2023/10 作者:ihunter 0 次 0
# SeaTunnel 介绍
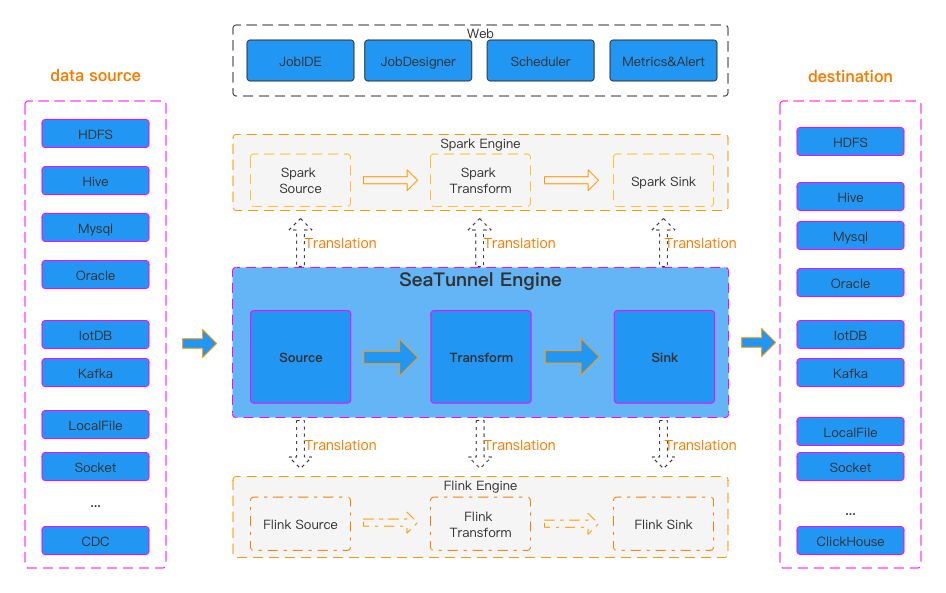
Apache SeaTunnel 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台。架构于Apache Spark 和 Apache Flink之上
# SeaTunnel 的作用
SeaTunnel专注于数据集成和数据同步,主要针对解决数据集成领域的常见问题:
各种数据源:有数百个常用数据源,其版本不兼容。随着新技术的出现,更多的数据源正在出现。用户很难找到能够完全快速支持这些数据源的工具。
复杂同步场景:数据同步需要支持离线-全量同步、离线-增量同步、CDC、实时同步、数据库全量同步等多种同步场景。
资源需求高:现有的数据集成和数据同步工具往往需要大量的计算资源或JDBC连接资源来完成海量小表的实时同步。这在一定程度上加重了企业的负担。
缺乏质量和监控:数据集成和同步过程经常会遇到数据丢失或重复的情况。同步过程缺乏监控,无法直观地了解任务过程中数据的真实情况。
复杂的技术栈:企业使用的技术组件不同,用户需要针对不同的组件开发相应的同步程序来完成数据集成。
管理和维护难度大:受限于不同的底层技术组件(Flink/Spark),离线同步和实时同步往往分开开发和管理,增加了管理和维护的难度。
# SeaTunnel 的特点
丰富且可扩展的连接器:SeaTunnel 提供了一个不依赖于特定执行引擎的连接器 API。基于此 API 开发的连接器(源、转换、接收器)可以在许多不同的引擎上运行,例如当前支持的 SeaTunnel 引擎、Flink、Spark。
连接器插件:插件设计允许用户轻松开发自己的连接器并将其集成到 SeaTunnel 项目中。目前,SeaTunnel已经支持100多个连接器,而且数量还在激增。有列表 当前支持的连接器
批量流集成:基于 SeaTunnel 连接器API开发的连接器,完美兼容离线同步、实时同步、全同步、增量同步等场景。它大大降低了管理数据集成任务的难度。
支持分布式快照算法,保证数据一致性。
多引擎支持:SeaTunnel 默认使用 SeaTunnel 引擎进行数据同步。同时,SeaTunnel 还支持使用 Flink 或 Spark 作为连接器的执行引擎,以适应企业现有的技术组件。SeaTunnel 支持多个版本的 Spark 和 Flink。
JDBC多路复用,数据库日志多表解析:SeaTunnel支持多表或全数据库同步,解决了JDBC连接过多的问题;支持多表或全库日志读写解析,解决了CDC多表同步场景重复读取解析日志的问题。
高吞吐、低时延:SeaTunnel 支持并行读写,提供稳定可靠的数据同步能力,高吞吐、低时延。
完善的实时监控:SeaTunnel支持数据同步过程中每个步骤的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS等信息。
# Seatunnel 优势与缺点
优势
简单易用,灵活配置,无需开发
模块化和插件化
支持利用SQL做数据处理和聚合
由于其高度封装的计算引擎架构,可以很好的与中台进行融合,对外提供分布式计算能力
缺点
Spark支持2.2.0 - 2.4.8,不支持spark3.x
Flink支持1.9.0,目前flink已经迭代至1.14.x,无法向上兼容
Spark作业虽然可以很快配置,但相关人员还需要懂一些参数的调优才能让作业效率更优
# 核心理念
SeaTunnel 设计的核心是利用设计模式中的“控制翻转”或者叫“依赖注入”,主要概括为以下两点:
1)上层不依赖底层,两者都依赖抽象;
2)流程代码与业务逻辑应该分离。整个数据处理过程,大致可以分为以下几个流程:输入 -> 转换 -> 输出,对于更复杂的数据处理,实质上也是这几种行为的组合:

# 什么是数据集成?
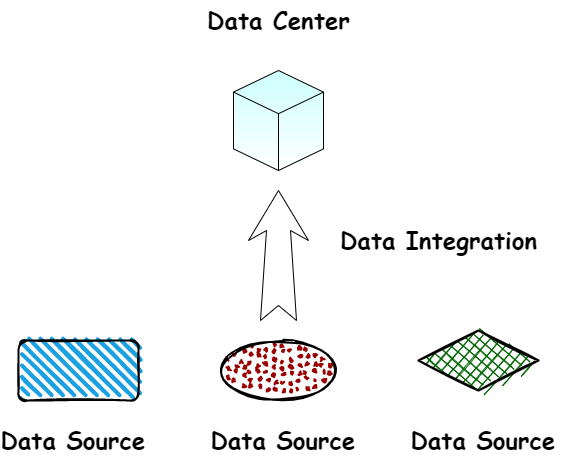
数据集成是指将来自不同数据源的数据整合到一起形成一个统一的数据集。这个过程包括从不同的数据源中收集数据,对数据进行清洗、转换、重构和整合,以便能够在一个统一的数据仓库或数据湖中进行存储和管理。
数据集成可以帮助企业更好地理解和利用他们的数据,并促进数据驱动的决策和业务流程优化。在数据集成过程中,需要考虑数据质量、数据安全性、数据格式、数据结构等方面的问题,并采用适当的技术和工具来解决这些问题,例如 ETL(抽取、转换、加载)工具、数据映射工具、数据清洗工具、数据建模工具等。
一般数据集成用到的工具主要有:Sqoop、DataX、或是本章讲解的 SeaTunnel,这三个工具都是数据转换集成工具,使用其中一个即可,其实也可以这样认为 Sqoop 是第一代,DataX 是第二代,SeaTunnel 是第三代工具,Sqoop 用的不是很多了,Datax 应该用的还是比较多的,SeaTunnel 是 Apache 顶级项目,也是最新代的数据集成工具
# ETL 又是什么?
前面的文章其实讲过 ETL,这里只是再次回顾以下,ETL 中的 E 是extract,数据抽取;T 是 Transform,代表数据的转换;L 代表Load,数据加载。


上篇:
基于MinIO/Deleta Lake/Dremio和Superset或Metabase搭建简单的数据湖
下篇:
通义千问-14B - 140亿参数规模的模型 - 基于Transformer的大语言模型



