大家好,在日常生活工作中我们会和很多文档打交道,今天这期我们将一起看下如何使用LlamaIndex和LangChain来构建一个基于GPT-4的本地文档知识库聊天机器人。

在我们开始搭建本地自定义知识库之前,让我们先来聊下使用chatGPT网页端的一些限制。由于OpenAI网页端使用的是预训练模型,这意味着它的知识库只能包含在模型训练期间提供的数据。(目前数据还停留在2021年)因此,它无法回答特定的、最新的数据或一些私有未公开数据的问题。另外,网页端的GPT4还有3小时内只能回答25个问题的限制,所以我们这次的目的通过搭建本地知识库来突破这些限制
下面开始我们的教程,首先介绍一些本地AI聊天知识库的原理,核心可以分为两部分:
一、数据的摄取/建立索引阶段:这个阶段主要通过 LlamaIndex 和 LangChain 将你的文档转化为矢量数据并建立索引数据;
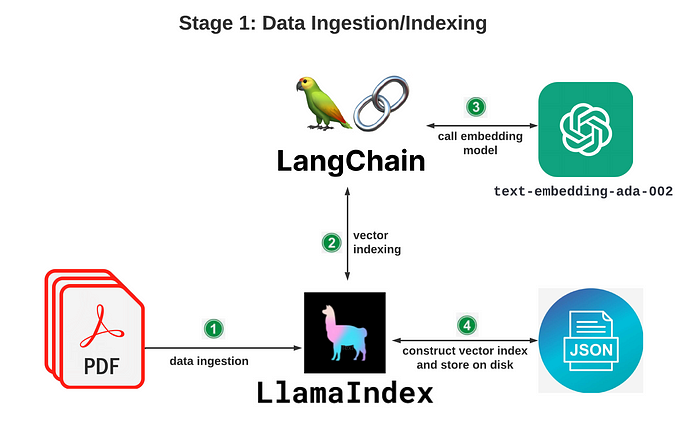
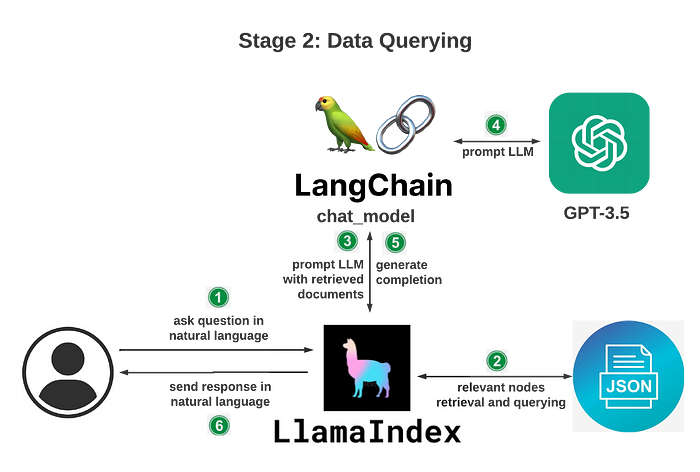
二、数据查询阶段:在此阶段当用户发起提问时在已有的索引中返回提问最相关的向量节点,将文档中和提问相关的上下文都做为prompt传给GPT4,最后GPT4会根据完整的prompt生成相关的响应内容再返回给用户,这样的好处就是对比原生的GPT能得到更精准、更精确的回答,极大降低GPT的错误率;
OK,下面我们来看下具体如何实现:
首先需要在本地环境中安装Python,另外需要准备一个OpenAi 的ApiKey,这里因为我的官方账号只有GPT3.5接口所以我用了国内一家代理提供的GPT4接口来进行演示(app4gpt)。
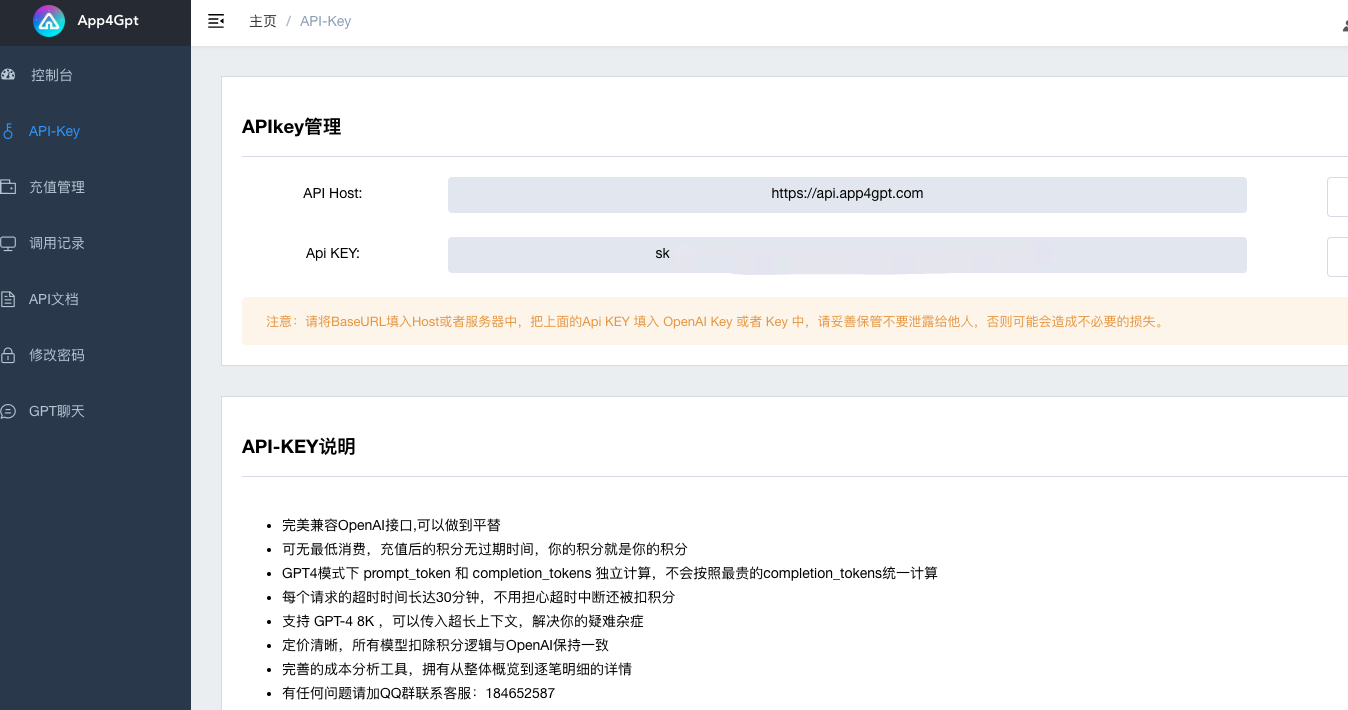
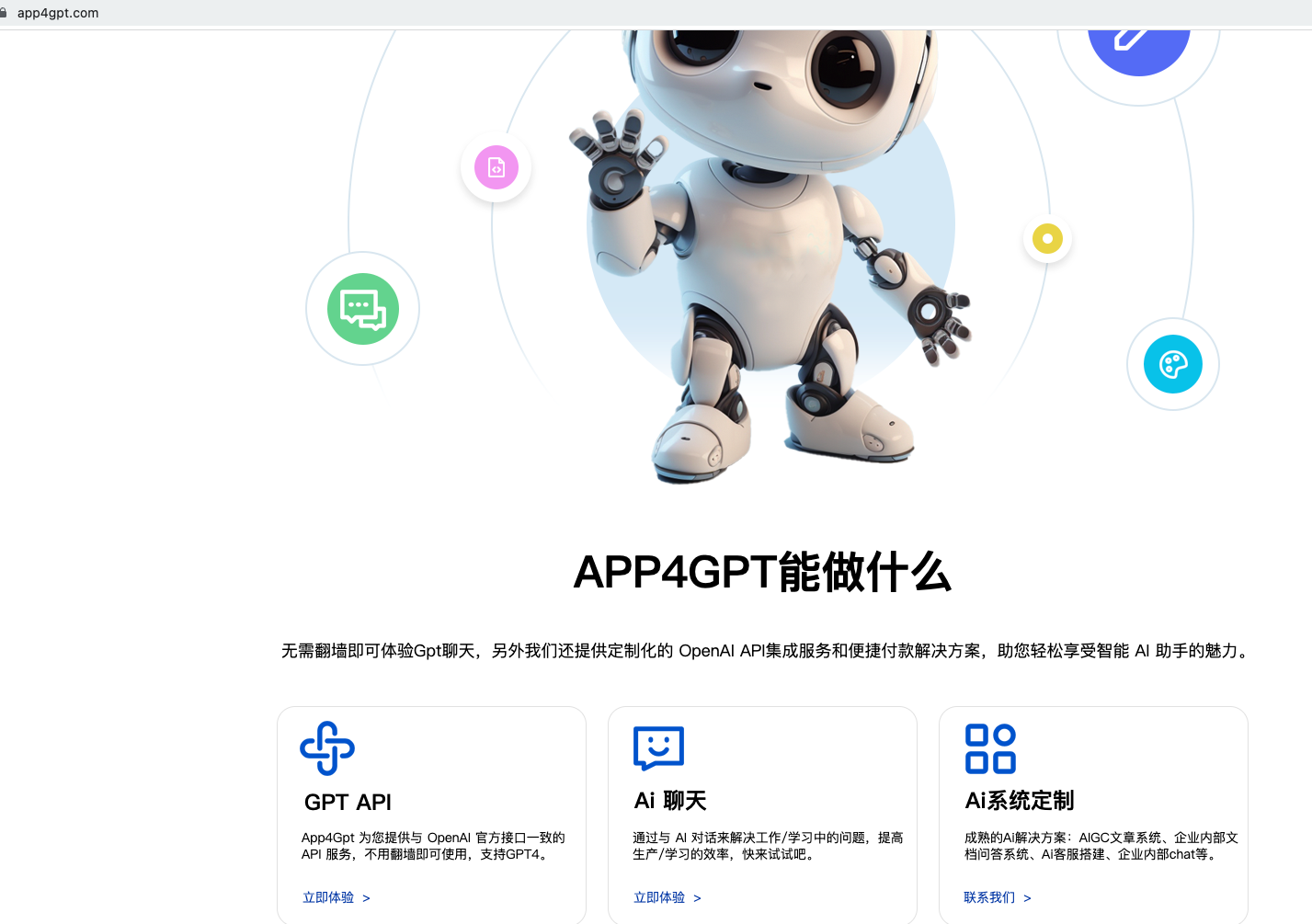
这里所说的第三方代理,其实就相当于是国内OpenAi代理商。当我们调不通官方服务时就需要去调中间商提供的中转服务,现在我使用的是app4gpt,代理商帮我解决了海外服务器问题以及API充值问题。大家可以通过必应搜索app4gpt找到该网站。
接下来我们需在本地建立一个文件夹,命名为ChatDemo,通过命令行工具进入这个目录并安装我们所要依赖的库,

这里简单介绍一下这些库在项目中的作用:
第一个 OpenAi库:
引用的目的有2个:一、通过OpenAI的嵌入模型来完成数据的转化、提取并建立索引;二、我们最后会调用OpenAI的GPT4的模型生成自然语言;

第二个 LangChain库:LangChain是一个开源库,为开发人员提供必要的工具来创建由大语言模型驱动的应用程序。这个项目中我们主要会使用到LangChain的Chat_Models模块。
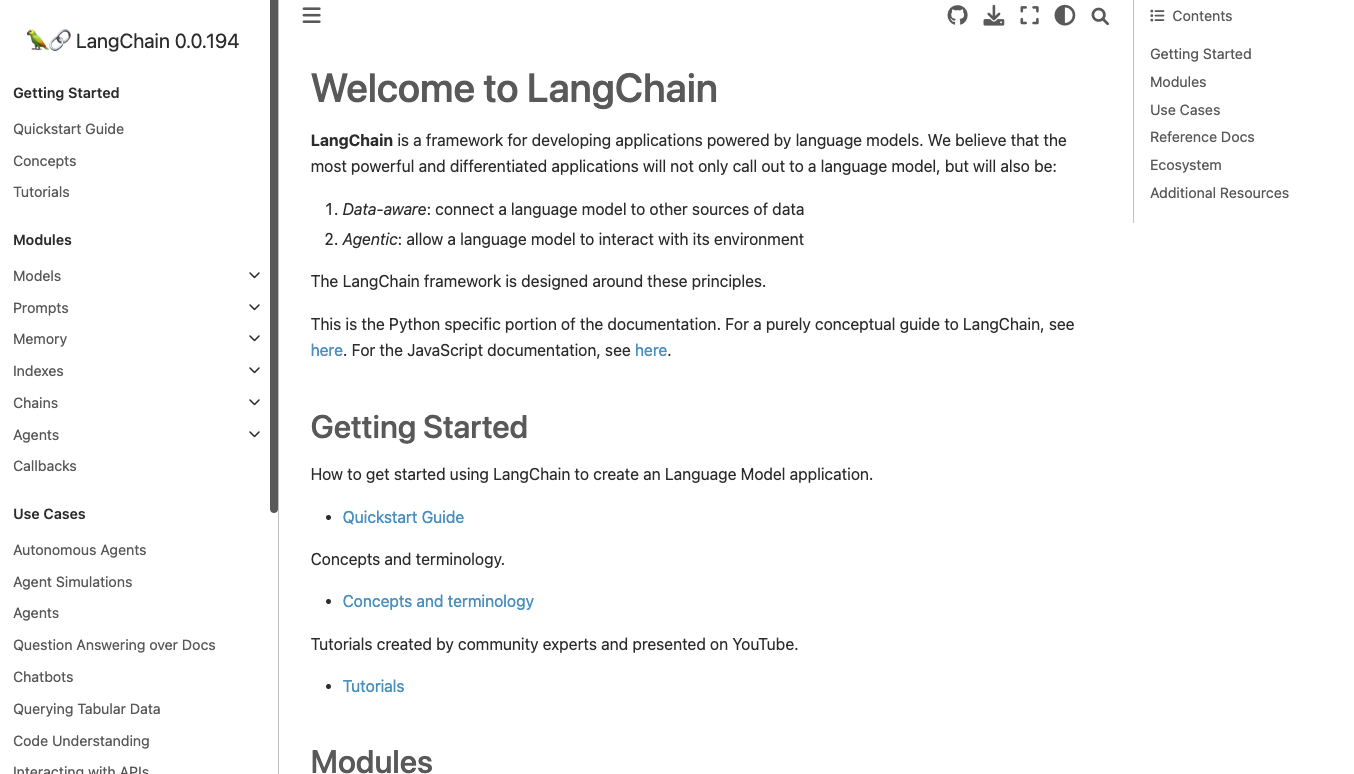
第三个 LlamaIndex:LlamaIndex是大语言模型应用程序的一个处理数据的框架。简单来讲通过 LlamaIndex 可以将大语言模型与外部数据连接起来,并允许我们根据提供的数据来创建聊天机器人,本项目主要使用的就是这个框架。
第四个 P Y Pdf是一个免费开源的python PDF库,能够分割,合并,裁剪和转换PDF文件的页面。我们将使用这个库来解析我们的PDF文件。
第五个 Gradio是一个开源Python库,只需要通过几行代码就可以快速的搭建一个机器学习相关的应用程序。
接下来我们需要为项目添加数据源pdf文件,并存放在项目的data目录下,基于这些文档来训练我们的本地知识库聊天机器人。

聊天机器人具体实现步骤及主要函数讲解:
1.在ChatDemo文件夹中新建一个Demo 点 Python文件,并导入需要使用的模块和类:

2.设置OpenAI_API_KEY ,这里由于我们需要使用到gpt4的接口,所以需要先将Base Url改为国内代理的U R L,再填入国内代理提供的key。
3.上下文环境函数
这个函数主要作用有两方面:一方面主要设置一些约束参数,如输入的最大数量、输出的数量、块重叠的最大值和文本块大小的限制。另外,它还实例化了两个类,即PromptHelper 和 L L M Predictor。
PromptHelper主要负责生成适当的提示语句,使模型能够理解并有效地响应我们的查询。而L L M Predictor则负责调用gpt-4语言模型来生成我们期望的回答。
4.数据提取/索引建立函数
该函数负责提取pdf数据,并根据我们知识库中的内容来创建并保存索引,来用于后面的数据查询场景。
主要功能有以下几点:
·这个函数中通过Simple Directory Reader从指定的目录路径加载数据;
·通过GPT Vector Store Index将文档建立为索引;
·最后将转化完的索引存放在默认的storage文件夹下,并返回index索引对象。
5.查询函数
通过这个函数我们可以从磁盘上的存储位置来加载索引。然后查询input中输入文本的相关索引,最终返回查询后的内容。
6.G R.Interface函数
通过这个函数使用Gradio库创建一个交互式的Web用户界面。它将上面的data_querying函数作为用户输入的处理函数,并设置了输入框和输出框的一些属性。
7.最后调用之前的数据索引提取函数, 并传入"data"作为参数,这个data就是我们存储pdf文档的地址,最终会返回一个index索引的实例。
到这里本地知识库GPT4机器人就搭建好啦,完整的代码链接我会放在评论区,大家也可以通过私信我来索取代码。
接下来我们通过终端来运行一下并看看效果。
在浏览器中打开本地URL可以看到这个web应用程序,我们向机器人提出一个和文档内容比较相关的问题,以此来对比一下原版GPT和自定义知识库GPT答案的区别;
可以看出自定义知识库GPT 由于我们喂了更多相关的文档资料,所以他的回答能更精准有效,给出的回答也是更专业一些。


上篇:
没有了
下篇:
通义千问-14B - 140亿参数规模的模型 - 基于Transformer的大语言模型
1 老板资本赋能:各轮股权融资区别 2 同城实体老板必看!AI + 短视频,开启获客新时代 3 DeepseekR1+ollama+dify1.0.0搭建企业/个人知识库 4 静态路由:使用静态让所有主机实现相互通信,并都可以访问公网_采用静态路由方式,实... 5 如何打造属于你的定制化大模型聊天机器人 6 AI大模型中 .safetensors 文件、.ckpt文件、.gguf和.pt... 7 追女生最稳的方式 8 黑群晖最新安装方式 9 介绍部署esxi8.0产品的方式 10 QAnything - 网易有道开源的本地化知识库问答系统 11 20个最直接的赚钱方式 12 身家过亿的老板都是这么运营公司的