简介: 介绍如何基于Hologres和MaxCompute产品组合,支撑高并发、快响应的数据服务化场景,替换HBase开发模式,实现数据资产服务化在线化能力。
Hologres是一款兼容PostgreSQL 11协议的一站式实时数仓,与大数据生态无缝打通,支持PB级数据高并发、低延时的分析处理,可以轻松而经济地使用现有BI工具对数据进行多维分析透视和业务探索。

一、传统数据库痛点
传统的数据仓库开发方式,比如在一些用户行为的分析,点击流的分析场景,一般来说是通过一些报表的形式去展现。这类分析背后往往需要很复杂的计算,需要计算引擎具备很强大的计算能力。另外一个场景,也是一个很强的数据驱动的场景,常见的像推荐系统的场景。推荐背后完全依赖对数据或者说对人的行为的理解,基于历史行为的统计信息,我们来智能化的推荐什么事情是他当下最感兴趣的。这类场景并不是传统的分析场景,但它也是一个数据决策的场景,今天我们把它们放在一起,看一看我们的数据仓库是如何支持不同的数据决策场景。
从行为分析到实时推荐,这两者之间有一些关系。传统的报表分析是一种查询相对比较复杂,查的也比较快,要交互式体验。但是对于实时推荐的场景,查询往往更简单,往往就是一张单表的查询,但是对性能会非常的敏感,一般来说需要毫秒级响应。这两件事过去往往是由不同的系统来做的。

传统上,我们是如何做数据加工以及数据服务的呢?最常见的方式就是下图所示,数据链路也左向右发展,有加工平台负责加工,结果数据导出到服务平台对外提供服务。这个架构在最开始应用的时候还是比较顺利的,大部分公司里面90%的场景下是这个架构。但是随着业务越来越多,越来越复杂,每天都有新的报表,每天都有新的业务场景,就会发现每一个业务调整的时候,都要从源头一步步调整,包括表结构,加工脚本,历史数据重刷等等,最后造成整个数据加工的链路会变得数据冗余、成本高、开发周期长、甚至数据不一致。于是我们就需要开始思考这个架构还能不能再有优化的空间,甚至是再简化一些。
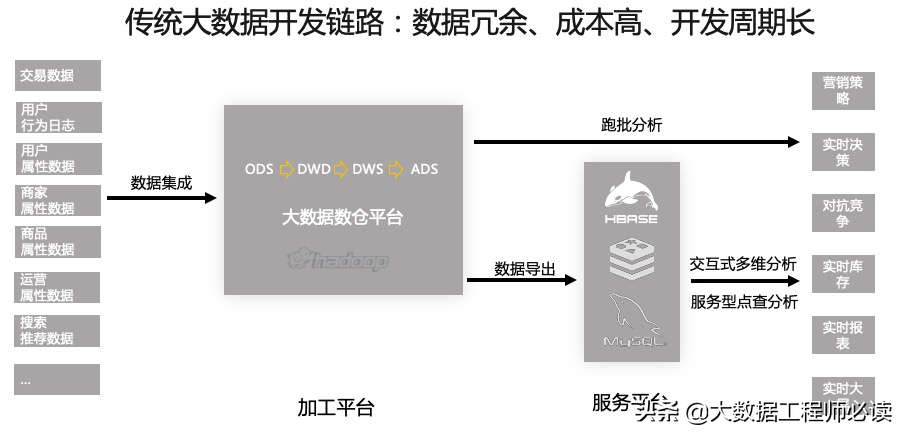
要解决上述问题,可以看到市面上的选项大致分为3个系统,以及它们之间的综合。第一个是直接用事务系统做分析,Transaction类型,支持随机读写、事务、可靠,主要面向DBA。第二个系统是专业的分析系统,Analytics,适合大规模数据扫描、过滤、汇总,面向分析师。第三个系统是在线服务的系统,Serving,支持高并发、简单、快速,面向API。三个系统各有擅长,最终落地解决问题的时候,往往多个系统一起使用,数据在系统间频繁交换,也引起了刚刚提到的各种冗余、复杂、不一致的问题。
我们首先想到的是,能否一个系统支持尽量多的场景,简化运维,少一些数据移动。
首先出现的是红线和蓝线交界部分,让一个系统既可以支持分析,又可以支持事务,也就是我们常说的HTAP,它有一定的适用场景:
数据来源于业务系统(TP)
需要机制保证TP和AP的一致性(数据、 模型,大量同步)
模型简单,用于简单分析场景。
局限是,事务系统的数据模型是无法直接用于分析场景的,数据需要被加工、抽象才能用于数据分析师。
在另一侧,蓝色和黄色交界的部分也有一个场景,分析和服务也可以做成一个系统,也有它的适用场景:
统一实时、离线存储引擎
没有事务需求,减少针对事务场景的开销(锁、同步)
埋点数据、机器数据,比TP高数量级
为多场景设计可复用数仓。
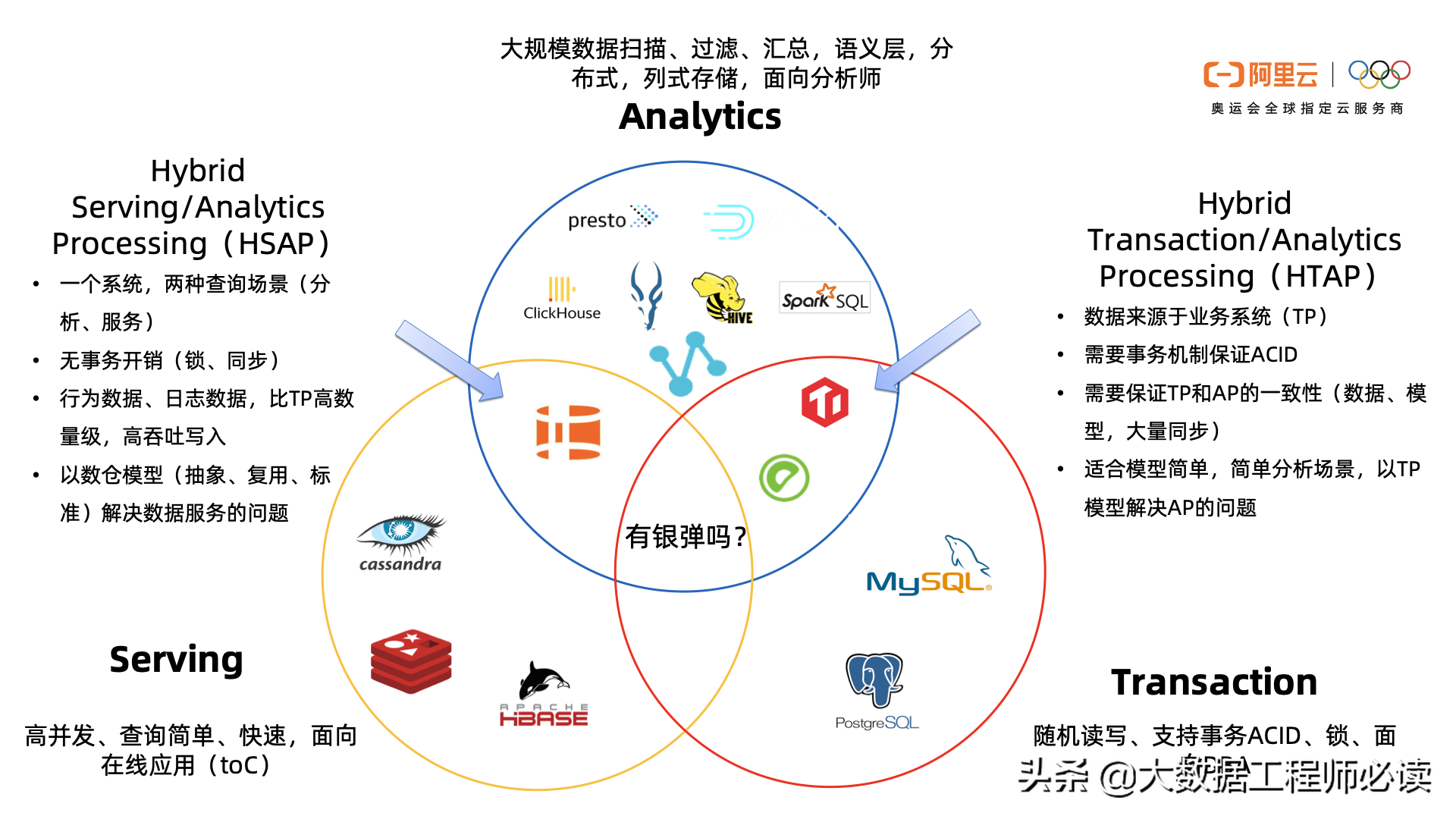
二、HSAP:服务分析一体化
我们提出HSAP(Hybrid Serving & Analytics Processing)的理念,目标做到服务分析一体化,背后的技术挑战是非常大的:首先,离线数据和实时数据都要支持。然后我们希望数据是统一的,不要把实时和离线割裂。也希望接口是统一的,提供一套统一的接口。我们可以看到SQL接口相对来说是现在市面上表达能力最强的一种查询语言,所以我们认为在HSAP这种理念下,如果重新做一个系统,它应该支持统一的查询接口,一般是SQL,统一的访问控制;然后统一的存储,实时、离线都可以存在这样一个系统里。

三、实时数仓:Hologres
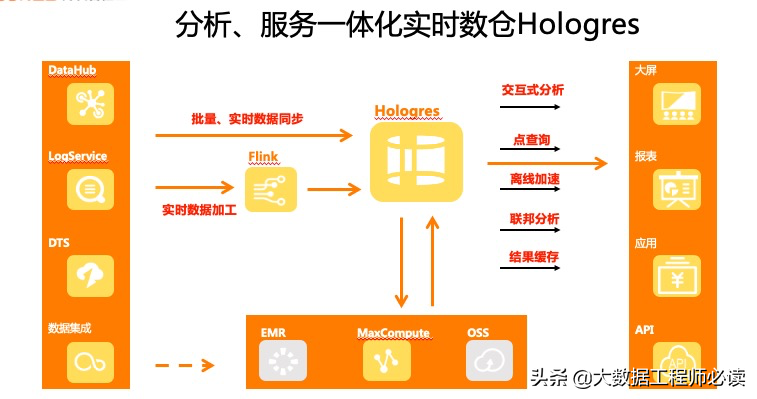
Hologres是针对HSAP场景设计的系统,它支持数据以离线和实时的方式,从业务系统、日志系统进入Hologres。进入过程中,一种是批量导入,这种方式的数据量是很大的。另一部分实时数据会通过Flink实时计算,通过计算前置的方式,把一些计算逻辑规则通过Flink提前算好,比如流数据关联,窗口加工,轻度汇总等,然后把计算结果存在Hologres的表里面,然后通过Hologres作为一个服务平台对接应用层,不管是一个多维分析的报表,还是一个实时推荐的应用,都可以支撑服务。
为了实现实时和离线的一体化,Hologres与MaxCompute做到了底层打通,Hologres隶属MaxCompute产品家族,这两个产品合在一起为用户提供实时、离线一体化的解决方案。数据在Hologres和MaxCompute之间以一种原生的方式互相打通,互相可以查询对方的数据,互相可以看到对方的表,互相可以有很简单的方式做一些数据的迁移。
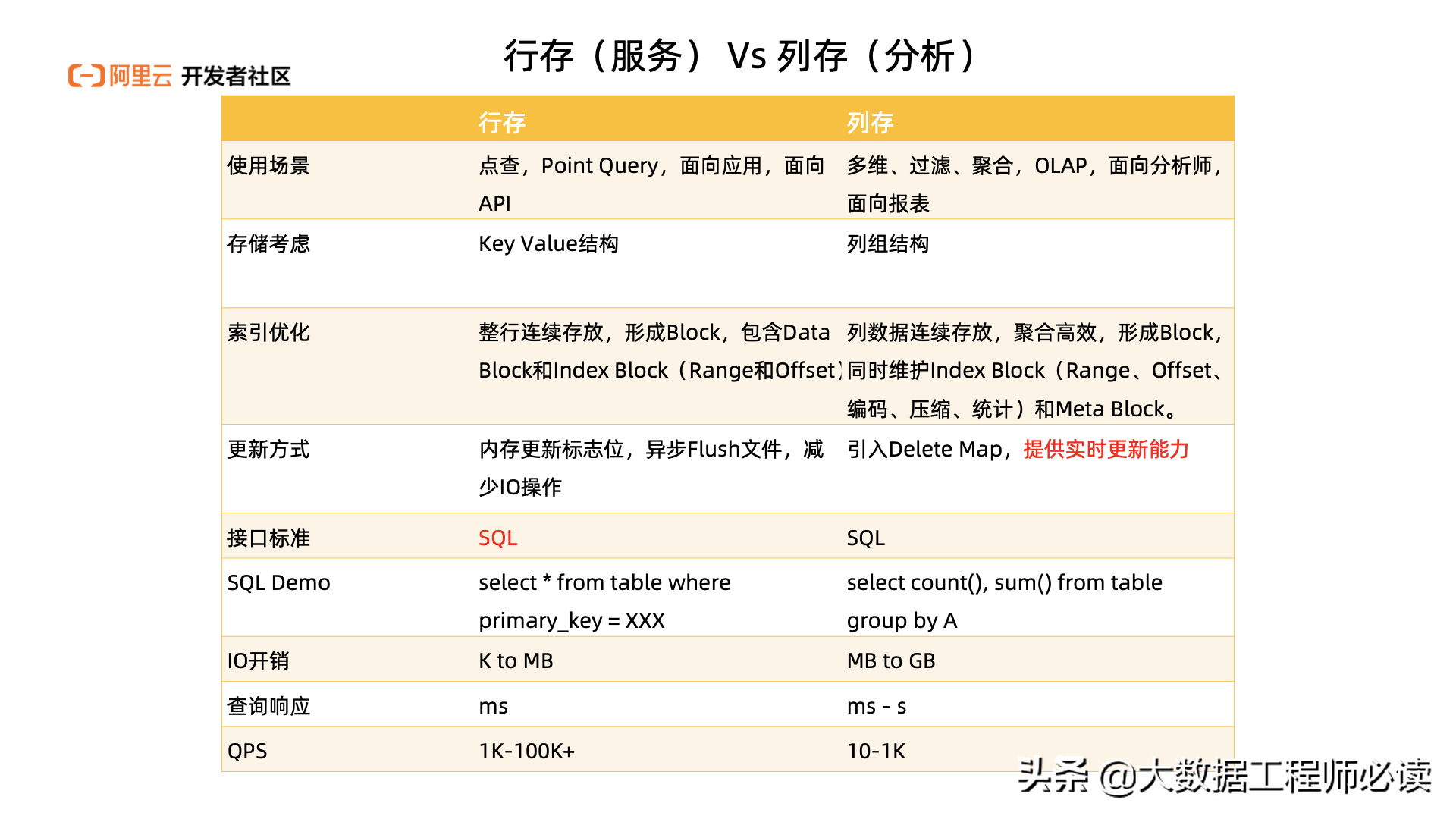
上面提到Hologres既能支持分析,又能支持服务。这是因为Hologres底层会有两种不同的存储模式:行存和列存
,这也就意味着我们既能支持查询的量大,又能支持查的快。下图是Hologres行存和列存两种模式下的对比:
同时,下面也可以给大家分享Hologres与Druid的性能对比(对比基于TPC-H 测试集),可以从图中直观的看到Hologres绝大多数场景下性能更优。
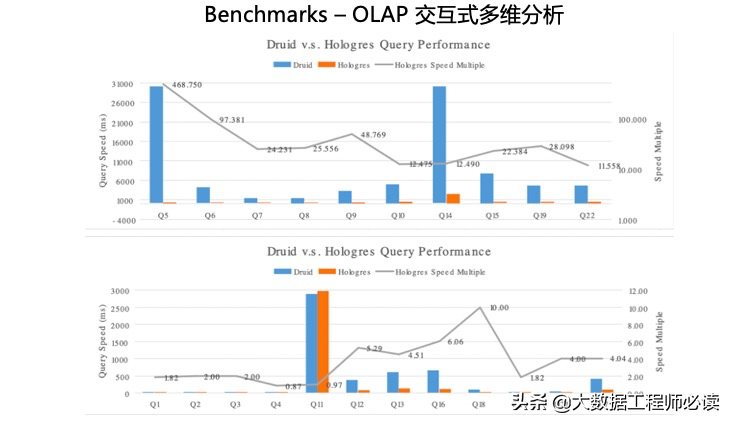
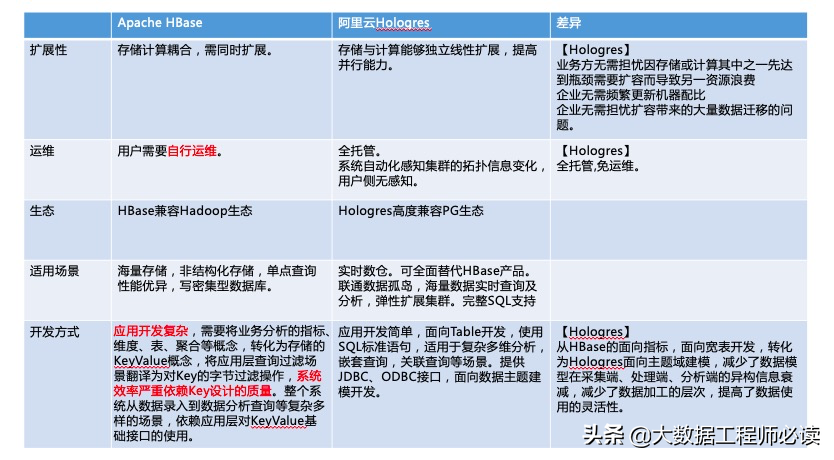
Hologres的另外一个场景是Serving场景,主要是对标HBase。我们看到,在同等的硬件条件下,99%的查询延迟Hologres相对来说都是非常的稳定,小于一微秒。而对于HBase来说,查询延迟随着吞吐量的变高,延迟有很大的扩大。Hologres的定位是同时支持分析和服务两个场景,同时我们也有信心把这两个场景做的都比只做一个场景的那些过去的系统做得更好。对于一个新技术而言,必须要有更高的要求。
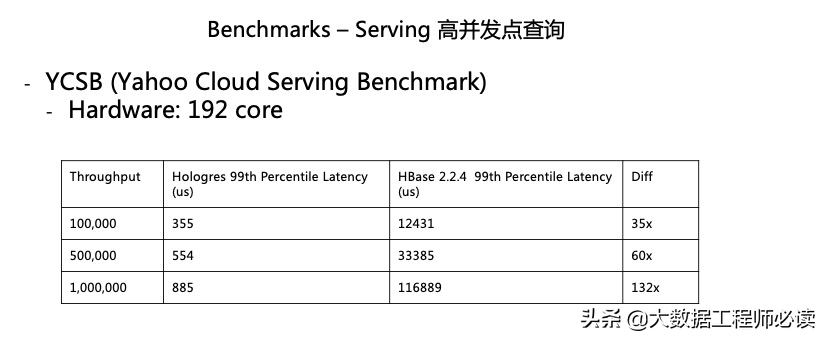
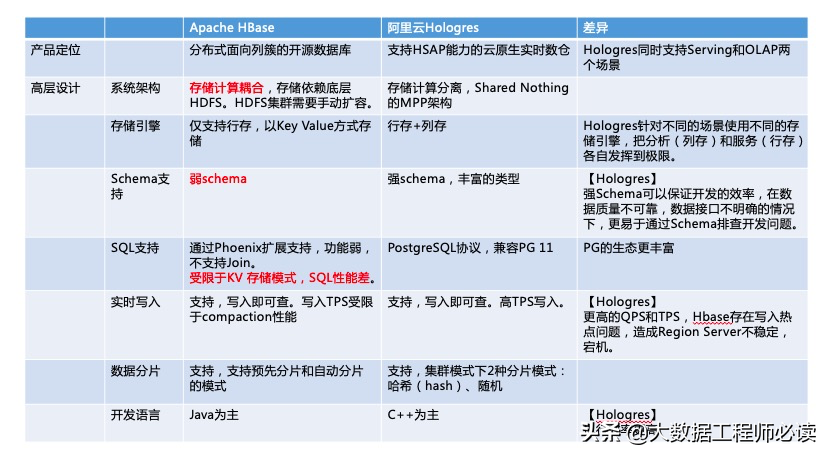
现在绝大多数业务都是用HBase来做服务的场景,在Hologres里使用行存表的效果是优于HBase的。这边给大家比较Hologres和HBase的一些差异点,主要关注红色的部分:
1)看产品定位和高层设计
2)存储引擎和查询引擎的差异
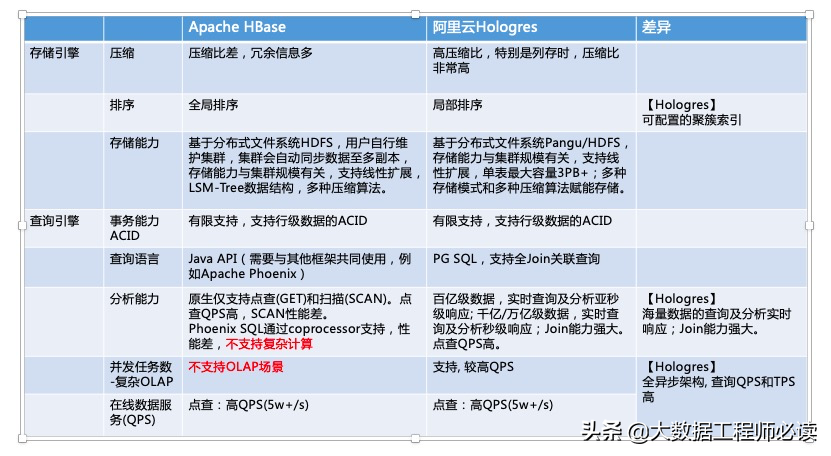
3)扩展性,运维,生态,适用场景,以及开发方式的差异
四、典型应用案例
下面可以来介绍Hologres落地具体业务场景的最佳实践。
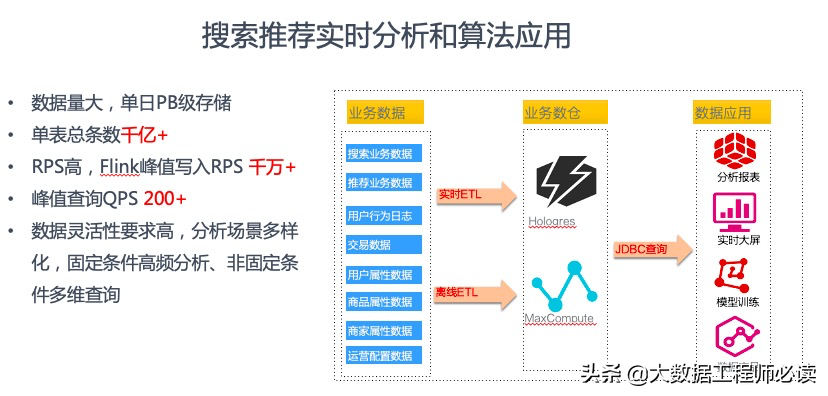
1)阿里巴巴搜索推荐实时分析和算法应用
阿里淘宝系列里边实时的搜索推荐的场景下,也在使用Hologres和MaxCompute的组合。一方面数据量非常的大,我们会首先基于MaxCompute建立整个离线的数仓,它能够处理离线全量的数据,有调动几百上千台机器这样并发的能力。其次推荐场景下,也是对实时要求非常高的。推荐场景的业务方会很关心用户当前对什么产品感兴趣,当前搜索什么样的关键词,当前是通过什么网络、通过什么设备、在什么地域连接了淘宝的一个系统等信息。一些实时特征都会影响搜索的一个结果,对实时特征的计算也非常的重要,所以需要有一个实时数仓的场景,通过Flink加工,把这些实时信息加工成用户和商品的一些特征,然后对接应用使用。最后加工的结果一部分面向分析师,一部分面向机器学习。根据刚才学到的一些知识,我们知道要完成全部的场景会利用到Hologres的列存,也会利用行存。
列存的场景,一般是面向报表的场景,一般会把我们的数据结果变成我们的数据产品,提供给我们的分析师。分析师选择相关的维度做一些过滤组合,得到相关的一些转化率。这相当于是把我们的数据产品作为一种服务。
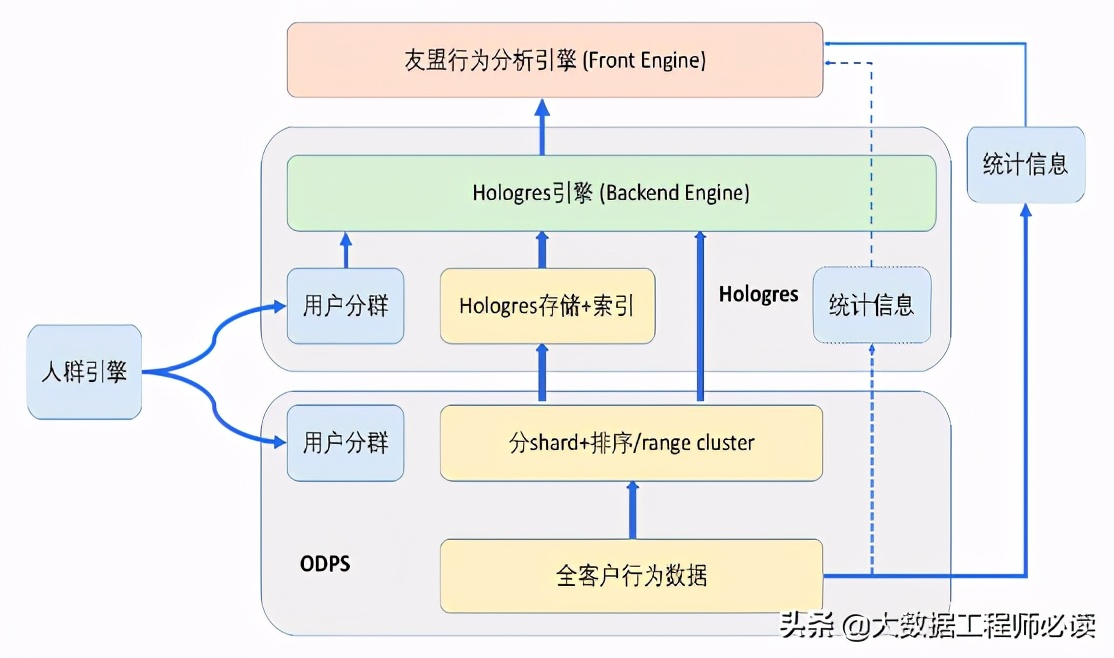
2)友盟
友盟+是国内最大的移动应用统计服务商,其统计分析产品U-App&U-Mini & U-Web为开发者提供基本报表统计及自定义用户行为分析服务,支持精细化运营。业务痛点包括:
业务数据量大,年新增行为数据10PB级, 个性化、自定义地交互式用户行为分析强需 求;
基于MaxCompute提供异步离线的adhoc 分析和优化、以及自研引擎开发尝试均无法 满足业务需求 ;
导出到mysql/Hbase方案的二次开发和数 据导出链路长、成本高、操作不灵活。
在使用Hologres和MaxCompute后,客户得到的收益包括:
PB级数据毫秒级查询响应
与MaxCompute深度集成,能够利用range cluster索引加速,实时离线联邦查询,同时也可以实现冷热数据混合查询,有利于成本性能平衡。
计算资源弹性伸缩,可兼顾扩展性、稳定性、 性能、成本。
3)菜鸟的智能物流
菜鸟智能物流分析引擎是基于搜索架构建设的物流查询平台,日均处理包裹事件几十亿,承载了菜鸟物流数据的大部分处理任务。客户的需求包括:
HBase的架构下维表数据导入耗时长、资源浪 费严重、成本高
HBase不能同时满足PointQuery和OLAP分 析,数据导入导出引发数据孤岛、数据同步负 担、冗余存储、运维成本和数据不一致等问题。
在引入Hologres交互式分析后,客户得到的收益包括:
整体硬件资源成本下降60%+
更快的全链路处理速度(2亿记录端到端3分钟)
一个系统,满KV和OLAP两个场景,没有数据 冗余
解决大维表实时SQL查询需求
强Schema,有效避免潜在错误,节省时间。
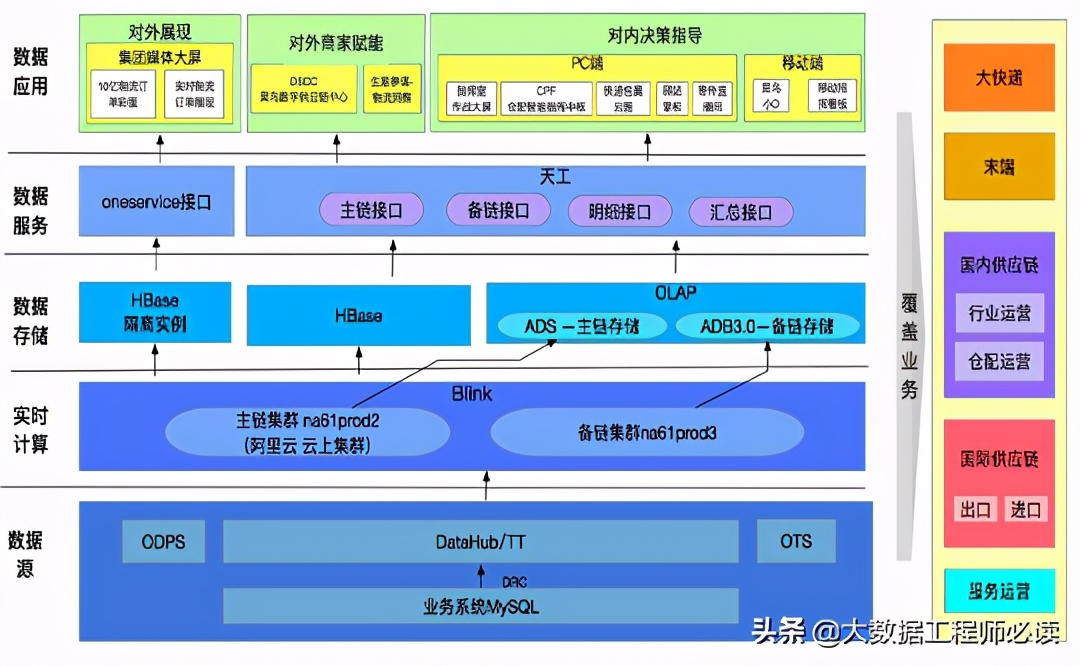
4)实时推荐场合
刚才讲的几个场景,都是偏分析的场景。这边给大家介绍一个推荐的服务的场景。这个场景是实时推荐(特征查询、实时指标计算、向量检索召回),提高广告留存率,用到的主要技术有PAI+Hologres(with Proxima)。客户收益包括:
支持2000万日活用户快速向量检索,千万级u2u,i2i均可以20ms返回
通过SQL描述业务逻辑,无需手工编码
加工逻辑简化,无需额外集群。
这是一个很典型的把数据作为服务的场景。而且数据并没有离开我们的数据平台,还是在我们这套数仓平台里面,还是以表的形式,所以在运维上、开发效率上都会提升很多。
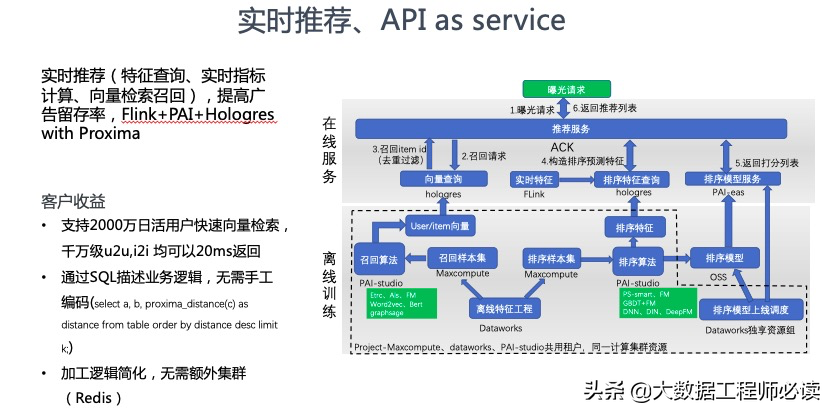
五、MaxCompute+Hologres最佳实践
通过上述典型场景的应用,有些人可能就会有些疑问,是不是就不需要MaxCompute了呢?答案是否定的。其实MaxCompute和Hologres是最好的搭档。这两个产品在技术架构定位场景上是有些差异的,如下图所示,两个放在一起可以实现最好的效果。
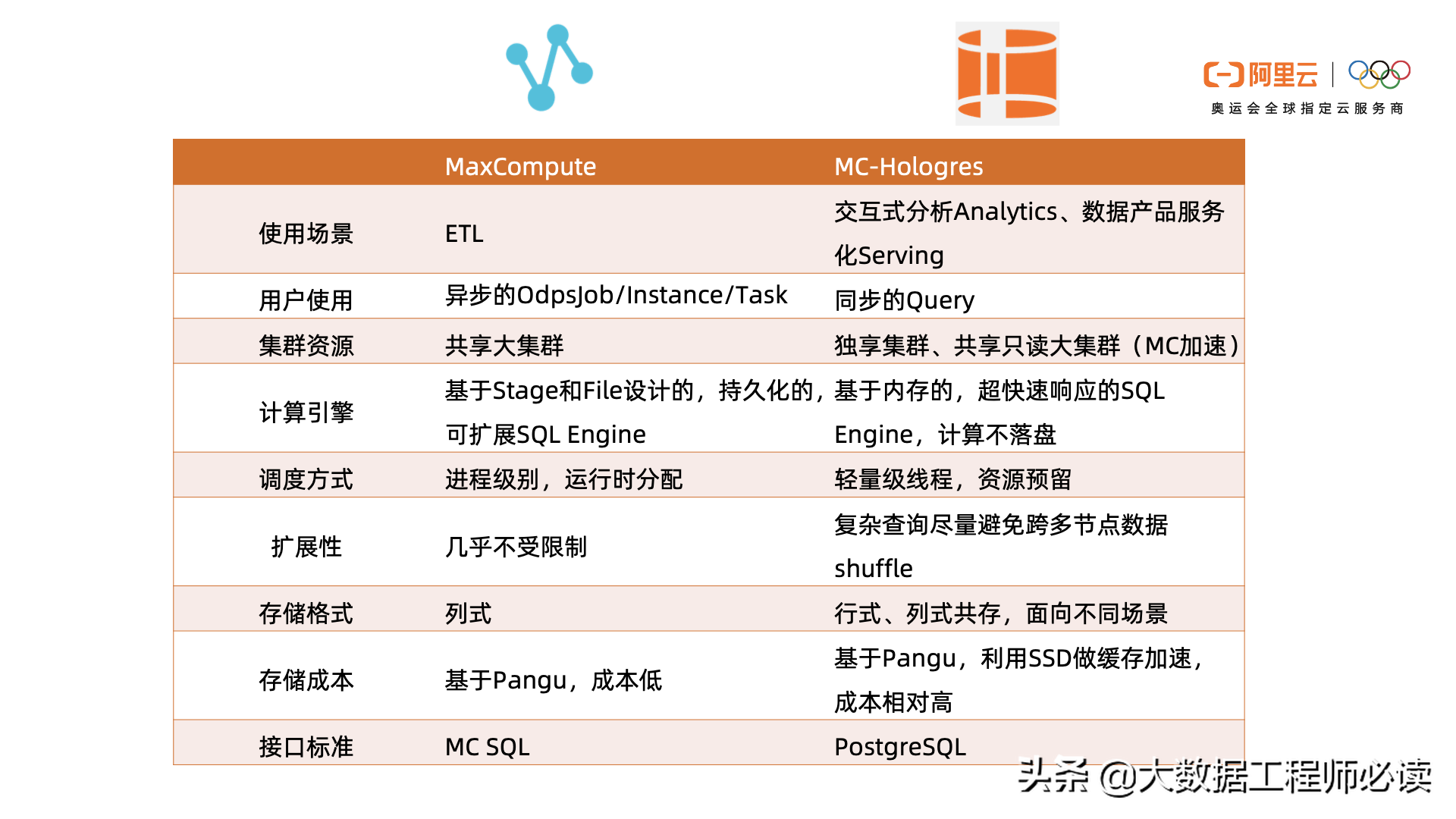
最后给大家讲一下MaxCompute和Hologres怎么放在一起,实现最好的一个加工服务一体化的效果。一般来讲,数仓分层为ODS、DWD、DWS、ADS,如图所示。下面两层放在MaxCompute是比较好的,上面两层可以放在Hologres。总的来说,有如下特点:
面向主题的开发,提供可复用的数仓模型
加工服务一体化:减少数据移动,减少数据孤岛
数仓建模敏捷化:减少数据层次,敏捷适应需求变化,面向DWS、DWD的应用开发。

一般来讲,在Hologres中加速查询MaxCompute有两种方式:
创建外表(数据还是存储在MaxCompute中),性能会有2-5倍的提升
导入内表,性能相比外表大约有10-100倍的提升
当我们设计的数仓,想要它跑的快,至少做好两件事:查询引擎优化和索引设计优化
直接查外表的方式实际上是利用查询引擎的优化能力来提高效率的,但是没有利用到索引能力。所以当把外表导到内表的时候,可以根据查询的方式指定内表的索引结构。通过这些索引能力带来更高的查询性能。这就是外表导入内表,内表的性能更好的原因,就是要充分发挥数仓里边索引优化的能力。


上篇:
国内最大的分布式云,是如何炼成的
下篇:
Lakehouse湖仓一体成为下一站灯塔
1 详情页生成器在线制作,一键自动生成商品详情,电商人告别熬夜做 2 用codex做电商图,顺手做了一条电商工作流 3 Remotion 最强竞品!用 HTML 写视频,AI 自动成片 4 电商必懂的数据公式 5 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 6 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 7 用AI自动生成爆款文案的完整流程 8 地理空间AI应用:YOLO vs. SAM 9 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 10 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 11 5分钟一键生成软著申请材料,coze工作流全教程,含提示词 12 Vaex :十亿行每秒的 Python 大数据神器,探索与可视化的新标杆



