2018/07 作者:ihunter 0 次 0
一、架构变化
1、Hadoop 2.0由HDFS、MapReduce和YARN三个分支构成
2、HDFSNN Federation、HA
3、MapReduce运行在YARN上的MR
4、YARN资源管理系统
二、HDFS 2.0
1、解决HDFS 1.0中单点故障和内存受限问题。
2、解决单点故障
HDFS HA通过主备NameNode解决
如果主NameNode发生故障则切换到备NameNode上
3、解决内存受限问题
HDFS Federation(联邦)
水平扩展支持多个NameNode
每个NameNode分管一部分目录
所有NameNode共享所有DataNode存储资
4、仅是架构上发生了变化使用方式不变
对HDFS使用者透明
HDFS 1.0中的命令和API仍可以使用$ hadoop fs -ls /user/hadoop/$ hadoop fs -mkdir /user/hadoop/data
三、HDFS 2.0 HA
1、主备NameNode
2、解决单点故障
主NameNode对外提供服务备NameNode同步主NameNode元数据以待切换
所有DataNode同时向两个NameNode汇报数据块信息
3、两种切换选择
手动切换通过命令实现主备之间的切换可以用HDFS升级等场合
自动切换基于Zookeeper实现
4、基于Zookeeper自动切换方案
Zookeeper Failover Controller监控NameNode健康状态并向Zookeeper注册NameNode
NameNode挂掉后ZKFC为NameNode竞争锁获得ZKFC 锁的NameNode变为active
四、环境搭建
192.168.1.2 master
192.168.1.3 slave1
192.168.1.4 slave2
Hadoop versionhadoop-2.2.0.tar.gz
Hbase versionhbase-0.98.11-hadoop2-bin.tar.gz
Zookeeper versionzookeeper-3.4.5.tar.gz
JDK versionjdk-7u25-linux-x64.gz
1、主机HOSTS文件配置
1 2 3 4 5 6 7 8 9 10 11 12 | [root@master ~]# cat /etc/hosts192.168.1.2 master192.168.1.3 slave1192.168.1.4 slave2[root@slave1 ~]# cat /etc/hosts192.168.1.2 master192.168.1.3 slave1192.168.1.4 slave2[root@slave2 ~]# cat /etc/hosts192.168.1.2 master192.168.1.3 slave1192.168.1.4 slave2 |
2、配置节点之间互信
1 2 3 4 5 6 7 8 9 10 | [root@master ~]# useradd hadoop[root@slave1 ~]# useradd hadoop[root@slave2 ~]# useradd hadoop[root@master ~]# passwd hadoop[root@slave1 ~]# passwd hadoop[root@slave2 ~]# passwd hadoop[root@master ~]# su - hadoop[hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave1[hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave2[hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub master |
3、JDK环境配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | [root@master ~]# tar jdk-7u25-linux-x64.gz[root@master ~]# mkdir /usr/java[root@master ~]# mv jdk-7u25-linux-x64.gz /usr/java[root@master ~]# cd /usr/java/[root@master java]# ln -s jdk1.7.0_25 jdk# 修改/etc/profile,添加export JAVA_HOME=/usr/java/jdkexport CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/libexport PATH=/usr/java/jdk/bin:$PATH[root@master ~]# source /etc/profile[root@master ~]# java -versionjava version "1.7.0_25"Java(TM) SE Runtime Environment (build 1.7.0_25-b15)Java HotSpot(TM) 64-Bit Server VM (build 23.25-b01, mixed mode)# slave1,slave2同样操作 |
4.Hadoop安装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 | [root@master ~]# tar zxvf hadoop-2.2.0.tar.gz[root@master ~]# mv hadoop-2.2.0 /home/hadoop/[root@master ~]# cd /home/hadoop/[root@master hadoop]# ln -s hadoop-2.2.0 hadoop[root@master hadoop]# chown -R hadoop.hadoop /home/hadoop/[root@master ~]# cd /home/hadoop/hadoop/etc/hadoop# 修改hadoop-env.sh文件export JAVA_HOME=/usr/java/jdkexport HADOOP_HEAPSIZE=200# 修改mapred-env.sh文件export JAVA_HOME=/usr/java/jdkexport HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000# 修改yarn-env.sh文件export JAVA_HOME=/usr/java/jdkJAVA_HEAP_MAX=-Xmx300mYARN_HEAPSIZE=100# 修改core-site.xml文件 /name> //master:9000</value> </property> dir</name> /home/hadoop/tmp</value> </property> /name> /value> </property> groups</name> /value> </property></configuration># 修改hdfs-site.xml文件 /name> /value> </property> dir</name> /home/hadoop/dfs/name</value> </property> dir</name> /home/hadoop/dfs/data</value> </property> /name> /value> </property> /name> true</value> </property></configuration># 修改mapred-site.xml文件 /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property></configuration># 修改yarn-site.xml文件 /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property> /name> /value> </property></configuration># 修改slaves文件slave1slave2# 修改 /home/hadoop/.bashrcexport HADOOP_DEV_HOME=/home/hadoop/hadoopexport PATH=$PATH:$HADOOP_DEV_HOME/binexport PATH=$PATH:$HADOOP_DEV_HOME/sbinexport HADOOP_MAPARED_HOME=${HADOOP_DEV_HOME}export HADOOP_COMMON_HOME=${HADOOP_DEV_HOME}export HADOOP_HDFS_HOME=${HADOOP_DEV_HOME}export YARN_HOME=${HADOOP_DEV_HOME}export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoopexport HDFS_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoopexport YARN_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop# 将上面修改的文件全部传送到slave1,slave2节点 |
5、在master节点上启动hdfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | [hadoop@master ~]$ cd /home/hadoop/hadoop/sbin/[hadoop@master sbin]$ ./start-dfs.sh 15/03/21 00:49:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableStarting namenodes on [master]master: starting namenode, logging to /home/hadoop/hadoop-2.2.0/logs/hadoop-hadoop-namenode-master.outslave2: starting datanode, logging to /home/hadoop/hadoop-2.2.0/logs/hadoop-hadoop-datanode-slave2.outslave1: starting datanode, logging to /home/hadoop/hadoop-2.2.0/logs/hadoop-hadoop-datanode-slave1.outStarting secondary namenodes [master]master: starting secondarynamenode, logging to /home/hadoop/hadoop-2.2.0/logs/hadoop-hadoop-secondarynamenode-master.out# 查看进程[hadoop@master ~]$ jps39093 Jps38917 SecondaryNameNode38767 NameNode[root@slave1 ~]# jps2463 Jps2379 DataNode[root@slave2 ~]# jps2463 Jps2379 DataNode#启动jobhistory[hadoop@master sbin]$ mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /home/hadoop/hadoop-2.2.0/logs/mapred-hadoop-historyserver-master.out |
6、启动yarn
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | [hadoop@master ~]$ cd /home/hadoop/hadoop/sbin/[hadoop@master sbin]$ ./start-yarn.sh starting yarn daemonsstarting resourcemanager, logging to /home/hadoop/hadoop-2.2.0/logs/yarn-hadoop-resourcemanager-master.outslave2: starting nodemanager, logging to /home/hadoop/hadoop-2.2.0/logs/yarn-hadoop-nodemanager-slave2.outslave1: starting nodemanager, logging to /home/hadoop/hadoop-2.2.0/logs/yarn-hadoop-nodemanager-slave1.out# 查看进程[hadoop@master sbin]$ jps39390 Jps38917 SecondaryNameNode39147 ResourceManager38767 NameNode[hadoop@slave1 ~]$ jps2646 Jps2535 NodeManager2379 DataNode[hadoop@slave2 ~]$ jps8261 Jps8150 NodeManager8004 DataNode |
7、查看hdfs文件系统
1 2 3 4 5 | [hadoop@master sbin]$ hadoop fs -ls /15/03/21 15:56:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableFound 2 itemsdrwxr-xr-x - hadoop supergroup 0 2015-03-20 17:46 /hbasedrwxrwx--- - hadoop supergroup 0 2015-03-20 16:56 /tmp |
8、安装Zookeeper
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | [root@master ~]# tar zxvf zookeeper-3.4.5.tar.gz -C /home/hadoop/[root@master ~]# cd /home/hadoop/[root@master hadoop]# ln -s zookeeper-3.4.5 zookeeper[root@master hadoop]# chown -R hadoop.hadoop /home/hadoop/zookeeper[root@master hadoop]# cd zookeeper/conf/[root@master conf]# cp zoo_sample.cfg zoo.cfg# 修改zoo.cfgdataDir=/home/hadoop/zookeeper/datadataLogDir=/home/hadoop/zookeeper/logsserver.1=192.168.1.2:7000:7001server.2=192.168.1.3:7000:7001server.3=192.168.1.4:7000:7001#在slave1,slave2执行相同的操作[hadoop@master conf]# cd /home/hadoop/zookeeper/data/[hadoop@master data]# echo 1 > myid [hadoop@slave1 data]# echo 2 > myid [hadoop@slave2 data]# echo 3 > myid #启动zookeeper[hadoop@master ~]$ cd zookeeper/bin/[hadoop@master bin]$ ./zkServer.sh start[hadoop@slave1 ~]$ cd zookeeper/bin/[hadoop@slave1 bin]$ ./zkServer.sh start[hadoop@slave2 ~]$ cd zookeeper/bin/[hadoop@slave2 bin]$ ./zkServer.sh start |
9、Hbase安装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | [root@master ~]# tar zxvf hbase-0.98.11-hadoop2-bin.tar.gz -C /home/hadoop/[root@master ~]# cd /home/hadoop/[root@master hadoop]# ln -s hbase-0.98.11-hadoop2 hbase[root@master hadoop]# chown -R hadoop.hadoop /home/hadoop/hbase[root@master hadoop]# cd /home/hadoop/hbase/conf/# 修改hbase-env.sh文件export JAVA_HOME=/usr/java/jdkexport HBASE_HEAPSIZE=50# 修改 hbase-site.xml 文件 /name> //master:9000/hbase</value> </property> /name> true</value> </property> /name> /value> </property> /name> /value> </property></configuration># 修改regionservers文件slave1slave2# 将上面修改的文件传送到slave1,slave2 |
10、在master上面启动Hbase
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | [hadoop@master ~]$ cd hbase/bin/[hadoop@master bin]$ ./start-hbase.sh master: starting zookeeper, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-zookeeper-master.outslave1: starting zookeeper, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-zookeeper-slave1.outslave2: starting zookeeper, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-zookeeper-slave2.outstarting master, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-master-master.outslave1: starting regionserver, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-regionserver-slave1.outslave2: starting regionserver, logging to /home/hadoop/hbase/bin/../logs/hbase-hadoop-regionserver-slave2.out# 查看进程[hadoop@master bin]$ jps39532 QuorumPeerMain38917 SecondaryNameNode39147 ResourceManager39918 HMaster38767 NameNode40027 Jps[hadoop@slave1 data]$ jps3021 HRegionServer3133 Jps2535 NodeManager2379 DataNode2942 HQuorumPeer[hadoop@slave2 ~]$ jps8430 HRegionServer8351 HQuorumPeer8150 NodeManager8558 Jps8004 DataNode# 验证[hadoop@master bin]$ ./hbase shell2015-03-21 16:11:44,534 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.availableHBase Shell; enter 'help for list of supported commands.Type "exit to leave the HBase ShellVersion 0.98.11-hadoop2, r6e6cf74c1161035545d95921816121eb3a516fe0, Tue Mar 3 00:23:49 PST 2015hbase(main):001:0> listTABLE SLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/home/hadoop/hbase-0.98.11-hadoop2/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-2.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.2015-03-21 16:11:56,499 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable0 row(s) in 1.9010 seconds=> [] |
11、查看集群状态
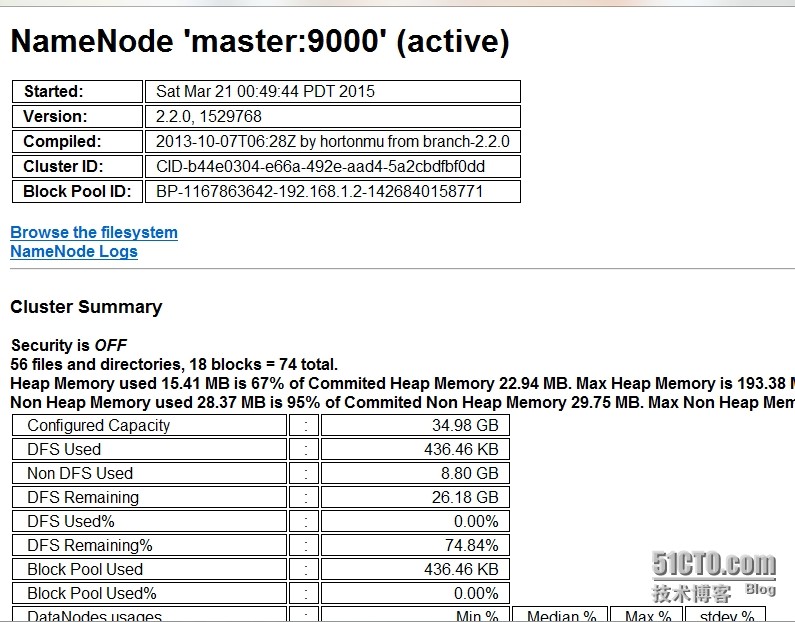
HDFS UIhttp://192.168.1.2:50070/dfshealth.jsp
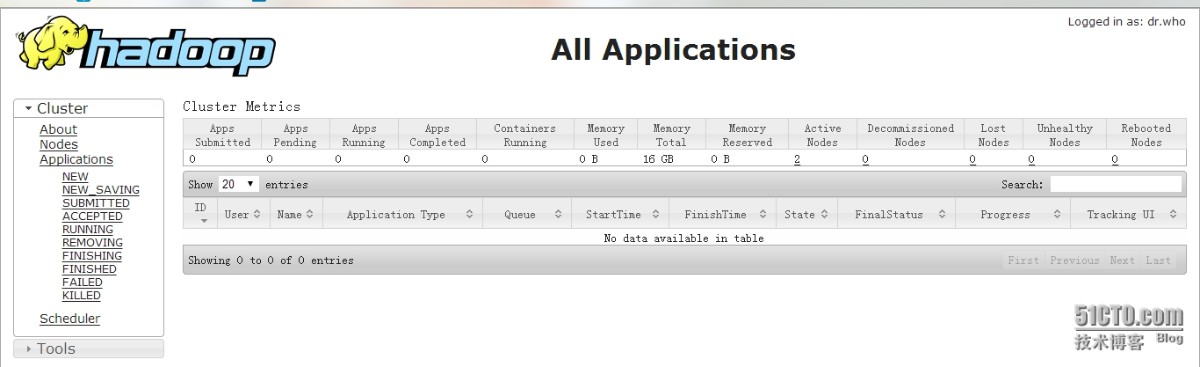
YARN UIhttp://192.168.1.2:8088/cluster
jobhistory UIhttp://192.168.1.2:19888/jobhistory

HBASE UIhttp://192.168.1.2:60010/master-status



上篇:
CentOS 7.2 安装Zabbix3.X
下篇:
LVS+keepalived+nginx+tomcat部署实现