset
Superset是一款轻量级的BI工具,由Airbnb的数据部门开源。整个项目基于Python框架,不是Python我也不会推荐了,它集成了Flask、D3、Pandas、SqlAlchemy等。
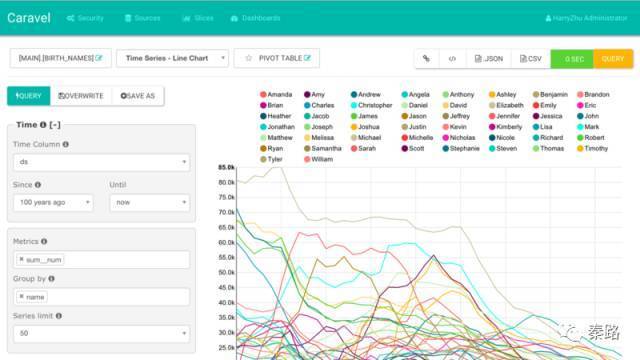
这是官网的案例(本来是动图的,可惜压缩后也超过微信图片大小限制,吐槽下),想必设计界面已经能秒杀一批市面上的产品了,很多BI真的是浓烈的中国式报表风......因为它的前端基于D3,所以绝大部分的可视化图表都支持,甚至更强大。
Superset本身集成了数据查询功能,查询对分析师那是常有的事。它支持各类主流数据库,包括MySQL、PostgresSQL、Oracle、Impala、SparkSQL等,深度支持Druid。
后台支持权限分配管理,针对数据源分配账户。所以它在部署服务器后,分析师们可以通过它查询数据,也能通过数据建立Dashboard报表。
介绍了这么多,想必大家已经想要安装了吧。
安装
Superset同时支持Python2和Python3, 我这里以Python3作为演示。它支持pip形式的下载,不过我不建议直接安装,因为Superset的依赖包较多,如果直接安装,很容易和现有的模块产生冲突。
这里需要先搭建Python的虚拟环境。虚拟环境可以帮助我们在单机上建立多个版本的Python。简而言之,即可以Python2和Python3共存,也能Python3.3、3.4、3.5共济一堂,彼此间互相独立。
虚拟环境的安装方式很多,pyenv和virtualenv等。这里用Anaconda自带的conda工具。打开电脑终端/cmd,输入以下命令。
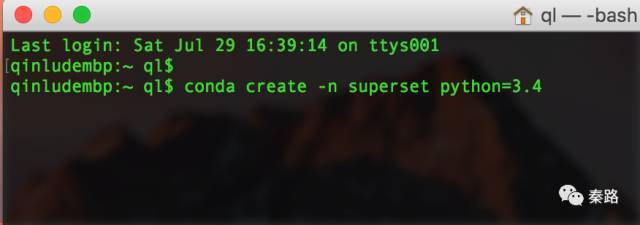
conda create -n superset python=3.4
conda create是创建虚拟环境的命令。-n是环境的命名参数,在这里,我们创建了名为superset的环境,它安装在Anaconda的envs目录下。python版本为3.4(superset暂时不支持3.6)。
该命令只会安装基础包,如果需要额外安装其他包,在命令行后加上想要的包名字即可,如python=3.4 numpy pandas。
安装很迅速,完成后,我们的Python环境还是默认版本,现在需要激活虚拟环境。
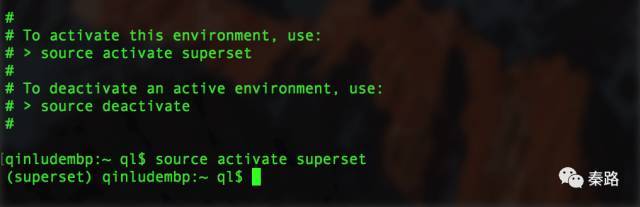
source activate superset
source activate是激活命令,superset为想要激活的虚拟环境名。windows和mac的命令不一样,win只要activate superset 。如果要退出,则是source deactivate或者deactivate。
激活成功后,命令行前面会多出一个前缀(superset),表明切换到了新的虚拟环境。接下来安装superset。
pip install superset
pip会自动安装所有的依赖,速度可能有点慢,建议更改pip源。

命令行后加上 -i https://pypi.douban.com/simple ,我这里用了豆瓣的镜像源,速度嗖嗖的。
如果安装过程中报错,是部分程序缺失,像系统比较老旧的win用户,需要安装新版的visual c++,网上搜索教程即可。在官网的教程中,还要求pip install cryptography==1.7.2,我没有安装也没有影响,供大家参考。其他报错,都可以通过搜索解决。
安装成功后,需要进行初始化配置,也是在命令行输入。
fabmanager create-admin --app superset
首先用命令行创建一个admin管理员账户,也是后续的登陆账号。会依次提示输入账户名,账户使用者的first name、last name、邮箱、以及确认密码。fabmanager是flask的权限管理命令,如果大家忘了密码,也能重新设立。
superset db upgrade
初始化数据源。
superset load_examples
载入案例数据,这里的案例数据是世界卫生组织的数据,也是上文演示的各类可视化图表,大家登陆后能够直接看到。下载速度还行。
superset init
初始化默认的用户角色和权限。
superset runserver
最后一步骤,启动Superset服务。因为我们是本地环境,所以在浏览器输入 http://localhost:8088 即可。在runserver后面添加 -p XXXX 可更改为其他端口。
进入登陆界面,输入登陆密码,大功告成。
使用
先别急着使用,因为Superset是英文,我们先把它汉化了。Superset自身支持语言切换。
进入到Superset所在目录文件,按我之前的步骤,应该在anaconda/envs/superset/lib/python3.4/site-packages/superset中,路径视各位情况可能有差异。
在目录下有一个叫config.py的文件,打开它,找到Setup default language这一行,修改变量。
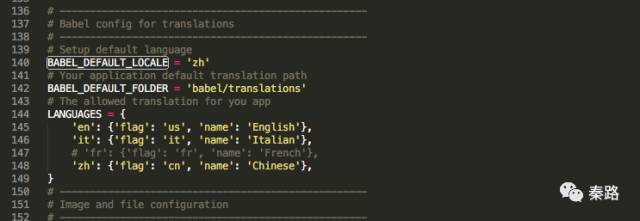
BABEL_DEFAULT_LOCALE调整为zh,这样界面默认为中文。languages字典中zh前面的注释#去掉。保存后退出。
接下来还是在Superset的目录下新创建文件夹,按translations/zh/LC_MESSAGES的路径依次创建三个。Superset官网提供了汉化包,在最大的同性交友网站github上下载,目录为:
https://github.com/apache/incubator-superset/blob/master/superset/translations/zh/LC_MESSAGES/messages.mo
网址路径有点长,下载后把mo文件放在LC_MESSAGES文件下。清除浏览器的缓存,重新登陆localhost。
搞定!
需要注意的是,它并非完全汉化,而是汉化了superset相关的部分。部分文字被写入在flask app的文件中,汉化起来比较麻烦。
Superset分为多个模块,安全模块是账号管理相关,包括角色列表,视图权限控制,操作日志等。管理模块没什么用,主要是设计元素。
数据源可以访问和连接数据库,切片是各类数据可视化,均是单图;看板即为Dashboard,是切片的集合,Superset提供了三个初始案例,SQL工具箱是数据查询平台。
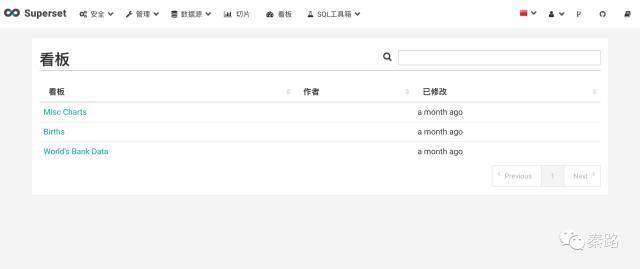
麻雀虽小,五脏俱全,对于大部分中小型的企业,Superset足以应付数据分析工作。
先学习连接数据库,这里以我电脑中的数据库为准,如果大家学习过早前的教程,那么数据库中都应该有数据分析师的练习数据,我这里不重复了,可以看历史文章。也可用自带的卫生数据照着练习。
Superset使用了sqlalchemy框架,使用前需要安装数据库驱动程序,先退出runserver,进入superset虚拟环境,安装Python中的MySQL驱动程序。
pip install pymysql
MySQL的驱动程序很多,除了pymysql,还有mysqlclient等。安装好后,进入数据源,新建一个database连接。
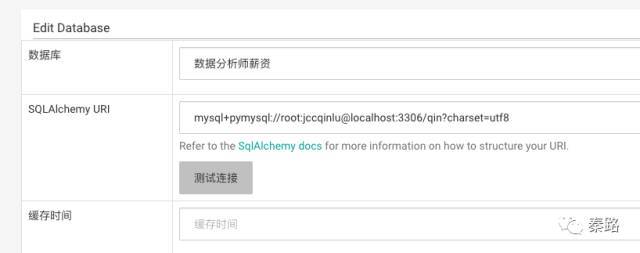
在SQLAlchemy URL中加入数据库的地址,格式为:
mysql+pymysql://root:xxxx@localhost:3306/qin?charset=utf8
mysql是数据库类型,pymysql是驱动程序,表示用pymysql连接mysql数据库,+号不能省略。
另外,root是数据库登陆账号,xxxx为密码,这个按大家自己设立的来。localhost是数据库地址,因为我的是本地环境,所以localhost即可,也可以是127.0.0.1。3306是端口,一般默认这个。qin是需要连接的数据库,也是我自己设的名字。后面带参数charset=utf8,表示编码,因为表里面有中文。
其他数据库的连接大同小异,图中绿色的连接是相关教程。
如果大家在公司网络,拥有内网访问数据库的权限,也可以尝试连接,应该是可以的,这样就能在个人电脑上实行敏捷的BI分析。
格式命名好后,点击测试,出现seems ok,表示成功访问。在选项下面还有个Expose in SQL Lab,允许我们在SQL工具箱查询,要打上勾。
进入到SQL工具箱,左边选择table为DataAnalyst。
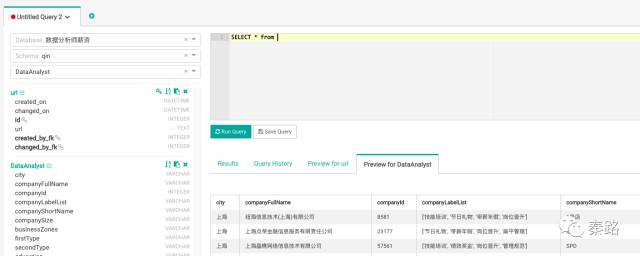
直接出来了数据库的数据预览。连查询平台的颜值都那么高。大家的SQL技能应该都很不错,有兴趣可以在这里练习一下,语法和MySQL一致。其他数据库则是其他数据库的语法。
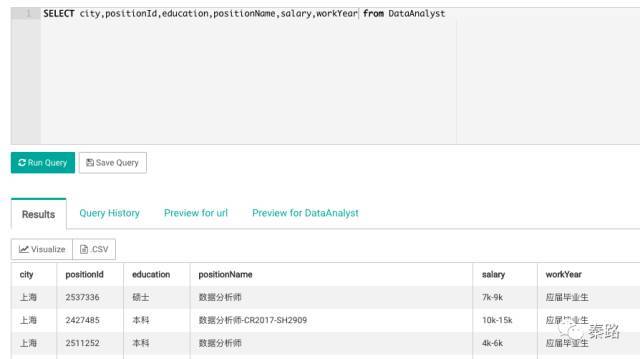
执行一段SQL语句,它支持下载为CSV,我没试过支持最大文件的大小,但作为日常的查询平台是绰绰有余了。
选择Visualize,进入切片绘图模式。
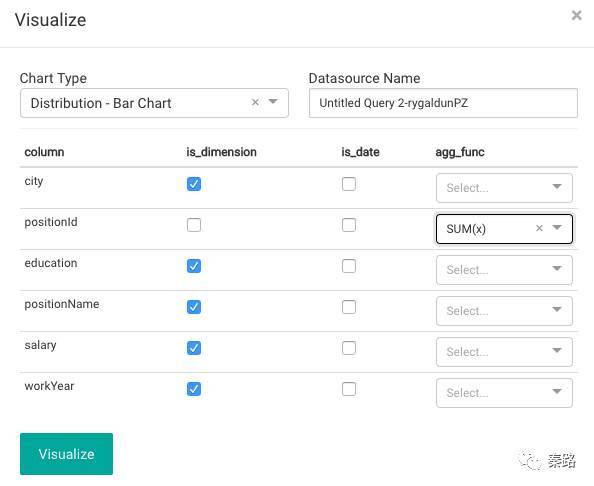
这里自动匹配支持的图表选项,包括Bar Chart条形图,Pir Chart饼图等。下面的选项是定义维度,我们将city,education,postitionName,salary,workYear都勾选为维度。agg_func是聚合功能,这里将职位ID求和,改成count(),点击生成图表。
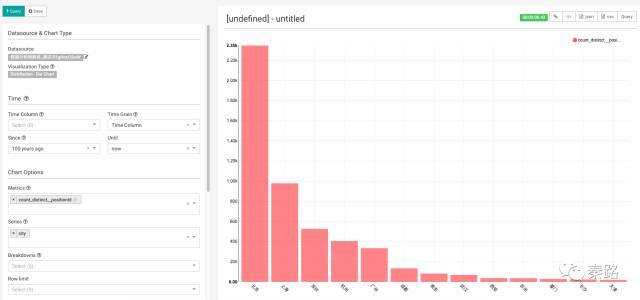
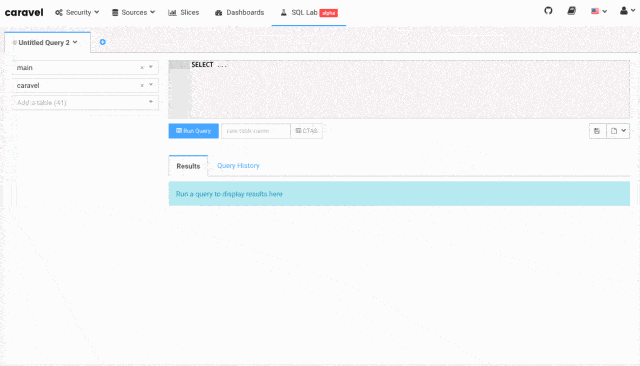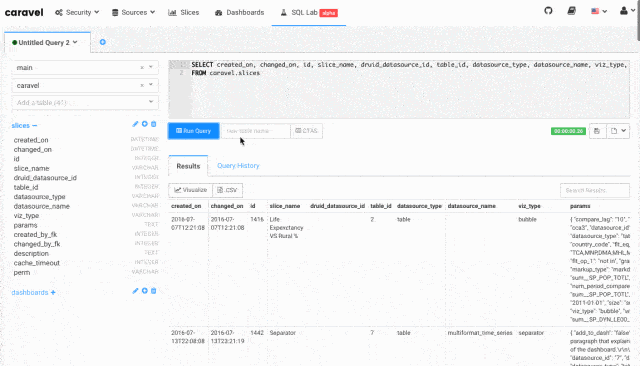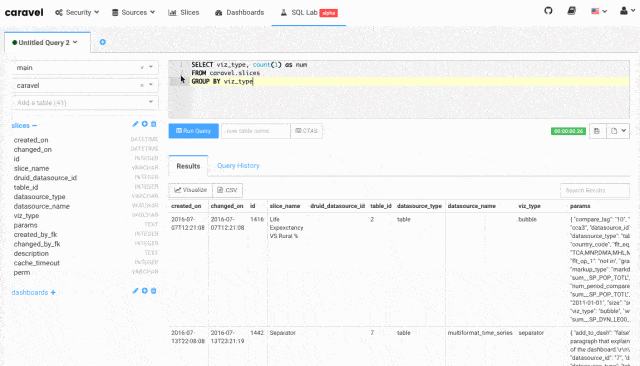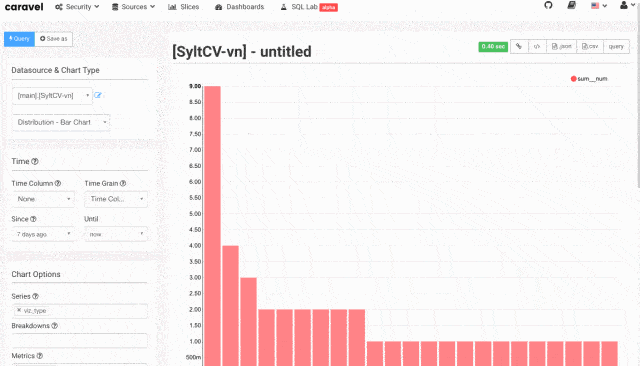
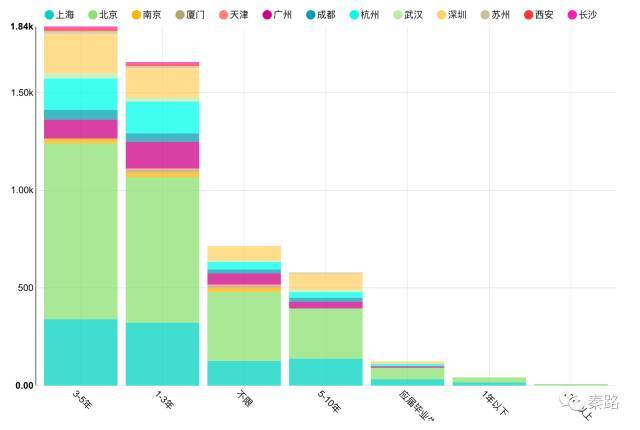
这里按城市生成了各职位ID求和获得的条形图,也就是不同城市的分析师人数。
左边Chart Options可以调整分析需要的维度。Metrics是分析的度量,这里是count(positionId),Series是条形图中的类别,Breakdowns可以认为是分组或者分桶。这里将Series改成workYear,Breakdowns改成city,点击Query执行。
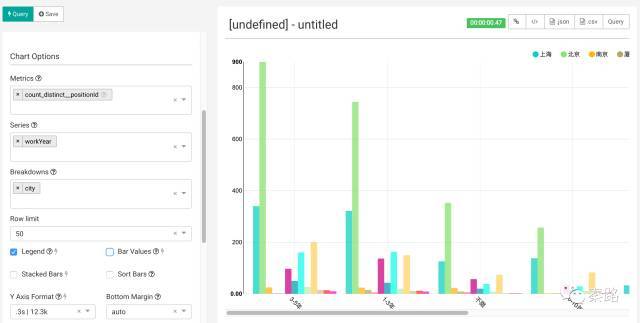
条形图变更为按工作年限和城市细分的多维条形图。点击Stacked Bars,则切换成堆积柱形图。操作不难。
左侧的选项栏还有其他功能,这里就不多做介绍了,和市面上常见的BI没有多大区别,琢磨一下也就会了。
Superset支持的图表很丰富,如果具备开发能力,也能以D3和Flask为基础做二次开发。Airbnb官方也会不断加入新的图表。不同图表,其左侧的操作选项也不同。
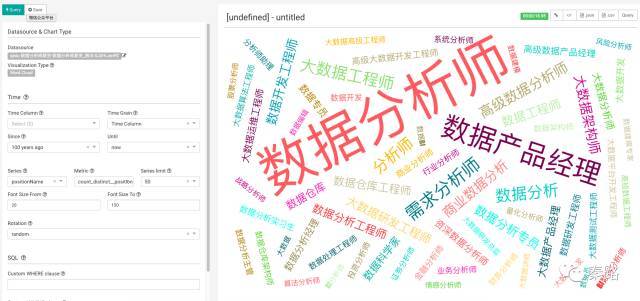
上图是以数据分析师职位名称为基础绘制的词云图,生成的速度会比较慢。我们选择save保存。完成的图表均存放在切片下。
Dashboard通过多个切片组合完成,每个切片连接不同的数据源,这是BI的基本逻辑。进入看板界面,新建一个Dashboard。
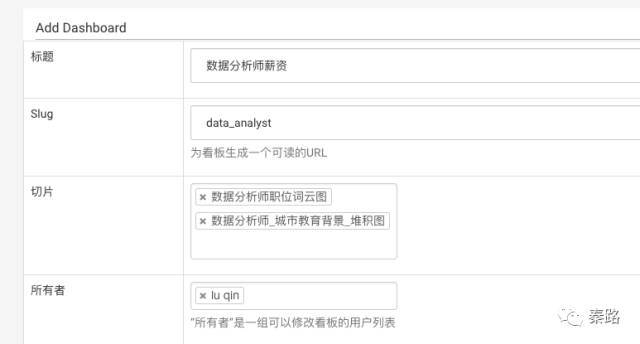
设置看板相应的配置选项,因为我偷懒了,所以只做了两个切片,大家有兴趣可以继续增加。其他选项忽略,都是自动生成的。点击save,到这一步,BI最重要的Dashboard就完成了。
浏览一下最终的成果吧。
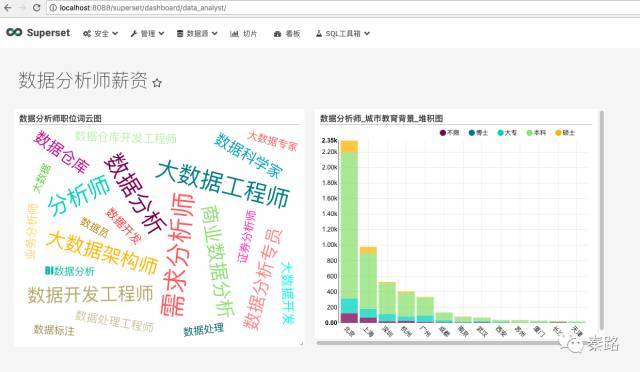
关于Superset的新手教学结束了,要是部署到公司,账号和权限多研究下。它和市面上的其他BI没有太多区别,不过它是我们用Python从零到有一手建立,这个感觉可比用Excel爽不少。虽然我的演示以单机版为主,将其建立在linux服务器上大同小异。
从零开始搭建到现在,排除掉下载花费的时间,大家可以计算是不是真的只用一个小时就搭建好一个数据分析平台?没骗你们吧。
通过搭建Superset,数据分析新手对BI应该也有一个大概的了解,市面上的BI大同小异,只是侧重点不同。在Superset的基础上,往底层完成埋点采集和数据ETL,往上拓展报表监控,CRM等,这些也有不少开源软件可用。至于机器学习,以及Hadoop和Spark更是一个大生态,把这些都算上,则是真正完整的大数据分析平台了。
Superset也有缺陷,它使用的是ORM框架,虽然它能连接众多的数据库,但是它有一个关系映射过程,将SQL数据转化为Python中的对象,这也造成它在大数据量的处理效率不如专业的BI软件。在使用SQL工具箱时,应该尽量避免超大表之间的关联,以及复杂的group by。
我个人的建议是,它只是一款轻量级的BI,复杂的数据关联,应该在ETL过程中完成,Superset只需要执行最终结果表的读取即可。它足够支撑TB级别的数据源读取。技术比较成熟的团队,也能尝试将Superset和Kylin整合,这样OLAP的能力又能上一个台阶。
另外,Superset中的表都是独立的,所以多图表间的复杂联动并不支持,仅支持过滤,这点比较可惜。不知道Airbnb后续会不会支持。
好消息是,这个开源项目一直在更新,github什么也有很多新的功能特性待开发,比如dashboard上加入tab切换栏等。可以star一下关注。


上篇:
新手入门大数据,大数据的入门!!!认识大数据
下篇:
Hadoop、Hive、Zookeeper、Pig、HBase和Mahout等,都要认真学习
1 Electron、React Native 都不用了?Rust 全栈框架 Dio... 2 详情页生成器在线制作,一键自动生成商品详情,电商人告别熬夜做 3 用codex做电商图,顺手做了一条电商工作流 4 Remotion 最强竞品!用 HTML 写视频,AI 自动成片 5 SEO Machine:开源 AI 全自动写 SEO 爆文,关键词、竞品分析一键... 6 OpenClaw做跨境电商必装的Skills清单! 7 十大互联网赚钱项目 8 电商必懂的数据公式 9 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 10 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 11 跨境电商的疑难杂症,被1688这个AI全包了 12 用AI自动生成爆款文案的完整流程