《GitHub精选》是我们分享Github中优质项目的栏目,包括技术、学习、实用与各种有趣的内容。本期推荐的是有关大数据的内容,想要学习大数据的同学福利来啦!

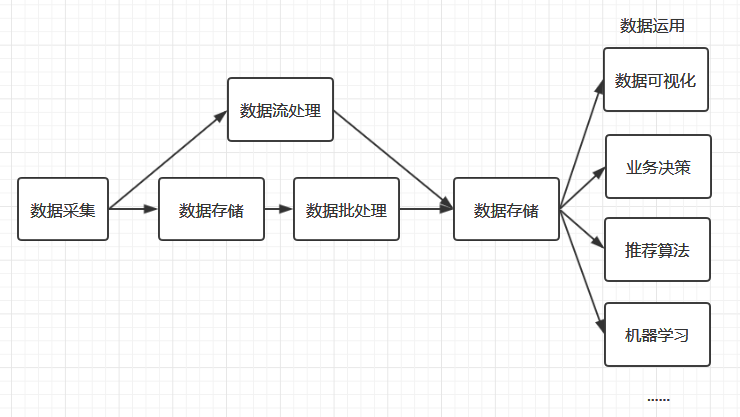
大数据处理流程
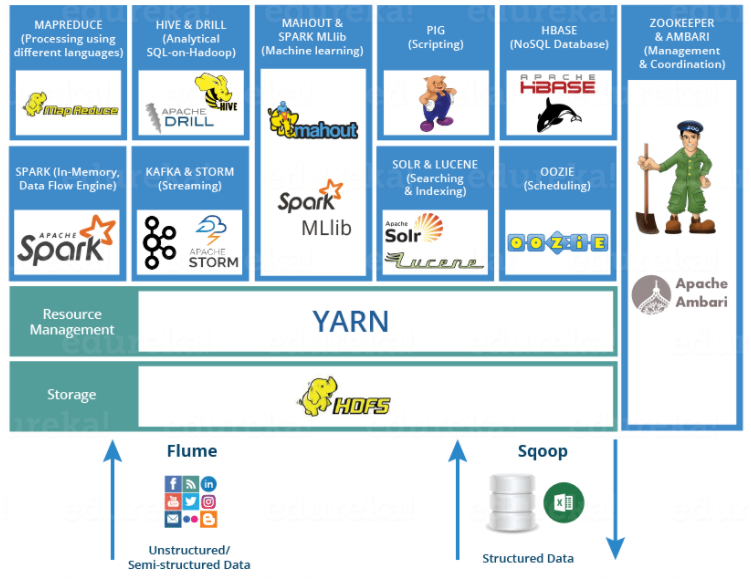
学习框架
日志收集框架:Flume、Logstash、Filebeat
分布式文件存储系统:Hadoop HDFS
数据库系统:Mongodb、HBase
分布式计算框架:
批处理框架:Hadoop MapReduce
流处理框架:Storm
混合处理框架:Spark、Flink
查询分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
集群资源管理器:Hadoop YARN
分布式协调服务:Zookeeper
数据迁移工具:Sqoop
任务调度框架:Azkaban、Oozie
集群部署和监控:Ambari、Cloudera Manager
数据收集:
大数据处理的第一步是数据的收集。现在的中大型项目通常采用微服务架构进行分布式部署,所以数据的采集需要在多台服务器上进行,且采集过程不能影响正常业务的开展。基于这种需求,就衍生了多种日志收集工具,如 Flume 、Logstash、Kibana 等,它们都能通过简单的配置完成复杂的数据收集和数据聚合。
数据存储
收集到数据后,下一个问题就是:数据该如何进行存储?通常大家最为熟知是 MySQL、Oracle 等传统的关系型数据库,它们的优点是能够快速存储结构化的数据,并支持随机访问。但大数据的数据结构通常是半结构化(如日志数据)、甚至是非结构化的(如视频、音频数据),为了解决海量半结构化和非结构化数据的存储,衍生了 Hadoop HDFS 、KFS、GFS 等分布式文件系统,它们都能够支持结构化、半结构和非结构化数据的存储,并可以通过增加机器进行横向扩展。
分布式文件系统完美地解决了海量数据存储的问题,但是一个优秀的数据存储系统需要同时考虑数据存储和访问两方面的问题,比如你希望能够对数据进行随机访问,这是传统的关系型数据库所擅长的,但却不是分布式文件系统所擅长的,那么有没有一种存储方案能够同时兼具分布式文件系统和关系型数据库的优点,基于这种需求,就产生了 HBase、MongoDB。
数据分析
大数据处理最重要的环节就是数据分析,数据分析通常分为两种:批处理和流处理。
批处理:对一段时间内海量的离线数据进行统一的处理,对应的处理框架有 Hadoop MapReduce、Spark、Flink 等;
流处理:对运动中的数据进行处理,即在接收数据的同时就对其进行处理,对应的处理框架有 Storm、Spark Streaming、Flink Streaming 等。
批处理和流处理各有其适用的场景,时间不敏感或者硬件资源有限,可以采用批处理;时间敏感和及时性要求高就可以采用流处理。随着服务器硬件的价格越来越低和大家对及时性的要求越来越高,流处理越来越普遍,如股票价格预测和电商运营数据分析等。
上面的框架都是需要通过编程来进行数据分析,那么如果你不是一个后台工程师,是不是就不能进行数据的分析了?当然不是,大数据是一个非常完善的生态圈,有需求就有解决方案。为了能够让熟悉 SQL 的人员也能够进行数据的分析,查询分析框架应运而生,常用的有 Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix 等。这些框架都能够使用标准的 SQL 或者 类 SQL 语法灵活地进行数据的查询分析。这些 SQL 经过解析优化后转换为对应的作业程序来运行,如 Hive 本质上就是将 SQL 转换为 MapReduce 作业,Spark SQL 将 SQL 转换为一系列的 RDDs 和转换关系(transformations),Phoenix 将 SQL 查询转换为一个或多个 HBase Scan。
数据应用
数据分析完成后,接下来就是数据应用的范畴,这取决于你实际的业务需求。比如你可以将数据进行可视化展现,或者将数据用于优化你的推荐算法,这种运用现在很普遍,比如短视频个性化推荐、电商商品推荐、头条新闻推荐等。当然你也可以将数据用于训练你的机器学习模型,这些都属于其他领域的范畴,都有着对应的框架和技术栈进行处理,这里就不一一赘述。
GITHUB地址:
https://github.com/heibaiying/BigData-Notes#%E4%BA%94flink


上篇:
Lakehouse湖仓一体成为下一站灯塔
下篇:
NCNN、OpenVino、 TensorRT、MediaPipe、ONNX,各推理架构比较
1 电商必懂的数据公式 2 AI新玩法,制作历史大事件视频,涨粉20w,获赞220w 3 用AI全流程制作历史故事短剧,保姆级教程,零基础上手 4 2026 年 AI 创业全景指南:给渴望借 AI 逐梦的人! 5 用AI自动生成爆款文案的完整流程 6 地理空间AI应用:YOLO vs. SAM 7 智能目标检测:用 Rust + dora-rs + yolo 构建“机器之眼” 8 vLLM + FastAPI:一个高并发、低延迟的Qwen-7B量化服务搭建实录... 9 5分钟一键生成软著申请材料,coze工作流全教程,含提示词 10 Vaex :十亿行每秒的 Python 大数据神器,探索与可视化的新标杆 11 大数据安全架构设计方案 12 一天做出短剧App:我的MCP极速流