本文作者将站在更加全面的角度分享他在这一年多 DBA 工作中的经验,希望可以给大家带来启发和帮助。

DBA 的日常工作
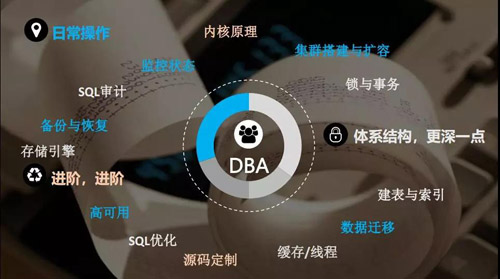
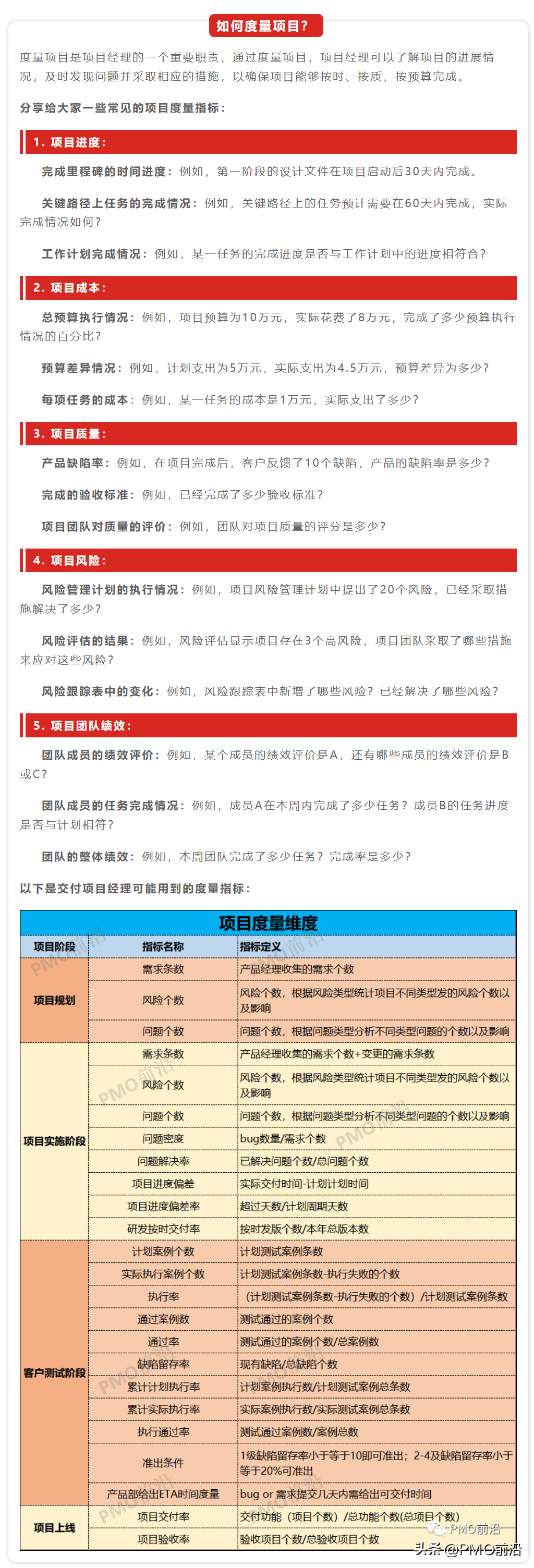
我觉得 DBA 真的很忙,我们来看看 DBA 的具体工作:备份和恢复、监控状态、集群搭建与扩容、数据迁移和高可用。
上面这些是我们 DBA 的功能,了解这些功能以后要对体系结构有更加深入的了解,你不知道怎么处理这些故障和投诉的事情。
所以我们要去了解缓存/线程、SQL 优化、存储引擎、SQL 审计以及锁与实务;体系结构更深一点,就去研究内核原理和源码定制。
DBA 有这么多工作,它们就像一个小怪兽一样等着我们去解决。
MySQL 的性能优化

性能优化让我们的 MySQL 跑的更快、更顺畅。在我们开始 MySQL 性能优化之前,我想提出 MySQL 性能优化的三个关键点:Why?What?How?
为什么我们要做性能优化?我们的运维来反映我们的数据库,正常情况下是 1 秒,后来变成 10 秒,我们就要启动优化的动作。原本他的访问时间是 1 秒,我们想优化成 0.01 秒就要开启优化。
第二就是 What?哪里是导致我们数据库性能变差的原因,需要找到这个关键点。
当我们找到这个问题以后,我们就需要有的放矢地进行优化。MySQL 优化之前我们要明确 3W 关键点。
MySQL 优化基本流程
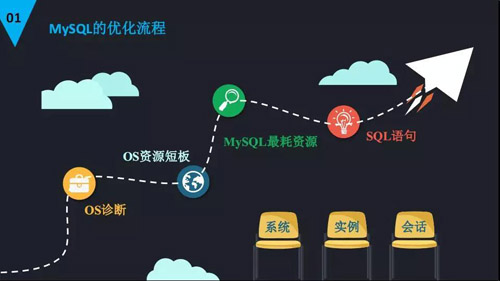
对于开展 MySQL 优化一个基本的流程如下:我们首先要登陆到操作系统,通过操作系统的命令进行优化。
比如说通过操作系统的基本命令,去看我们操作系统有什么资源的占用率比较高。
就是哪里出现了资源短板,短板的意思就是这个资源的占用率或者是使用率特别高,我们要密切关注。
比如说像 CPU 的负载特别高,已经超过了我们的核数,或者是使用率特别高,已经达到了 80% 以上,这就引起我们的关注了。
确定这个短板之后,我们就要确认哪个进程使用我们这个资源,使得它的使用率或者是占用率特别高。
一般情况下跟我们相关的就是 MySQL 这一层,比方说使用 CPU 的 70% 以上,我们就要去检查一下这个 MySQL 出现了什么问题。
再进一步往里推进,如果我们发现 MySQL 里面是执行某一条大 MySQL 的时候,发现整个服务器或者是整个数据库就在那里,可能就是语句问题。
我们就要进一步通过 MySQL 的监控或者是日志信息去排查 MySQL 的问题,很重要的是发现哪个资源出现问题进行排查。
我们登陆系统发现 CPU、IO、网络等等都很正常,这种情况下怎么办?
这种情况下我们可以分三种情况判断:
操作系统的问题,可能我们登陆 MySQL 的时候整个系统就在那里了,我们需要通过操作系统去查是哪个资源的问题。
数据库实例问题,数据库实例问题跟数据库配置参数相关,也就是说我们配置参数可能存在一些不合理的设置需要我们去优化。
会话问题,我们登陆到 MySQL 里面,一开始很正常,后来我们发现这个实例慢下来了,可能就是 MySQL 语句有问题,我们需要看 MySQL 的执行计划到具体哪一步比较慢,拖慢了整个流程。
我们发现数据库性能出现问题,都可以沿着这个流程走下去,从而定位出问题。
MySQL 优化的几个关键点
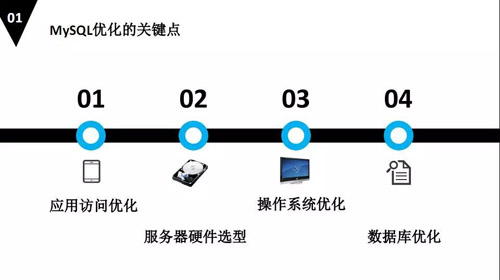
我们通过刚才的基本流程,可以确定出 MySQL 需要优化的几个关键点如下:
应用访问的优化,因为有应用需要访问我们的数据库,有请求的发送、数据的存储和网络的交互等等,会导致数据库性能发生比较慢的地方。
服务器硬件选型,不知道大家 DBA 对服务器有没有自主权,如果有自主权的情况下,我觉得我们应该按照 MySQL 的特性来选择服务器的硬件。
比方说我们可能要考虑到数据和日志的存储机理不同,要选择不同的类型去优化它。
操作系统的优化,就是我们部署配置数据库之前,要对操作系统有什么优化?能够让我们的数据库有优化。
数据库优化,数据库优化过程是一个全局角度优化的过程,不仅仅是是针对数据库本身优化的流程。
应用访问优化
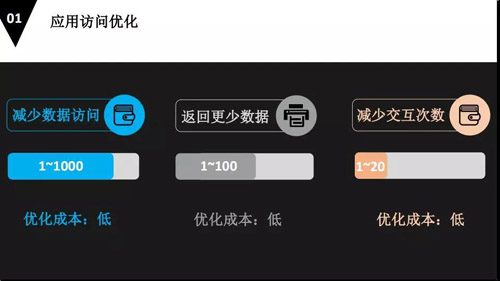
我们根据每个关键点稍微开展一下,比方说应用访问的优化。
首先第一步就是减少数据的访问。因为减少数据的访问其实就是减少磁盘的访问。
我们知道数据访问磁盘获得数据的速度很慢,如果我们是器械磁盘,因为器械磁盘是通过器械旋转来获得数据。
我们应该把活跃数据和内存数据放在内存里面,这样可以使我们的数据库性能提升 1-1000 倍,它的优化成本很低。
第二步是减少返回更多的数据,减少返回更多的数据终结就是减少了网络的传输,有很多大的系统,网络传输是一个很重要的瓶颈。
假设我们的数据库服务器跟我们应用服务器的距离是 20 公里的话,因为光线数据库是 20 公里,一个光的请求是 0.2 毫秒。如果我们减少更少的数据请求的话,那这个时间就会变短很多。
所以说如果我们发现数据库的性能有问题,我们可以去看是否网络上存在问题或者是通过 P 命令看时间是否会变得长。
第三是减少交互次数,每个交互假设还是按照 20 公里来说,一个交互的时间就是 0.2 毫秒,2 个交互就是 0.4 毫秒。如果有 1 万个操作的话,就是 1 万乘 0.4 毫秒,那就变得整个交互时间变短了很多。
但是也有它的复杂性或者是不宜扩展的局面。从应用层就降低了优化。这个成本也是很低的。

我们公司的 DBA 对于服务器的应用选型没有太多的话语权,移动公司都是集团公司通过集采来选择的。
在采集的时候我们不可能规定这几台服务器是用在哪个数据库,这几个数据库用在什么服务系统。所以我们在服务器选型时候 DBA 是没有办法参与进去的。
这是我们移动云的一些服务器的选型:采用的服务器是惠普的 DL360G9,CPU是 2 核×e5-2650V4,内存是 8×32G,硬盘是 6×1.2TSAS,网卡是 4×10GE+4×1GE+1IPMI。
这里特别说一下,如果我们 DBA 对于服务器有自主权的话,我们可以把数据放到 SSD 盘,把日志放到 SAS 上,这就是服务器硬件选型需要主要的地方。
操作系统层面的优化
我们推荐使用 Linux 操作系统,一些开源主流的是我们做的。像一些商业版 Linux 这些就是我们在用的。
如果要使用这个 SWAP 值,我们尽量不去使用虚拟内存,而使用物理内存。因为物理内存的访问速度肯定比去访问磁盘要快得多。
所以我们把这个值设成了 10。有的同学可能就会说为什么不把这个值设成 0,就直接全部访问物理内存就好了。
如果把它设为 0 的话,可能就会出现内存溢出的现象,就是 OOM。这不是我们 DBA 想看到的情况,所以我们一般把这个值设成 10。
关闭 NUMA 特性:我们公司一般是单实例的情况,所以这个时候 NUMA 的特性要关注。
NUMA 特性就是假设我们一个服务器上有两个 CPU,分布在服务器左右两边,同时有四块内存,把同一侧 CPU 作为一个 NUMA 节点,就是在物理位置分布同一侧 CPU 访问同一侧内存,距离比较近,速度更快。
我们尽量同一侧 CPU 访问同一侧内存,这跟我们数据库的特性是相违背的。因为我们数据库希望它一般部署了数据库的服务器就不会布其他的应用系统资源了。
所以我们希望数据库是独占数据库资源,在这种情况下我们要尽量关闭这个 NUMA 特性。
网卡优化:我们采用多个物理网卡通过做 Bond 绑定成虚拟网卡,就是一些双网卡做成 Bond 或者调整网络参数。
磁盘调度设置:一般会有几个算法,如 NOOP 算法、CFQ 或者是 Deadline 算法。
比如说这 NOOP 算法用在我们数据库上有什么问题?就会有饿死读操作的方式存在,如果两个写操作,第一个写操作进来不需要等这个结束以后第二个写操作就可以开展了。
如果是读操作的话,第二个读操作就一定要在在前一个完成。如果有几毫秒的时间里面,进来一堆写操作,后面的读操作就会饿死的,这个不符合我们数据库算法调动的方式。
另外就是 CFQ 算法,CFQ 算法不适合我们的数据库服务器,MySQL 是单操作服务器。所以我们这个算法也不适合我们使用。
一般情况下数据服务器会使用 Deadline 的算法,程序会调用这个时候的 IO 请求去解决这个请求。
这种 Deadline 算法更加适合数据库,因为这个 Deadline 的算法更加适合。
最后一个是文件系统的推荐,我们移动云的数据库系统就是 Xfs 或者是 Ext4 或者是 Noatime 或者是 nobarrier,这些都会有影响。这是数据库系统的优化。
数据库实例的优化

我列了几个我们在标准化的时候需要规范和配置的参数,这里不一一揭示了。
这些参数很重要,因为它决定了我们实例的性能。某一些参数配置不合理,我们实例的性能就会受到很大的影响。
SQL 语句的优化

这里有编写高效 SQL 语句的原则,这个原则我们 DBA 要知道,同时要通知业务方的研发,让他们也知道。
有很多业务侧进来都是业务写的,他没有经验的话,就会写出一些有问题的语句,所以最后就变成我们 DBA 要去严查。
所以最开始要把这些思想贯彻给业务研发,让他们按照这个流程去编写 SQL 的设计。
索引的设计

这里说的是覆盖索引,比如说有了这个覆盖索引我们的查询,查询的字段都是在这个索引内。
还有我们查询的后面的字段也是索引,然后还有我们一些排序位置也是覆盖索引,就是这一系列全部都是中了索引的情况所以就叫覆盖索引。
这里我也列举了一些不能使用索引的情况:比如说不要给选择率低的字段选择索引,如果通过索引扫描记录数超过 30% 就变成全表扫描了。
还有 Like 额查询条件列最左以通配符 % 开始,两个独立索引,其中一个用于索引一个用于排序。以上就是对于 MySQL 性能优化的步骤。
自动化运维实践
所谓自动化运维实践就相当于是给我们 DBA 提供小工具或者是小帮手,帮助我们打开,而不是纠缠着我们。
我们移动云的体量就是几百上千台数据库的体量,如果我们面对几台或者是十几台的数据库的时候,有没有这个自动化其实无所谓,因为你做自动化反而更加麻烦。
如果你已经有大的量的时候就要平台化,在自动化的数据库上进行拓展。以下是我们在自动化运维的实践经验。
标准化安装部署
我们的目录方案,版本以及部署流程有标准文档去遵循。比如说一次部署打包多次应用,我们需要在一个节点上把标准包打包起来就一步完成了,那这个标准化的安装部署就给后面自动化的安装部署打了一定的基础。
自动化数据备份
数据备份是我们 DBA 非常重要的一个工作。所以我们公司也是建立合理有效以及规范的自动化备份的规范。
比方说我们的常规备份,我们是每周一次全备,变更前后,有一个业务变更了,在这之前要做一个全备,万一业务变更哪里出现问题我就可以及时回退。
这个是自动化使用的场景:我们使用的是 innobackup 工具+自动化备份脚本调用+Crontab 定时来做。
自动化日常监控
监控是 DBA 的第三只眼睛,如果建立实时有效的监控非常有效。我们的监控是采用 Zabbix 监控工具。
像确定一些告警阈值这种,一旦超过了这个阈值就可以给我们 DBA 发送短信和邮件,这就是自动化的日常监控。
自动化深度巡检
这个就是补充了监控所不能达到的地方。比方说如果我们需要扫描或者是看一些大表的情况或者是看一些没有建索引表的情况,它的输出很复杂,是一张表或者是几张表,所以我们就需要深度的巡检来完成。
深度的巡检我们公司也是采用开发巡检脚本,通过 Ansible 统一推送,巡检报告自动生成。也就是说可以很明确的呈现出这个巡检的结果供 DBA 去看和去检查。
自动化故障切换
自动化故障切换是发生在单节点发生故障。比如说变更操作,一些 Keepalive 部署配置,切换脚本,VRRP 协议来实现的。
也是通过编写一些脚本,那这个脚本可能会定期去检查我们的数据库节点的运行状况。
比如说这个 VIP 有没有在这个节点或者是进程在不在?一旦发生异常就会自动切换这个节点。
自动化节点扩容
当发生单节点故障的时候,我们需要部署一个新的节点的时候就需要启动自动化的节点扩容,编写脚本来做。

自动化安全审计
这就是异常访问,异常操作可审计追溯。部署安全审计插件,这个安全审计的插件+启用安全审计日志+日志自动化或者是分析提炼。
所以要不要开启这个插件根据各位公司对于安全审计方面的要求以及对于性能的要求从两者取一个平衡。
因为我们还是很看中这个安全事件,所以我们开启了这个安全审计插件,开启这个插件以后还需要配置文件做一个配置。
以什么样的方式存或者是多大?这些参数都可以在配置文件里面进行配置。
自动化密码审计
这个自动化密码审计也是一个插件,就是我们安装了强密码审查的日志,这个插件的工作原理就是设置了规则,我们需要日志要多少位或者是多少位的大小写或者是特殊字符的要求。
我们设置密码的时候必须符合这个强密码验证的要求。这个也是进行实时校验的。
也就是说我们当设一个数据库用户的密码,如果不符合这个强密码的需求就不会给他通过,防止一些比较容易破解的弱密码。
自动化日志分析
我们的日志分析挺重要的,如果出现问题就需要这个日志分析,没有问题正常的时候也需要日志分析工具的。
因为它能够发生潜在的优化建议,我们采用一个 Percona 为工具 Pt-query-digest,我们只需要看 DBA 的慢日志又可以发现哪些内容存在问题。
自动化数据校验
我们通过自动化验校修复工具来做,也是设了 Crontab 的任务让它定期执行。
自动化数据清理
因为数据库每天每周都在备份,我们就需要机制定期清理备份文件。
我们也是采用脚本去开发和定时看,如果超过两个月的备份文件我们就把它删掉。如果文件都在两个月就不用管它。超过两个月就清除它。
自动化日志切分
如果数据库跑的时间比较长,慢日志或者是错误日志比较大,就需要定时检测日志文件,大于某值则自动切分,否则不处理。
以上就是我们在数据库运维的沉淀和积累。虽然不像腾讯或者是阿里那么大的体量和经验,但是以上是我们探索出来的一些经验,希望可以给各位带来启发或者是帮助。


上篇:
MySQL 大表优化方案
下篇:
MySQL 多实例安装
1 根据工作岗位要求, 写一份现场面试者工作自我介绍简述, 要求800字 2 K8S常用命令手册 3 运维必备:掌握这3个存储技术 4 IT运维服务方案V3.0【拿来即用】 5 微软架构师:用FastAPI+Redis构建高并发服务,性能提升2000%! 6 Oracle SQL Developer - Oracle优化教程 7 流量杀手 —— EasyDDOS高性能DDOS工具 8 运维服务方案详解 9 使用OBD白屏部署OceanBase数据库 10 OceanBase 集群高可用部署方案简介 11 php 增加 拓展 oci8 - 支持oracle数据库 12 PVE 给系统盘扩容磁盘空间