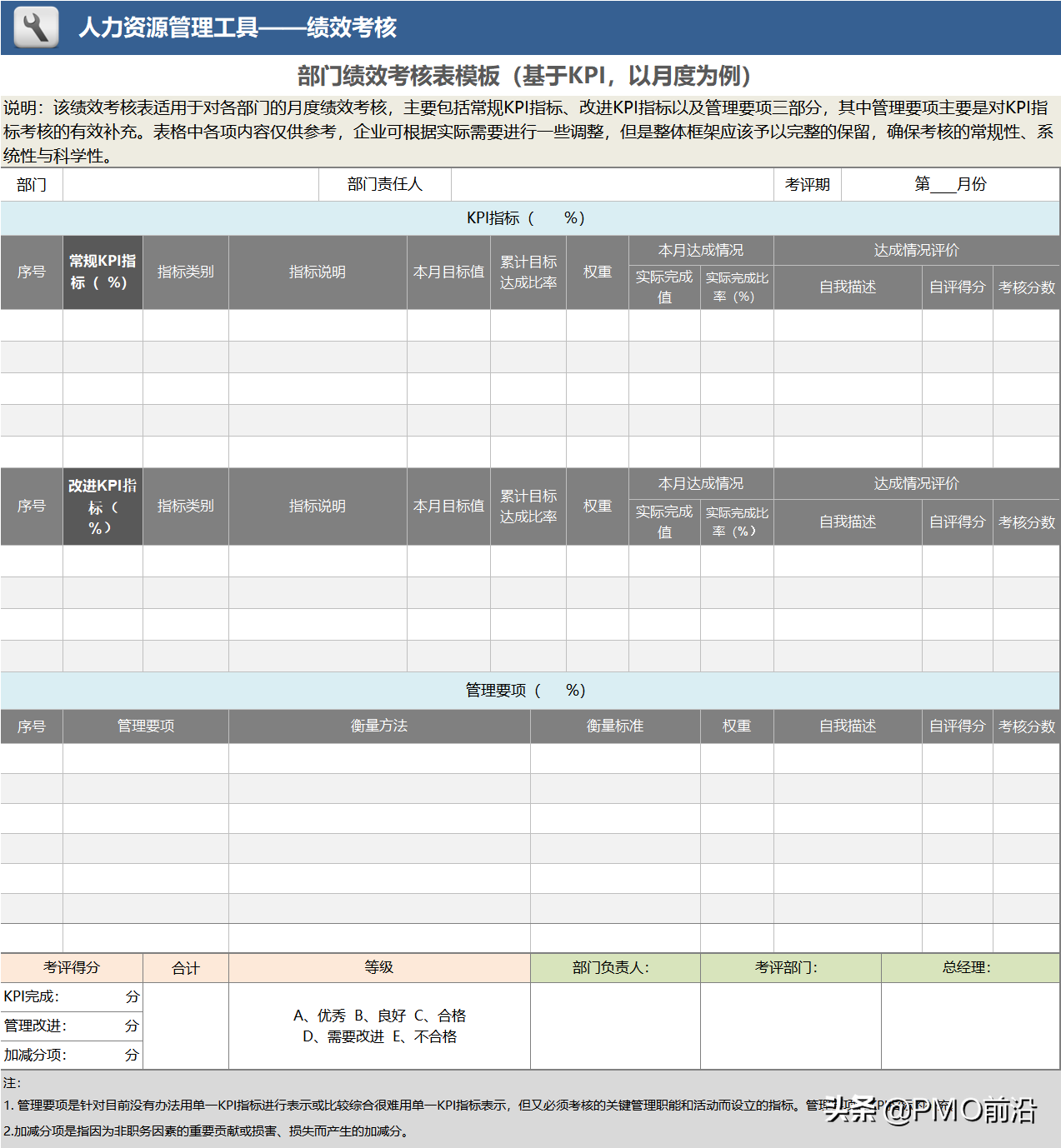
数据湖架构
大多数公司都有大量的业务数据,这些数据通常孤立在各种存储系统中,包括数据库和数据仓库。为了充分利用这些数据资产,您应该将数据集中并整合到统一的数据存储中,以增强分析能力。
通过数据湖架构,组织可以更大规模地简化跨职能企业分析。查询数据湖和收获丰富洞察的能力带来了巨大的商业价值。当正确的建立和部署,数据湖给你的能力:
集中、整合和编目业务数据,从而消除与数据孤岛相关的问题
以无缝方式集成广泛的数据源和格式
助力数据科学并利用机器学习
通过向多个用户提供自助服务工具来实现企业数据的大众化。
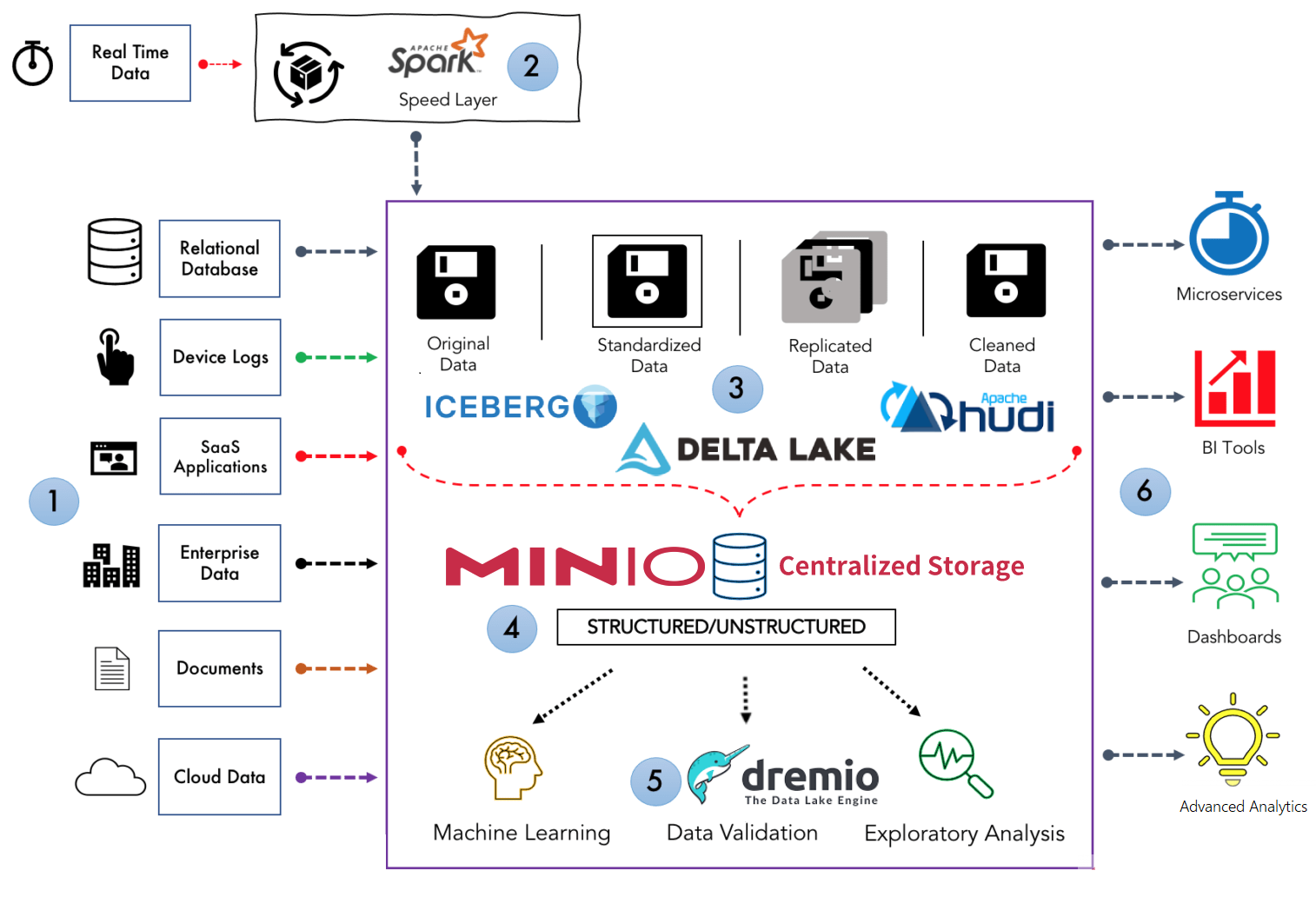
以下是对数据湖架构的组件1到6的简要说明。
数据源:包括大量结构化和非结构化数据源输入数据湖。其中包括关系数据库、设备日志、企业数据、SaaS 数据、文档、云数据等等。
数据处理: 数据湖包含所有类型的数据资产,其中大部分不是实时产生的。因此,加载到数据湖中的大多数数据都以批处理格式存储。在将数据放入湖中之前,使用lambda 架构或Kafka Streams等实时数据框架(如: Spark)进行流处理。
数据转化:虽然数据湖是用于保存数据的统一中央存储库,但这些数据不会未经任何清理或处理就加载到数据湖中,并可以将其处于更好的结构或格式(如:DELTA LAKE/ICEBERG/HUDI)中以便于分析。
数据存储:这里是存储不同类型数据的地方。MinIO等工具用于存储目的。
数据分析: 数据湖允许企业中的各个团队使用他们选择的分析工具和框架(如: Dremio)访问数据。分析师可以利用这些数据,而无需将其移动到单独的存储中进行处理、分析、提炼或转换。
报告: 数据湖连接到现代商业智能工具,如 Apache Superset、Metabase 或 Tableau,用于准备数据以进行分析和构建报告。
对于想要存储多种类型的数据并从其数据资产中获得巨大价值的企业来说,数据湖非常强大。


上篇:
RHCS实验 - RedHatClusterSuite
下篇:
seatunnel - 海量数据(离线&实时)同步和转化的数据集成平台 -Spark && Flink
1 电商必懂的数据公式 2 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 3 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 4 用AI自动生成爆款文案的完整流程 5 地理空间AI应用:YOLO vs. SAM 6 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 7 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 8 一分钟教会你如何制作财神临门视频,简单出效果 9 5分钟一键生成软著申请材料,coze工作流全教程,含提示词 10 Vaex :十亿行每秒的 Python 大数据神器,探索与可视化的新标杆 11 大数据安全架构设计方案 12 一天做出短剧App:我的MCP极速流