回合对战数据指标计算,耗时过长,甚至因为单机内存不足无法满足需求,故考虑将原本单节点的单机ClickHouse改为集群 , 采用分布式表来进行相关计算。
环境搭建
单机方案

集群方案 3分片1复
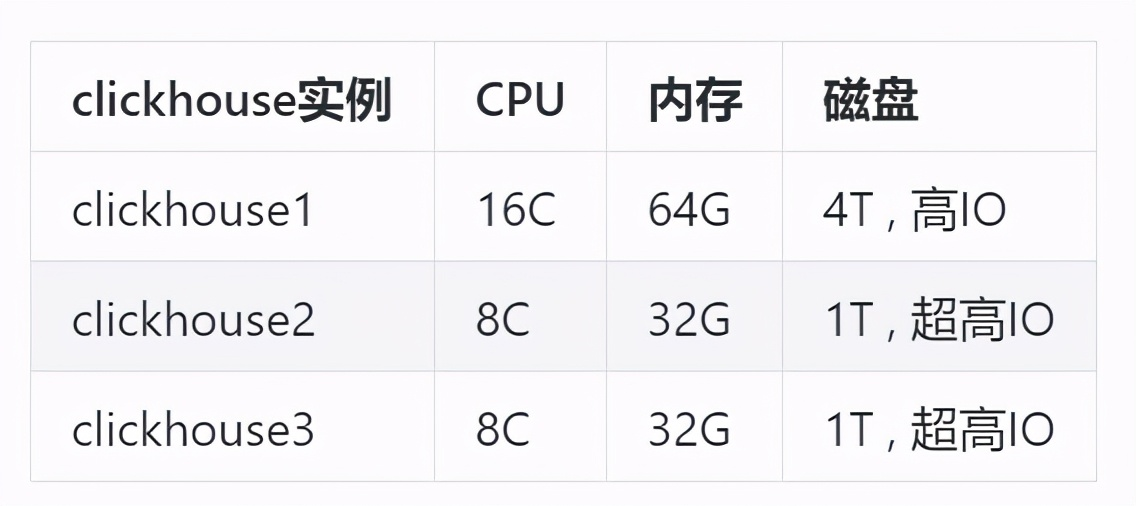
方案对比
写入速度对比
数据量 : 26910101 Rows
方案一 : 单机方案( 全量数据插入单机表 )

方案二 : 集群方案( 数据写入物理表,分别并行向3台机器物理表写入数据 )

结论 : 写入数据速度和磁盘IO有关 , 集群方案数据写入相比单机方案有显著优势。
查询对比(主要针对分组查询 和 关联查询操作)
分布式建表方法
--物理表
CREATE table rd_physical.rd_baseinfo_physical on cluster cluster_3shards_1replicas
(`appId` String,`pvpId` String,`accountId` String,`userName` String,`round` Nullable(Int32),`event` String,`mode` Nullable(Int32),`win` Int32,`country` String,`timeStamp` String,`ts` DateTime,`ds` Date)ENGINE = ReplicatedMergeTree('/clickhouse/rd_physical/tables/{shard}/rd_baseinfo_physical', '{replica}')PARTITION BY (ds)ORDER BY (appId, accountId, pvpId)SETTINGS index_granularity = 8192
--逻辑表
CREATE table rd_data.rd_baseinfo on cluster cluster_3shards_1replicas
(`appId` String,`pvpId` String,`accountId` String,`userName` String,`round` Nullable(Int32),`event` String,`mode` Nullable(Int32),`win` Int32,`country` String,`timeStamp` String,`ts` DateTime,`ds` Date)ENGINE =Distributed(cluster_3shards_1replicas, rd_physical, rd_baseinfo_physical, cityHash64(accountId))分组查询
SQL语句 : select count(*) , accountId,pvpId from rd.rd_baseinfo where ds>='2019-12-01' and ds<'2020-01-01' group by accountId ,pvpId ;

结论 : 集群方案对数据分类查询效率比单机高出25%左右。
关联查询
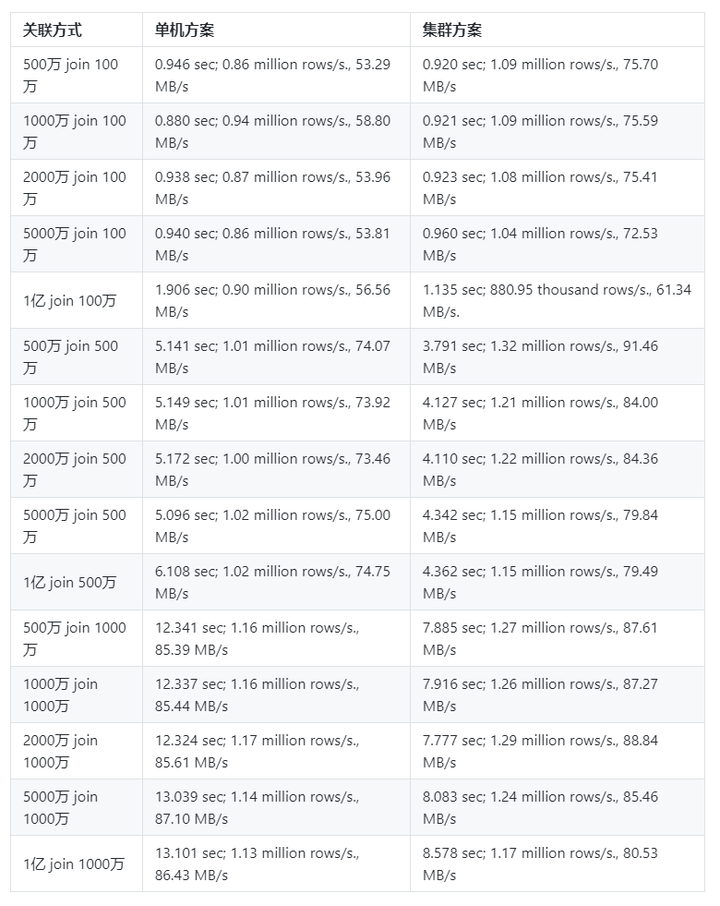
结论 : 小数据量join操作 , 单机方案和集群方案差异很小 ; 大数据量单机方案不如集群方案 , 单机方案还可能会存在内存不足等问题。
其他方面
ClickHouse并发较小 , 官网查询建议100 Queries / second , 单机ClickHouse不适合做业务型高并发查询。ClickHouse集群可以通过chproxy 将并发的查询代理到集群上各分片上去作查询 , 可以极大提高了并发量。
性能测试总结
单机方案写数据的性能上远不如集群方案。
查询方面, 数据量小时的查询单机方案和集群方案相差不明显, 数据量大时集群方案不会存在内存,cup不足等问题,同时查询的效率也高于单机方案。
集群方案相较于单机方案 , 建表略有繁琐 , 分布式表写数据无法实时写入各个分片物理表 , 而会先写入内存然后同步到各个分片,故我们需要向每个分片的物理表同时写入数据。
综上, 目前round和roundData数据量越来越大 ,搭建集群分布式存储数据方案是可行的。


上篇:
基于Flink+ClickHouse打造轻量级点击流实时数仓
下篇:
ELK-安装ELK7.6.2和UI管理界面及测试案例